Generalized Linear Model (GLM)
- This is a whole area in regression and we could spend a full
semester on this topic. Today’s goal is a crash course on the basics of
the most common type of GLM used, the logistic regression
- So far you have been using a special case of the GLM, where we
assume the underlying assumption is a Gaussian distribution
- Now we will expand out the examine the whole family
- When you run a GLM, you need to state “family” and the “linking”
function you will use
Family and Link
- Linear regression assumes that DV = \(\mu\) and SD = \(\sigma\) and the possible range of
responses is from \(-\infty,\infty\)
- But GLM will allow us to examine categorical responses (2 or more
responses), and you cannot satisfy the same requirements as linear
regression (you cannot have \(-\infty,\infty\) response range)
- Some of the other distributions, like binomial (2 responses) or
Poisson (multiple responses) can approximate normal when
transformed
- We need to “link” the mean of DV to the linear term of the model
(think transform) to make it meet our regression requirements
- Here are the most common families used in psychology
| Gaussian |
Gaussian |
identity |
| binomial |
binomial |
logit/Probit |
| Poisson |
Poisson |
log |
Linear regression on binomial DV
- Let’s simulate what happens when we analyze binomial DV as it
were a plain old regression
- What is we wanted to predict who is a hipster based on specific
features of their appearance and attitude.
- Simulate a model Hipster (DV: 0 = Not a Hipster, 1 = Hipster) based
on the Use of Irony (IV = -3 to 3) and Ridiculousness of transportation
(IV = -3 to 3)
- The goal is to predict Hipster status
- Below is the simulation and we will run a linear
regression.
- First a raw data plot (show the predictors one a time)!
library(ggplot2)
set.seed(42)
n=30
x = runif(n,-3,3) # Ridiculousness of transportation [-3 normal, 3 = uni-cycles]
j = runif(n,-3,3) # Irony usage [-3 never, 3 = All the time]
z = .8*x + .2*j
pr = 1/(1+exp(-z)) # pass through an inv-logit function
y = rbinom(n,1,pr) # response variable
# Build data frame
LogisticStudy1= data.frame(Hipster=y,Transport=x, Irony=j)
ggplot(LogisticStudy1, aes(x=Transport, y=Hipster)) + geom_point() +
stat_smooth(method="lm", formula=y~x, se=FALSE)+
theme_classic()
ggplot(LogisticStudy1, aes(x=Irony, y=Hipster)) + geom_point() +
stat_smooth(method="lm", formula=y~x, se=FALSE)+
theme_classic()
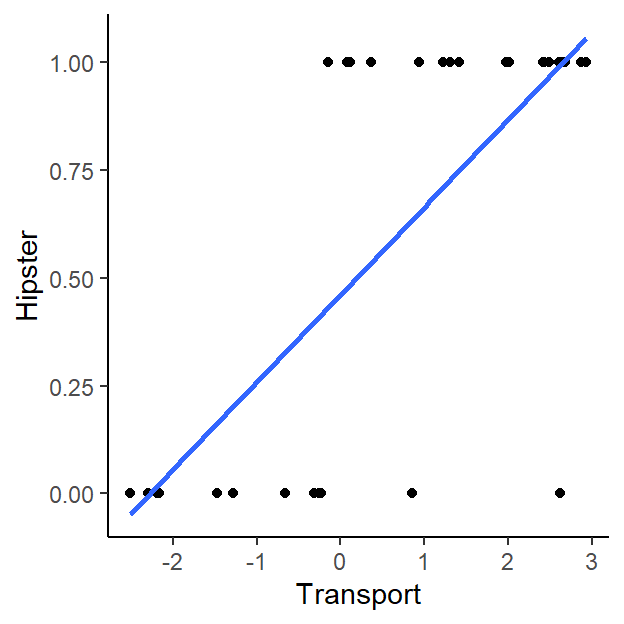
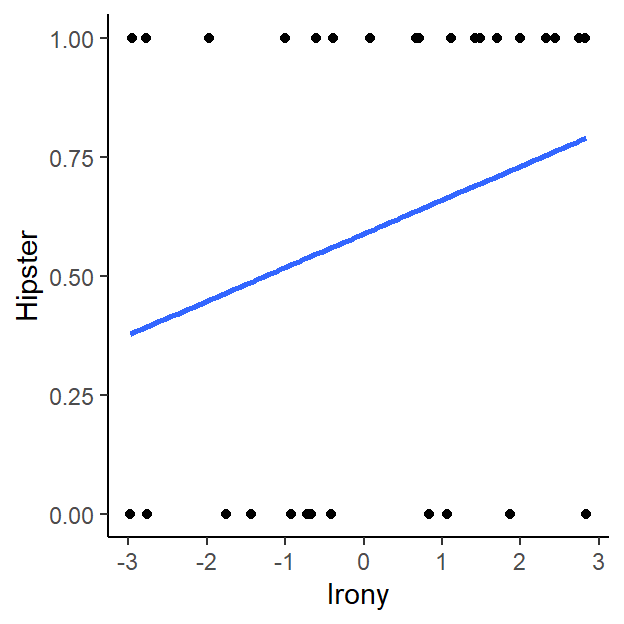 - Note in the graphs, all your DVs are at the top and bottom of the
graph. - What does that best fit line mean?
- Note in the graphs, all your DVs are at the top and bottom of the
graph. - What does that best fit line mean?
- Let’s run our muliple regression:
Hipster~ Transport + Irony
LM.1<-lm(Hipster~Transport+Irony,data=LogisticStudy1)
- Using
sjPlot (which is like effects package merged into
ggplot) we can plot the results
library(sjPlot)
plot_model(LM.1, type = "eff", axis.lim=c(-.25,1.25),
terms=c("Transport"))+theme_sjplot2()
plot_model(LM.1, type = "eff",axis.lim=c(-.25,1.25),
terms=c("Irony"))+theme_sjplot2()
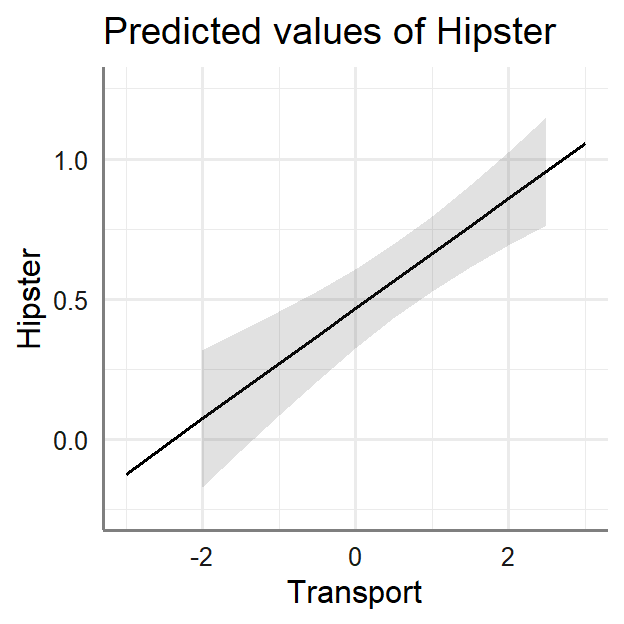
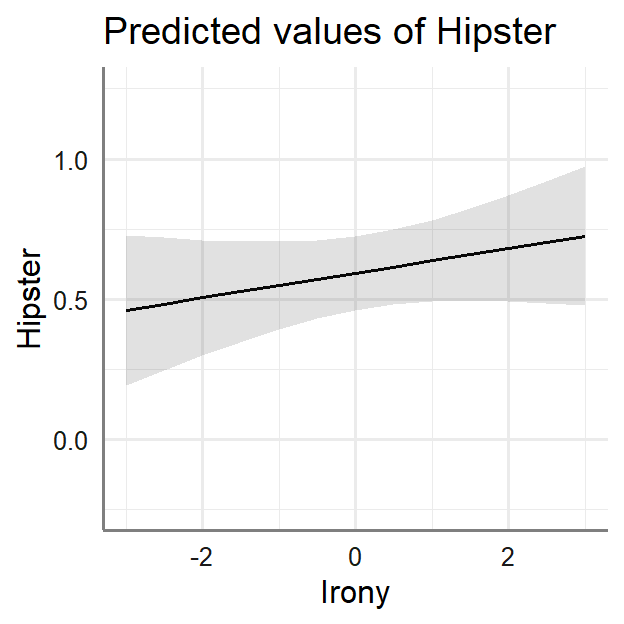
|
|
|
|
Dependent variable:
|
|
|
|
|
|
Hipster
|
|
|
LM
|
|
|
|
Constant
|
0.459*** (0.069)
|
|
Transport
|
0.196*** (0.038)
|
|
Irony
|
0.044 (0.036)
|
|
|
|
Observations
|
30
|
|
R2
|
0.536
|
|
Adjusted R2
|
0.501
|
|
F Statistic
|
15.579*** (df = 2; 27)
|
|
|
|
Note:
|
p<0.05; p<0.01;
p<0.001
|
- The intercept reflects the mean Hipster at the mean
of the IVs
- The slope of Transport says as weirder their
Transport gets the more likely the person is a hipster
- The slope of Irony says as the person uses more
irony the more likely the person is a hipster (but it’s not
significant)
- How do the residuals look?
plot_model(LM.1, type = "diag")[4]
## [[1]]
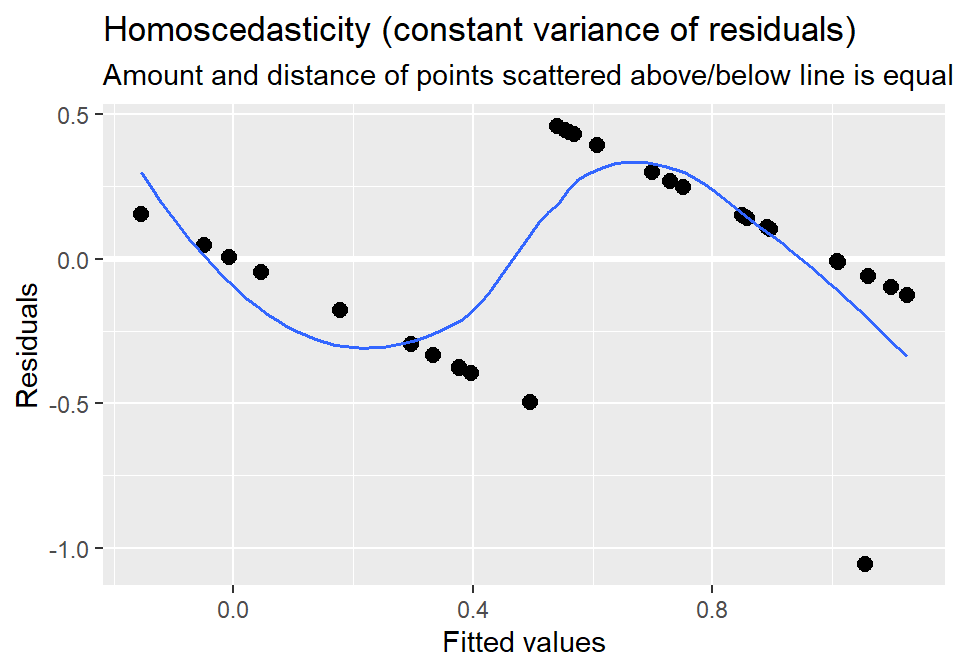
- That looks really odd because the fitted (predict values) are
continuous, but the response is binomial
- Let’s see how well we predicted (fit) our result for each
individual:
- Remember to make a “prediction” we solve the regression equations
for each subjects IVs the DV (Hipster)
LogisticStudy1$Predicted.Value<-predict(LM.1)
summary(LogisticStudy1$Predicted.Value)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -0.1545 0.3766 0.5883 0.6000 0.8825 1.1243
- Yikes! The model predicted a value outside the range of possible
values (value above 1)
- Let’s say any prediction > .5 = Hipster and below that is Not
Hipster
- Then we will examine a contingency table (predict results to true
results)
LogisticStudy1$Predicted.Hipster<-ifelse(LogisticStudy1$Predicted.Value > .5,1,0)
C.Table<-with(LogisticStudy1,
table(Predicted.Hipster, Hipster))
C.Table
## Hipster
## Predicted.Hipster 0 1
## 0 11 0
## 1 1 18
- Correct predict is [0 & 0] and [1 & 1], bad prediction are
mismatches
- To get an accurancy score: [11 + 18 ]/ 30 X 100
PercentPredicted<-(C.Table[1,1]+C.Table[2,2])/sum(C.Table)*100
Yields Accuracy = 96.6666667%
So the model did a good job making the prediction in this simple
case, but the \(R^2\) has no meaning
(what variability of Hipster is it explaining?)
Summary

Using linear regression on this data produced odd predictions outside
of the bounded range, violation of homoscedasticity, and an \(R^2\) which makes no sense. Instead, let’s
try a GLM, but first let’s understand the binomial distribution and
logit link function.
Logistic Regression
- Logistic regression is that we call the regression where we analyze
binomial DV
Binomial Distribution
- Binomial can be expressed as follows: \[p(n|N) =
(\frac{N}{n})p^n(1-p^{N-n})\]
- where \(n\) = successes in \(N\) trials, at a specific \(p\) probability
- These change as function of the underlying probability of getting a
0 or 1
- The plot below has \(N=10\) people
making 1 response each, with probability changing from 0 to 1 by
.25
par(mfrow=c(1, 5))
for(p in seq(0, 1, len=5))
{
x <- dbinom(0:10, size=10, p=p)
barplot(x, names.arg=0:10, space=0)
}
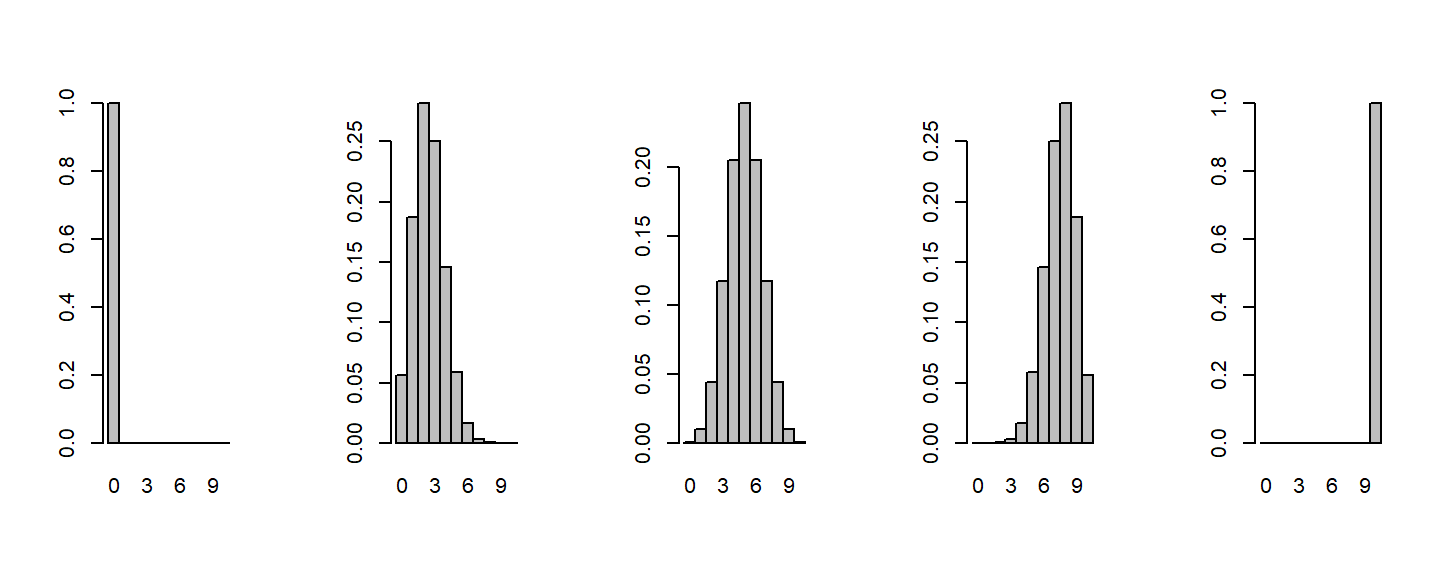
- As the number of people increases, you will notice it looks normal,
here is 100 responses
par(mfrow=c(1, 5))
for(p in seq(0, 1, len=5))
{
x <- dbinom(0:100, size=100, p=p)
barplot(x, names.arg=0:100, space=0)
}
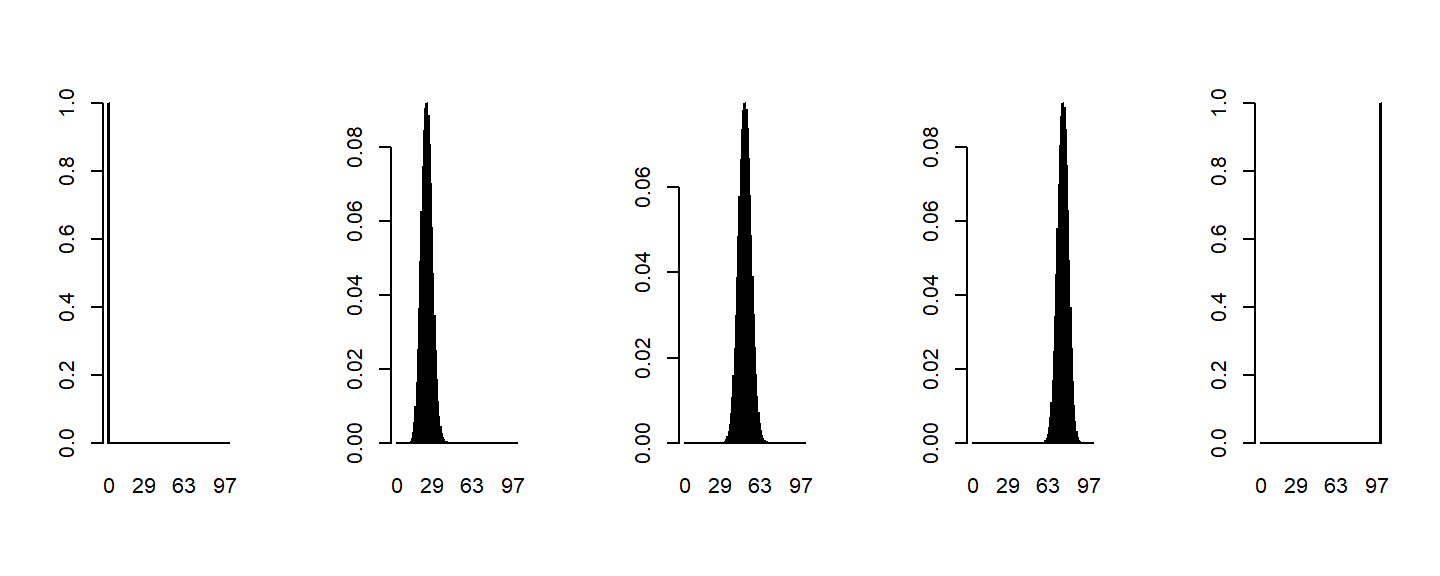
Logit Linking Function
- We can bound our results making our best fit line
asymptotic to the boundary conditions
- To make this work, we need to switch from straight
lines to the sigmoid
- Remember regression wants the DV to be between \(-\infty,\infty\), so have will have to
apply a the logit transform
\[Logit = log\frac{p}{1-p}\]
- Note: I will use Log for the Natural Log to be
consistent with R (but in other places, you might see natural log as
LN)
logit.Transform<-function(p) {log(p/(1-p)) }
plot(logit.Transform(seq(0,1,.0001)),seq(0,1,.0001),
main="Logit Transform",ylim = c(0,1),
xlab="Logit",ylab="Probability")
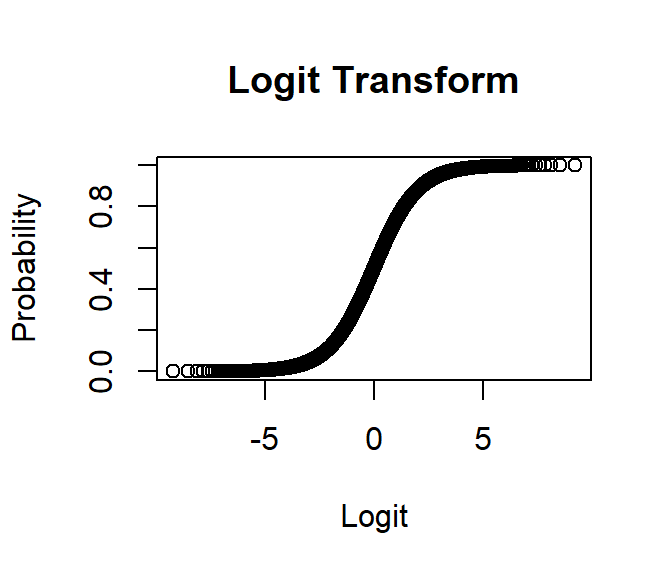
- You can see the sigmoid is asymptotic to the boundary
conditions of 0 and 1 probability!
Fit the logistic regression
- \(logit(Hipster) = B_1(Transport)
+B_2(Irony) + B_0\)
- This can be accomplished by changing the function in R to
glm from lm and specifying the
family as binomial(link = “logit”)
- First let’s plot and then make sense of the parameters
afterwards
LR.1<-glm(Hipster~Transport+Irony,data=LogisticStudy1, family=binomial(link = "logit"))
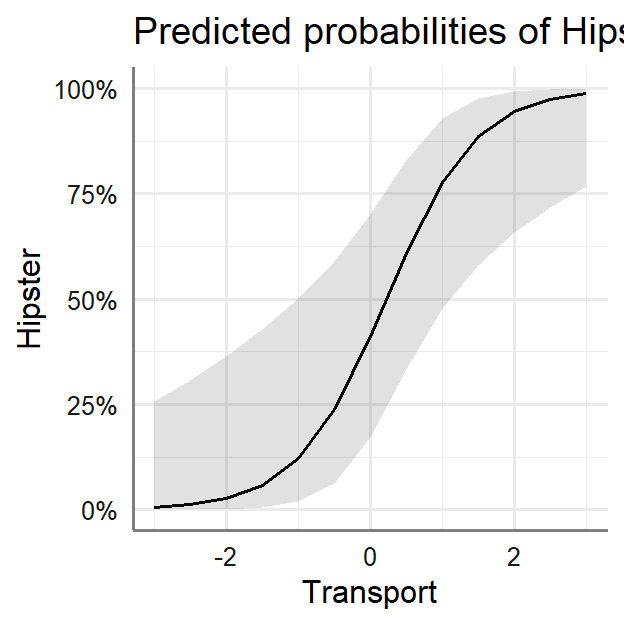
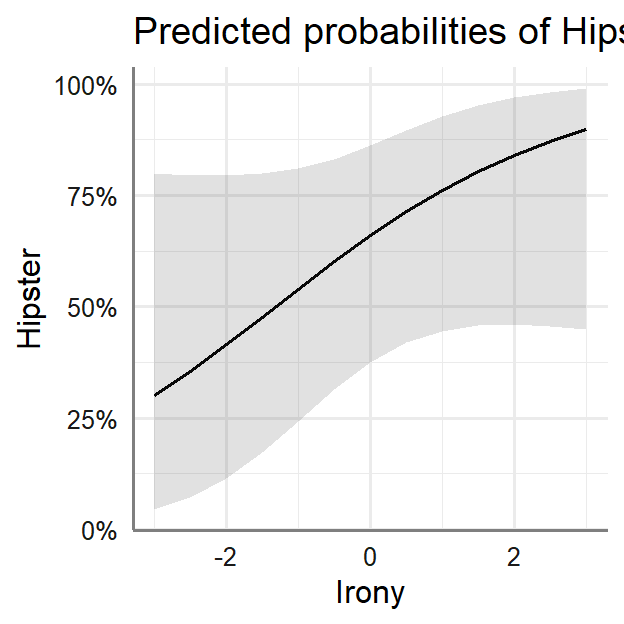
Plot in probabilities
- Y-axis = Predicted probability of Hipster as a function of Transport
weirdness or Use of Irony
- Using
sjPlot (which is like effects package merged into
ggplot) we can now see
library(sjPlot)
plot_model(LR.1, type = "eff",
terms=c("Transport"))+theme_sjplot2()
plot_model(LR.1, type = "eff",
terms=c("Irony"))+theme_sjplot2()
Interpret coefficients
- Raw coefficients are transformed and this hard to makes sense
of
- So we can transform them back to something meaningful; odd ratios or
probabilities
- Odds ratio = success is defined as the ratio of the probability of
success over the probability of failure
- 50% chance = odds ratio of 1 (1:1 ratio)

|
|
|
|
Dependent variable:
|
|
|
|
|
|
Hipster
|
|
|
Logistic
|
|
|
|
Constant
|
-0.441 (0.629)
|
|
Transport
|
1.610** (0.600)
|
|
Irony
|
0.502 (0.338)
|
|
|
|
Observations
|
30
|
|
Log Likelihood
|
-9.654
|
|
Akaike Inf. Crit.
|
25.308
|
|
|
|
Note:
|
p<0.05; p<0.01;
p<0.001
|
\[Odds = e^{logit(x)}\]
L.to.O.Transform<-function(p) {exp(logit.Transform(p))}
plot((logit.Transform(seq(0,.99,.01))),L.to.O.Transform(seq(0,.99,.01)),
main="Logit to Odds Transform",
xlab="Logit",ylab="Odds")
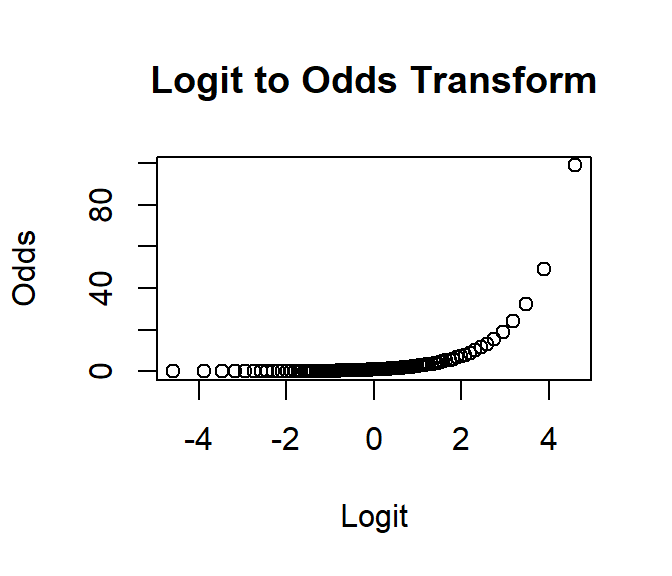 - here are our regression estimates as odds ratio
- here are our regression estimates as odds ratio
LR.1.Trans <- coef(summary(LR.1))
LR.1.Trans[, "Estimate"] <- exp(coef(LR.1))
| (Intercept) |
0.6435201 |
0.6288280 |
-0.7009898 |
0.4833094 |
| Transport |
5.0014129 |
0.5995236 |
2.6849992 |
0.0072530 |
| Irony |
1.6524682 |
0.3375908 |
1.4878075 |
0.1368017 |
or you can use the sjplot package
# tab_model(LR.1,
# show.se = TRUE,show.aic = TRUE, show.loglik=TRUE,show.ci = FALSE)
- MDs talk in odds, but psychologists sometime prefer probabilities
\[P = \frac{Odds} {1 + Odds}\]
O.to.P.Transform<-function(p) {L.to.O.Transform(p)/(1+L.to.O.Transform(p))}
plot(L.to.O.Transform(seq(0,.94,.01)),O.to.P.Transform(seq(0,.94,.01)),
main="Odds to Probablity Transform",
xlab="Odds",ylab="Probablity")
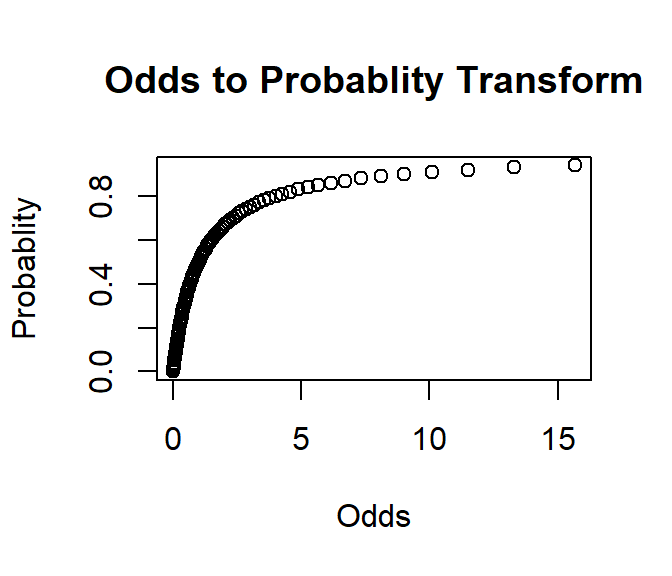
- So we can convert our regression equation to give our probabilities
directly
\[p_{(Hipster)}
=\frac{e^{(B_1(Transport)+B_2(Irony) +
B_0})}{1+e^{(B_1(Transport)+B_2(Irony) + B_0})}\]
\[p_{(Hipster)}
=\frac{1}{1+e^{-(B_1(Transport)+B_2(Irony) + B_0})}\]
LR.1.TransP <- coef(summary(LR.1))
LR.1.TransP[, "Estimate"] <- exp(coef(LR.1))/(1+exp(coef(LR.1)))
| (Intercept) |
0.3915499 |
0.6288280 |
-0.7009898 |
0.4833094 |
| Transport |
0.8333726 |
0.5995236 |
2.6849992 |
0.0072530 |
| Irony |
0.6229927 |
0.3375908 |
1.4878075 |
0.1368017 |
Note: These probabilities are like the odds ratio. They represent how
much more likely the results between the levels of the predictors. They
do not tell you the likelihood of being a hipster. For that you must
solve the equitation as I showed above. Also you can use effects or
sjplot package to plot the results in predicted probabilities.
What to report
- However, you have to report the raw values that come from the
logistic regression [or report them in Odds ratios]
- This is because your units are raw (centered) units and if you used
this table you would need to figure out how to convert all your IV units
- Thus, you would simply use the equations above when you add up your
predictors
- So just like in linear regression you would add your predictor
estimates (let’s say if you have nominal variables and interactions) and
then convert them as above
Wait!! What about my R-squared?
- \(R^2\) has no meaning has no
meaning in these models
- They do not measure the amount of variance accounted
for
- Binominal data cannot be homoscedastic, in fact, you could see there
is no spread of data around the line, and also the variance at each
value may not be same
- Over the years people have created different types of pseudo-\(R^2\) in which to try to make linear
regression types of understanding
- Each of them tries to capture something like our original \(R^2\), such as (A) explaining variability,
(B) model improvement such as \(change in
R^2\) between models, (C) and finally as a measure of
multiple-correlation
- Many of these between testing between a restricted model (Null
model) and your model, so first we need to examine model fitting for
GLMs
Deviance Testing
- In linear regression, OLS was the fitting procedure, and it worked
because OLS can find mean and variance of the normal distribution, but
now we are not working with normal distributions, so we need a new
fitting procedure
- In our OLS regression we had this concept: \[SS_{Resid} = SS_Y - SS_{Regression}\]
- In other words, residual = Actual - Fitted values
- in OLS, we can get the best fit analytically (solving an
equation), but with GLM you cannot do that!
- For GLM, We can calculate the deviance of scores, which is
built on the idea of maximum likelihood
- We iterate a solution (since we cannot solve it without
trial and error)
- We need to find the likelihood; which is “a hypothetical probability
that an event that has already occurred would yield a
specific outcome” (http://mathworld.wolfram.com/Likelihood.html)
- We will iterate through parameters until we maximize our likelihood
(called maximal likelihood estimation)
- There are different ML (or just L) functions that can be used and
they can apply to most distributions
- When the fit is perfect, \[L_{perfect} =
1\]
- The null case (starting model) that ONLY has an intercept, this will
probably yield the lowest likelihood
- Our test model will be intercept + predictors (parameters - k)
\[Likelihood ratio
=\frac{L_{Simple}}{L_{Complex}}\]
Deviance this is the \(-2*\)
natural logLikelihood ratio \[D =
2*log(Likelihood ratio)\] AKA \[D =
-2LL\] First, I will show you the pseudo-\(R^2\) and then we will examine how to test
between model fits
Null Deviance \[D_{Null} =
-2[log(L_{Null}) - log(L_{Perfect})]\]
Model Deviance \[D_{K} = -2[log(L_{K}
- log(L_{Perfect})]\]
This is like our SS residual from OLS
Pseudo-R-sqaured
- We need those crazy Devience scores for some of our pseudo-\(R^2\) measurements, for example: \[R_L^2 = \frac{D_{Null}
-D_{k}}{D_{Null}}\]
- Cox and Snell is what SPSS gives and people report it often
- Nagelkerke is an improvement (C&S) as it corrects some
problems
- But people like McFadden’s cause its easy to understand
\[R_{McFadden}^2 = 1 -
\frac{LL_{k}}{LL_{Null}}\]
- We can just get them from the
pscl package
- llh = log-likelihood from the fitted model (llk above)
- llhNull = The log-likelihood from the intercept-only restricted
model
- \(G^2 = -2(LL_{K} - LL_{NULL})\) is
a one of the proposed goodness of fit measures (we will come back to
this later)
- McFadden = McFadden pseudo-\(R^2\)
- r2ML = Cox & Snell pseudo-\(R^2\)
- r2CU = Nagelkerke pseudo-\(R^2\)
library(pscl)
pR2(LR.1)
## fitting null model for pseudo-r2
## llh llhNull G2 McFadden r2ML r2CU
## -9.6542125 -20.1903500 21.0722750 0.5218403 0.5046096 0.6821567
Wait why I do see Z and not t-values?
- When testing individual predictors, you do not see t-tests you are
looking at Wald Z-scores
- Some argue that individual predictors should tested against a model
that does not have that term (like a stepwise regression), but our
programs will calculate a test-statistics based on each predictor in the
model (more people ignore these and just look at the change in overall
model fit)
\[ Wald =
\frac{B_j}{SE_{B_j}^2}\]
anova(LR.1, test="Chisq")
## Analysis of Deviance Table
##
## Model: binomial, link: logit
##
## Response: Hipster
##
## Terms added sequentially (first to last)
##
##
## Df Deviance Resid. Df Resid. Dev Pr(>Chi)
## NULL 29 40.381
## Transport 1 18.5679 28 21.813 1.64e-05 ***
## Irony 1 2.5044 27 19.308 0.1135
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Hierarchical testing
- Going stepwise can be difficult if you have lots of predictors
- Since we cannot test the change in \(R^2\) we will instead test whether the
deviance is significantly greater than the model without the predictor
(just like above)
- So we run likelihood ratio test between the models which tests
against the chi-square distribution
LR.Model.1<-glm(Hipster~Irony,data=LogisticStudy1, family=binomial(link = "logit"))
LR.Model.2<-glm(Hipster~Irony+Transport,data=LogisticStudy1, family=binomial(link = "logit"))
anova(LR.Model.1,LR.Model.2,test = "Chisq")
## Analysis of Deviance Table
##
## Model 1: Hipster ~ Irony
## Model 2: Hipster ~ Irony + Transport
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 28 38.294
## 2 27 19.308 1 18.986 1.317e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
- Here we see model 2 has improvement in deviance (it fits better) and
thus it means Transport did help the prediction
How well am I predicting?
fitted.results <- predict(LR.Model.1,newdata=LogisticStudy1,type='response')
fitted.results <- ifelse(fitted.results > 0.5,1,0)
misClasificError <- mean(fitted.results != LogisticStudy1$Hipster)
print(paste('Accuracy = ',round(1-misClasificError,3)))
## [1] "Accuracy = 0.633"
fitted.results <- predict(LR.Model.2,newdata=LogisticStudy1,type='response')
fitted.results <- ifelse(fitted.results > 0.5,1,0)
misClasificError <- mean(fitted.results != LogisticStudy1$Hipster)
print(paste('Accuracy = ',round(1-misClasificError,3)))
## [1] "Accuracy = 0.967"
- This is not the only way to examine accuracy
- To get correct responses, misses and false alarms (remember our type
I and II boxes)
- To visualize this, we will examine receiver operator curves
(ROC)
- It is the relationship between correct responses and false
alarms
library(ROCR)
fitted.results <- predict(LR.Model.2,newdata=LogisticStudy1,type='response')
pr <- prediction(fitted.results, LogisticStudy1$Hipster)
prf <- performance(pr, measure = "tpr", x.measure = "fpr")
plot(prf)
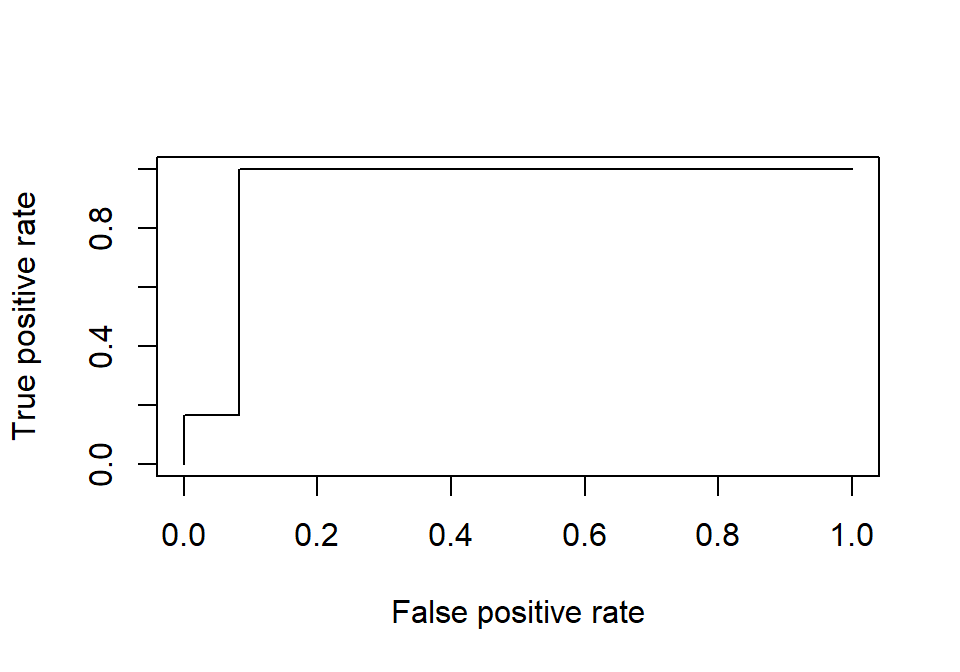
- We will calculate the area under the curve to get a good measure of
accuracy (the closer to 1 the better)
- Also, the curve should follow the shape you see below (if it is the
opposite shape you have a problem)
auc <- performance(pr, measure = "auc")
auc <- auc@y.values[[1]]
print(paste('Area under the Curve = ',round(auc,3)))
## [1] "Area under the Curve = 0.931"
Interactions
- Just like in multiple regression you test for interactions
LR.Model.2<-glm(Hipster~Transport+Irony,data=LogisticStudy1, family=binomial(link = "logit"))
LR.Model.3<-glm(Hipster~Transport*Irony,data=LogisticStudy1, family=binomial(link = "logit"))
anova(LR.Model.2,LR.Model.3,test = "Chisq")
## Analysis of Deviance Table
##
## Model 1: Hipster ~ Transport + Irony
## Model 2: Hipster ~ Transport * Irony
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 27 19.308
## 2 26 16.410 1 2.8979 0.08869 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
- There is no improvement of fit, but here are the models side by
side
|
|
|
|
Dependent variable:
|
|
|
|
|
|
Hipster
|
|
|
Main Effects
|
Interaction
|
|
|
(1)
|
(2)
|
|
|
|
Constant
|
-0.441 (0.629)
|
-1.272 (1.047)
|
|
Transport
|
1.610** (0.600)
|
2.238* (0.964)
|
|
Irony
|
0.502 (0.338)
|
0.925 (0.499)
|
|
Transport:Irony
|
|
-0.613 (0.433)
|
|
|
|
Observations
|
30
|
30
|
|
Log Likelihood
|
-9.654
|
-8.205
|
|
Akaike Inf. Crit.
|
25.308
|
24.410
|
|
|
|
Note:
|
p<0.05; p<0.01;
p<0.001
|
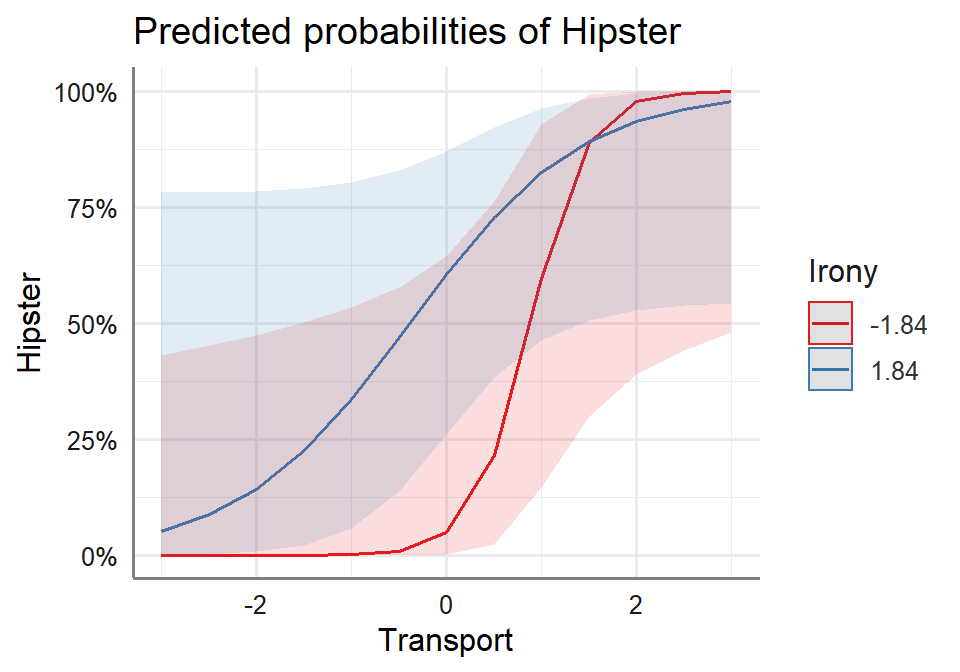
We can plot them (even though they are not significant).
We can use sjPlot you must manually set the level
for which you want to see the moderator (like we did with Rockchalk).
You can set SD and for Irony that values is 1.84 or whatever moderator
values you want. Note you cannot pass the variables, you must hand
type them.
plot_model(LR.Model.3, type = "pred",
terms = c("Transport", "Irony [-1.84,1.84]"))+
theme_sjplot2()
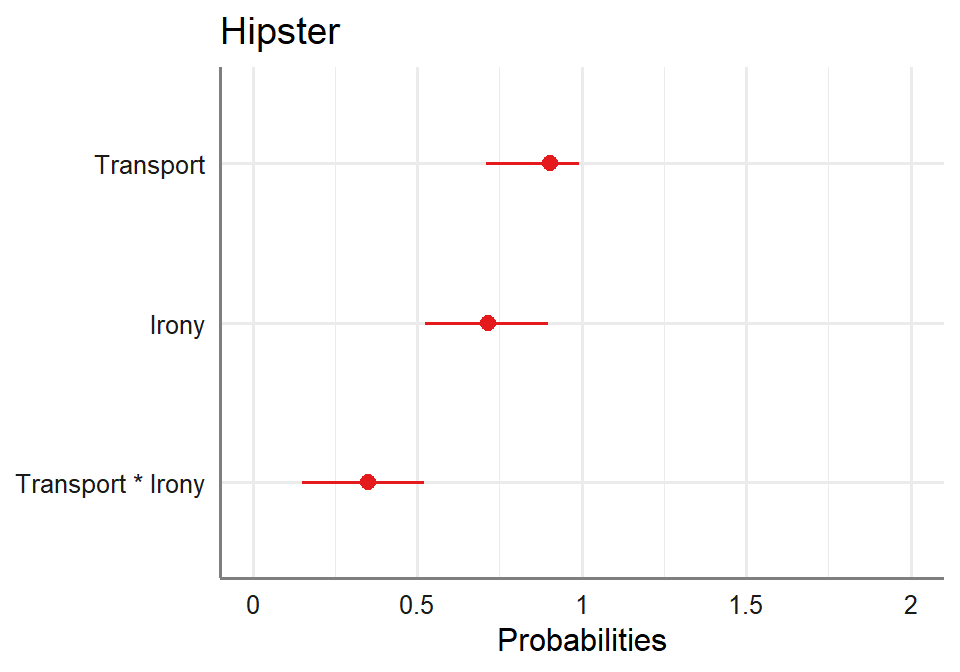
Other types of plots
- You can also plot forest plots. This is useful when you have lots of
predicts
- You will want these values to not overlap .50 (an odds of 1:1) or
coin flip
plot_model(LR.Model.3, transform = "plogis")+theme_sjplot2()
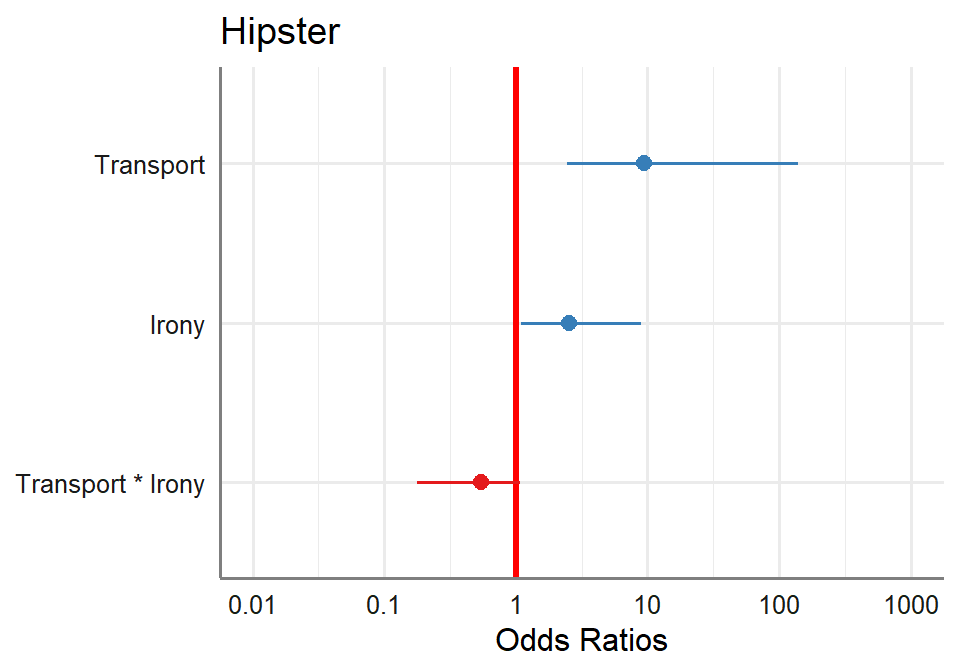
- see them in odd ratios below
plot_model(LR.Model.3, vline.color = "red")+theme_sjplot2()
LS0tDQp0aXRsZTogJ0dlbmVyYWxpemVkIExpbmVhciBNb2RlbCcNCm91dHB1dDoNCiAgaHRtbF9kb2N1bWVudDoNCiAgICBjb2RlX2Rvd25sb2FkOiB5ZXMNCiAgICBmb250c2l6ZTogOHB0DQogICAgaGlnaGxpZ2h0OiB0ZXh0bWF0ZQ0KICAgIG51bWJlcl9zZWN0aW9uczogbm8NCiAgICB0aGVtZTogZmxhdGx5DQogICAgdG9jOiB5ZXMNCiAgICB0b2NfZmxvYXQ6DQogICAgICBjb2xsYXBzZWQ6IG5vDQotLS0NCg0KDQoNCmBgYHtyIHNldHVwLCBpbmNsdWRlPUZBTFNFfQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGNhY2hlPVRSVUUpDQprbml0cjo6b3B0c19jaHVuayRzZXQoZWNobyA9IFRSVUUpICNTaG93IGFsbCBzY3JpcHQgYnkgZGVmYXVsdA0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KG1lc3NhZ2UgPSBGQUxTRSkgI2hpZGUgbWVzc2FnZXMgDQprbml0cjo6b3B0c19jaHVuayRzZXQod2FybmluZyA9ICBGQUxTRSkgI2hpZGUgcGFja2FnZSB3YXJuaW5ncyANCmtuaXRyOjpvcHRzX2NodW5rJHNldChmaWcud2lkdGg9NSkgI1NldCBkZWZhdWx0IGZpZ3VyZSBzaXplcw0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGZpZy5oZWlnaHQ9My41KSAjU2V0IGRlZmF1bHQgZmlndXJlIHNpemVzDQprbml0cjo6b3B0c19jaHVuayRzZXQoZmlnLmFsaWduPSdjZW50ZXInKSAjU2V0IGRlZmF1bHQgZmlndXJlDQprbml0cjo6b3B0c19jaHVuayRzZXQoZmlnLnNob3cgPSAiaG9sZCIpICNTZXQgZGVmYXVsdCBmaWd1cmUNCmtuaXRyOjpvcHRzX2NodW5rJHNldChyZXN1bHRzID0gImhvbGQiKSANCmBgYA0KDQojIEdlbmVyYWxpemVkIExpbmVhciBNb2RlbCAoR0xNKQ0KLSAqKlRoaXMgaXMgYSB3aG9sZSBhcmVhIGluIHJlZ3Jlc3Npb24gYW5kIHdlIGNvdWxkIHNwZW5kIGEgZnVsbCBzZW1lc3RlciBvbiB0aGlzIHRvcGljLiBUb2RheSdzIGdvYWwgaXMgYSBjcmFzaCBjb3Vyc2Ugb24gdGhlIGJhc2ljcyBvZiB0aGUgbW9zdCBjb21tb24gdHlwZSBvZiBHTE0gdXNlZCwgdGhlIGxvZ2lzdGljIHJlZ3Jlc3Npb24qKg0KLSBTbyBmYXIgeW91IGhhdmUgYmVlbiB1c2luZyBhIHNwZWNpYWwgY2FzZSBvZiB0aGUgR0xNLCB3aGVyZSB3ZSBhc3N1bWUgdGhlIHVuZGVybHlpbmcgYXNzdW1wdGlvbiBpcyBhIEdhdXNzaWFuIGRpc3RyaWJ1dGlvbg0KLSBOb3cgd2Ugd2lsbCBleHBhbmQgb3V0IHRoZSBleGFtaW5lIHRoZSB3aG9sZSBmYW1pbHkNCi0gV2hlbiB5b3UgcnVuIGEgR0xNLCB5b3UgbmVlZCB0byBzdGF0ZSAiZmFtaWx5IiBhbmQgdGhlICJsaW5raW5nIiBmdW5jdGlvbiB5b3Ugd2lsbCB1c2UNCg0KIyMgRmFtaWx5IGFuZCBMaW5rDQotIExpbmVhciByZWdyZXNzaW9uIGFzc3VtZXMgdGhhdCBEViA9ICRcbXUkIGFuZCBTRCA9ICRcc2lnbWEkIGFuZCB0aGUgcG9zc2libGUgcmFuZ2Ugb2YgcmVzcG9uc2VzIGlzIGZyb20gJC1caW5mdHksXGluZnR5JA0KICAgIC0gQnV0IEdMTSB3aWxsIGFsbG93IHVzIHRvIGV4YW1pbmUgY2F0ZWdvcmljYWwgcmVzcG9uc2VzICgyIG9yIG1vcmUgcmVzcG9uc2VzKSwgYW5kIHlvdSBjYW5ub3Qgc2F0aXNmeSB0aGUgc2FtZSByZXF1aXJlbWVudHMgYXMgbGluZWFyIHJlZ3Jlc3Npb24gKHlvdSBjYW5ub3QgaGF2ZSAkLVxpbmZ0eSxcaW5mdHkkIHJlc3BvbnNlIHJhbmdlKSANCi0gU29tZSBvZiB0aGUgb3RoZXIgZGlzdHJpYnV0aW9ucywgbGlrZSBiaW5vbWlhbCAoMiByZXNwb25zZXMpIG9yIFBvaXNzb24gKG11bHRpcGxlIHJlc3BvbnNlcykgY2FuIGFwcHJveGltYXRlIG5vcm1hbCB3aGVuIHRyYW5zZm9ybWVkDQotIFdlIG5lZWQgdG8gImxpbmsiIHRoZSBtZWFuIG9mIERWIHRvIHRoZSBsaW5lYXIgdGVybSBvZiB0aGUgbW9kZWwgKHRoaW5rIHRyYW5zZm9ybSkgdG8gbWFrZSBpdCBtZWV0IG91ciByZWdyZXNzaW9uIHJlcXVpcmVtZW50cyAgDQotIEhlcmUgYXJlIHRoZSBtb3N0IGNvbW1vbiBmYW1pbGllcyB1c2VkIGluIHBzeWNob2xvZ3kNCg0KRmFtaWx5ICAgIHwgVmFyaWFuY2UgfCBMaW5rDQotLS0tLS0tLS0tfCAtLS0tLS0tLSB8IC0tLS0tLS0NCkdhdXNzaWFuICB8IEdhdXNzaWFuIHwgaWRlbnRpdHkNCmJpbm9taWFsICB8IGJpbm9taWFsIHwgbG9naXQvUHJvYml0DQpQb2lzc29uICAgfCBQb2lzc29uICB8IGxvZw0KDQoNCiMgTGluZWFyIHJlZ3Jlc3Npb24gb24gYmlub21pYWwgRFYNCi0gKkxldCdzIHNpbXVsYXRlIHdoYXQgaGFwcGVucyB3aGVuIHdlIGFuYWx5emUgYmlub21pYWwgRFYgYXMgaXQgd2VyZSBhIHBsYWluIG9sZCByZWdyZXNzaW9uKg0KLSBXaGF0IGlzIHdlIHdhbnRlZCB0byBwcmVkaWN0IHdobyBpcyBhIGhpcHN0ZXIgYmFzZWQgb24gc3BlY2lmaWMgZmVhdHVyZXMgb2YgdGhlaXIgYXBwZWFyYW5jZSBhbmQgYXR0aXR1ZGUuIA0KLSBTaW11bGF0ZSBhIG1vZGVsIEhpcHN0ZXIgKERWOiAwID0gTm90IGEgSGlwc3RlciwgMSA9IEhpcHN0ZXIpIGJhc2VkIG9uIHRoZSBVc2Ugb2YgSXJvbnkgKElWID0gLTMgdG8gMykgYW5kIFJpZGljdWxvdXNuZXNzIG9mIHRyYW5zcG9ydGF0aW9uIChJViA9IC0zIHRvIDMpDQotIFRoZSBnb2FsIGlzIHRvIHByZWRpY3QgSGlwc3RlciBzdGF0dXMNCiAgICAtIEJlbG93IGlzIHRoZSBzaW11bGF0aW9uIGFuZCB3ZSB3aWxsIHJ1biBhICoqbGluZWFyIHJlZ3Jlc3Npb24qKi4gDQogICAgLSBGaXJzdCBhIHJhdyBkYXRhIHBsb3QgKHNob3cgdGhlIHByZWRpY3RvcnMgb25lIGEgdGltZSkhDQogICAgDQpgYGB7ciBkYXRhLGVjaG89VFJVRSwgb3V0LndpZHRoPScuNDlcXGxpbmV3aWR0aCcsIGZpZy53aWR0aD0zLjI1LCBmaWcuaGVpZ2h0PTMuMjUsZmlnLnNob3c9J2hvbGQnLGZpZy5hbGlnbj0nY2VudGVyJ30NCmxpYnJhcnkoZ2dwbG90MikNCnNldC5zZWVkKDQyKQ0Kbj0zMA0KeCA9IHJ1bmlmKG4sLTMsMykgIyAgUmlkaWN1bG91c25lc3Mgb2YgdHJhbnNwb3J0YXRpb24gWy0zIG5vcm1hbCwgMyA9IHVuaS1jeWNsZXNdDQpqID0gcnVuaWYobiwtMywzKSAjICBJcm9ueSB1c2FnZSBbLTMgbmV2ZXIsIDMgPSBBbGwgdGhlIHRpbWVdDQp6ID0gIC44KnggKyAuMipqICAgICAgICAgDQpwciA9IDEvKDErZXhwKC16KSkgICMgcGFzcyB0aHJvdWdoIGFuIGludi1sb2dpdCBmdW5jdGlvbg0KeSA9IHJiaW5vbShuLDEscHIpICAjIHJlc3BvbnNlIHZhcmlhYmxlDQojIEJ1aWxkIGRhdGEgZnJhbWUNCkxvZ2lzdGljU3R1ZHkxPSBkYXRhLmZyYW1lKEhpcHN0ZXI9eSxUcmFuc3BvcnQ9eCwgSXJvbnk9aikNCg0KZ2dwbG90KExvZ2lzdGljU3R1ZHkxLCBhZXMoeD1UcmFuc3BvcnQsIHk9SGlwc3RlcikpICsgZ2VvbV9wb2ludCgpICsgDQogIHN0YXRfc21vb3RoKG1ldGhvZD0ibG0iLCBmb3JtdWxhPXl+eCwgc2U9RkFMU0UpKw0KICB0aGVtZV9jbGFzc2ljKCkNCmdncGxvdChMb2dpc3RpY1N0dWR5MSwgYWVzKHg9SXJvbnksIHk9SGlwc3RlcikpICsgZ2VvbV9wb2ludCgpICsgDQogIHN0YXRfc21vb3RoKG1ldGhvZD0ibG0iLCBmb3JtdWxhPXl+eCwgc2U9RkFMU0UpKw0KICB0aGVtZV9jbGFzc2ljKCkNCmBgYA0KLSBOb3RlIGluIHRoZSBncmFwaHMsIGFsbCB5b3VyIERWcyBhcmUgYXQgdGhlIHRvcCBhbmQgYm90dG9tIG9mIHRoZSBncmFwaC4gDQogICAgLSBXaGF0IGRvZXMgdGhhdCBiZXN0IGZpdCBsaW5lIG1lYW4/DQoNCi0gTGV0J3MgcnVuIG91ciBtdWxpcGxlIHJlZ3Jlc3Npb246IGBIaXBzdGVyfiBUcmFuc3BvcnQgKyBJcm9ueWANCmBgYHtyfQ0KTE0uMTwtbG0oSGlwc3Rlcn5UcmFuc3BvcnQrSXJvbnksZGF0YT1Mb2dpc3RpY1N0dWR5MSkNCmBgYA0KDQotIFVzaW5nIGBzalBsb3RgICh3aGljaCBpcyBsaWtlIGVmZmVjdHMgcGFja2FnZSBtZXJnZWQgaW50byBnZ3Bsb3QpIHdlIGNhbiBwbG90IHRoZSByZXN1bHRzDQoNCmBgYHtyLGVjaG89VFJVRSwgb3V0LndpZHRoPScuNDlcXGxpbmV3aWR0aCcsIGZpZy53aWR0aD0zLjI1LCBmaWcuaGVpZ2h0PTMuMjUsZmlnLnNob3c9J2hvbGQnLGZpZy5hbGlnbj0nY2VudGVyJ30NCmxpYnJhcnkoc2pQbG90KQ0KcGxvdF9tb2RlbChMTS4xLCB0eXBlID0gImVmZiIsIGF4aXMubGltPWMoLS4yNSwxLjI1KSwNCiAgICAgICAgICAgdGVybXM9YygiVHJhbnNwb3J0IikpK3RoZW1lX3NqcGxvdDIoKQ0KcGxvdF9tb2RlbChMTS4xLCB0eXBlID0gImVmZiIsYXhpcy5saW09YygtLjI1LDEuMjUpLA0KICAgICAgICAgICB0ZXJtcz1jKCJJcm9ueSIpKSt0aGVtZV9zanBsb3QyKCkNCmBgYA0KDQpgYGB7ciwgZWNobz1GQUxTRSxyZXN1bHRzPSdhc2lzJ30NCmxpYnJhcnkoc3RhcmdhemVyKQ0Kc3RhcmdhemVyKExNLjEsdHlwZT0iaHRtbCIsDQogICAgICAgICAgY29sdW1uLmxhYmVscyA9IGMoIkxNIiksDQogICAgICAgICAgaW50ZXJjZXB0LmJvdHRvbSA9IEZBTFNFLCAgc2luZ2xlLnJvdz1UUlVFLCBub3Rlcy5hcHBlbmQgPSBGQUxTRSwNCiAgICAgICAgICBvbWl0LnN0YXQ9Yygic2VyIiksIHN0YXIuY3V0b2ZmcyA9IGMoMC4wNSwgMC4wMSwgMC4wMDEpLA0KICAgICAgICAgIGhlYWRlcj1GQUxTRSkNCmBgYA0KDQotIFRoZSAqKmludGVyY2VwdCoqIHJlZmxlY3RzIHRoZSBtZWFuIEhpcHN0ZXIgYXQgdGhlIG1lYW4gb2YgdGhlIElWcw0KLSBUaGUgKipzbG9wZSBvZiBUcmFuc3BvcnQqKiBzYXlzIGFzIHdlaXJkZXIgdGhlaXIgVHJhbnNwb3J0IGdldHMgdGhlIG1vcmUgbGlrZWx5IHRoZSBwZXJzb24gaXMgYSBoaXBzdGVyDQotIFRoZSAqKnNsb3BlIG9mIElyb255Kiogc2F5cyBhcyB0aGUgcGVyc29uIHVzZXMgbW9yZSBpcm9ueSB0aGUgbW9yZSBsaWtlbHkgdGhlIHBlcnNvbiBpcyBhIGhpcHN0ZXIgKGJ1dCBpdCdzIG5vdCBzaWduaWZpY2FudCkNCi0gSG93IGRvIHRoZSByZXNpZHVhbHMgbG9vaz8NCg0KYGBge3IgcGxvdGRpYWd9DQpwbG90X21vZGVsKExNLjEsIHR5cGUgPSAiZGlhZyIpWzRdDQpgYGANCg0KLSBUaGF0IGxvb2tzIHJlYWxseSBvZGQgYmVjYXVzZSB0aGUgZml0dGVkIChwcmVkaWN0IHZhbHVlcykgYXJlIGNvbnRpbnVvdXMsIGJ1dCB0aGUgcmVzcG9uc2UgaXMgYmlub21pYWwNCi0gTGV0J3Mgc2VlIGhvdyB3ZWxsIHdlICpwcmVkaWN0ZWQqIChmaXQpIG91ciByZXN1bHQgZm9yIGVhY2ggaW5kaXZpZHVhbDoNCiAgICAtIFJlbWVtYmVyIHRvIG1ha2UgYSAicHJlZGljdGlvbiIgd2Ugc29sdmUgdGhlIHJlZ3Jlc3Npb24gZXF1YXRpb25zIGZvciBlYWNoIHN1YmplY3RzIElWcyB0aGUgRFYgKEhpcHN0ZXIpIA0KDQpgYGB7ciBydW5wcmVkaWN0fQ0KTG9naXN0aWNTdHVkeTEkUHJlZGljdGVkLlZhbHVlPC1wcmVkaWN0KExNLjEpDQpzdW1tYXJ5KExvZ2lzdGljU3R1ZHkxJFByZWRpY3RlZC5WYWx1ZSkNCmBgYA0KDQotIFlpa2VzISBUaGUgbW9kZWwgcHJlZGljdGVkIGEgdmFsdWUgb3V0c2lkZSB0aGUgcmFuZ2Ugb2YgcG9zc2libGUgdmFsdWVzICh2YWx1ZSBhYm92ZSAxKQ0KLSBMZXQncyBzYXkgYW55IHByZWRpY3Rpb24gPiAuNSA9IEhpcHN0ZXIgYW5kIGJlbG93IHRoYXQgaXMgTm90IEhpcHN0ZXINCi0gVGhlbiB3ZSB3aWxsIGV4YW1pbmUgYSBjb250aW5nZW5jeSB0YWJsZSAocHJlZGljdCByZXN1bHRzIHRvIHRydWUgcmVzdWx0cykNCg0KYGBge3IgZml0cHJlZGljdH0NCkxvZ2lzdGljU3R1ZHkxJFByZWRpY3RlZC5IaXBzdGVyPC1pZmVsc2UoTG9naXN0aWNTdHVkeTEkUHJlZGljdGVkLlZhbHVlID4gLjUsMSwwKQ0KQy5UYWJsZTwtd2l0aChMb2dpc3RpY1N0dWR5MSwNCiAgIHRhYmxlKFByZWRpY3RlZC5IaXBzdGVyLCBIaXBzdGVyKSkNCkMuVGFibGUNCmBgYA0KDQotIENvcnJlY3QgcHJlZGljdCBpcyBbMCAmIDBdIGFuZCBbMSAmIDFdLCBiYWQgcHJlZGljdGlvbiBhcmUgbWlzbWF0Y2hlcw0KLSBUbyBnZXQgYW4gYWNjdXJhbmN5IHNjb3JlOiBbYHIgQy5UYWJsZVsxLDFdYCArICBgciBDLlRhYmxlWzIsMl1gIF0vIGByIHN1bShDLlRhYmxlKWAgWCAxMDANCg0KYGBge3J9DQpQZXJjZW50UHJlZGljdGVkPC0oQy5UYWJsZVsxLDFdK0MuVGFibGVbMiwyXSkvc3VtKEMuVGFibGUpKjEwMA0KYGBgDQoNCi0gWWllbGRzIEFjY3VyYWN5ID0gYHIgUGVyY2VudFByZWRpY3RlZGAlDQoNCi0gU28gdGhlIG1vZGVsIGRpZCBhIGdvb2Qgam9iIG1ha2luZyB0aGUgcHJlZGljdGlvbiBpbiB0aGlzIHNpbXBsZSBjYXNlLCBidXQgdGhlICRSXjIkIGhhcyBubyBtZWFuaW5nICh3aGF0IHZhcmlhYmlsaXR5IG9mIEhpcHN0ZXIgaXMgaXQgZXhwbGFpbmluZz8pDQoNCiMjIyBTdW1tYXJ5DQoNCiFbXShSZWdyZXNzaW9uQ2xhc3MvT0xTLnBuZykNCg0KVXNpbmcgbGluZWFyIHJlZ3Jlc3Npb24gb24gdGhpcyBkYXRhIHByb2R1Y2VkIG9kZCBwcmVkaWN0aW9ucyBvdXRzaWRlIG9mIHRoZSBib3VuZGVkIHJhbmdlLCB2aW9sYXRpb24gb2YgaG9tb3NjZWRhc3RpY2l0eSwgYW5kIGFuICRSXjIkIHdoaWNoIG1ha2VzIG5vIHNlbnNlLiBJbnN0ZWFkLCBsZXQncyB0cnkgYSBHTE0sIGJ1dCBmaXJzdCBsZXQncyB1bmRlcnN0YW5kIHRoZSBiaW5vbWlhbCBkaXN0cmlidXRpb24gYW5kIGxvZ2l0IGxpbmsgZnVuY3Rpb24uDQoNCiMgTG9naXN0aWMgUmVncmVzc2lvbg0KLSBMb2dpc3RpYyByZWdyZXNzaW9uIGlzIHRoYXQgd2UgY2FsbCB0aGUgcmVncmVzc2lvbiB3aGVyZSB3ZSBhbmFseXplIGJpbm9taWFsIERWDQoNCiMjIEJpbm9taWFsIERpc3RyaWJ1dGlvbiANCi0gQmlub21pYWwgY2FuIGJlIGV4cHJlc3NlZCBhcyBmb2xsb3dzOiANCiQkcChufE4pID0gKFxmcmFje059e259KXBebigxLXBee04tbn0pJCQNCi0gd2hlcmUgJG4kID0gc3VjY2Vzc2VzIGluICROJCB0cmlhbHMsIGF0IGEgc3BlY2lmaWMgJHAkIHByb2JhYmlsaXR5DQotIFRoZXNlIGNoYW5nZSBhcyBmdW5jdGlvbiBvZiB0aGUgdW5kZXJseWluZyBwcm9iYWJpbGl0eSBvZiBnZXR0aW5nIGEgMCBvciAxDQotIFRoZSBwbG90IGJlbG93IGhhcyAkTj0xMCQgcGVvcGxlIG1ha2luZyAxIHJlc3BvbnNlIGVhY2gsIHdpdGggcHJvYmFiaWxpdHkgY2hhbmdpbmcgZnJvbSAwIHRvIDEgYnkgLjI1IA0KDQpgYGB7ciwgZmlnLndpZHRoPTcuNSwgZmlnLmhlaWdodD0zLjB9DQpwYXIobWZyb3c9YygxLCA1KSkNCmZvcihwIGluIHNlcSgwLCAxLCBsZW49NSkpDQp7DQogICAgeCA8LSBkYmlub20oMDoxMCwgc2l6ZT0xMCwgcD1wKQ0KICAgIGJhcnBsb3QoeCwgbmFtZXMuYXJnPTA6MTAsIHNwYWNlPTApDQp9DQpgYGANCg0KLSBBcyB0aGUgbnVtYmVyIG9mIHBlb3BsZSBpbmNyZWFzZXMsIHlvdSB3aWxsIG5vdGljZSBpdCBsb29rcyBub3JtYWwsIGhlcmUgaXMgMTAwIHJlc3BvbnNlcw0KDQpgYGB7ciwgZmlnLndpZHRoPTcuNSwgZmlnLmhlaWdodD0zLjB9DQpwYXIobWZyb3c9YygxLCA1KSkNCmZvcihwIGluIHNlcSgwLCAxLCBsZW49NSkpDQp7DQogICAgeCA8LSBkYmlub20oMDoxMDAsIHNpemU9MTAwLCBwPXApDQogICAgYmFycGxvdCh4LCBuYW1lcy5hcmc9MDoxMDAsIHNwYWNlPTApDQp9DQpgYGANCg0KIyMgTG9naXQgTGlua2luZyBGdW5jdGlvbg0KLSBXZSBjYW4gYm91bmQgb3VyIHJlc3VsdHMgbWFraW5nIG91ciBiZXN0IGZpdCBsaW5lICphc3ltcHRvdGljKiB0byB0aGUgYm91bmRhcnkgY29uZGl0aW9ucw0KICAgIC0gVG8gbWFrZSB0aGlzIHdvcmssIHdlIG5lZWQgdG8gc3dpdGNoIGZyb20gc3RyYWlnaHQgKipsaW5lcyoqIHRvIHRoZSAqKnNpZ21vaWQqKiANCi0gUmVtZW1iZXIgcmVncmVzc2lvbiB3YW50cyB0aGUgRFYgdG8gYmUgYmV0d2VlbiAkLVxpbmZ0eSxcaW5mdHkkLCBzbyBoYXZlIHdpbGwgaGF2ZSB0byBhcHBseSBhIHRoZSBsb2dpdCB0cmFuc2Zvcm0NCg0KJCRMb2dpdCA9IGxvZ1xmcmFje3B9ezEtcH0kJCANCg0KLSBOb3RlOiBJIHdpbGwgdXNlICpMb2cqIGZvciB0aGUgKk5hdHVyYWwgTG9nKiB0byBiZSBjb25zaXN0ZW50IHdpdGggUiAoYnV0IGluIG90aGVyIHBsYWNlcywgeW91IG1pZ2h0IHNlZSBuYXR1cmFsIGxvZyBhcyAqTE4qKQ0KDQpgYGB7ciwgZmlnLndpZHRoPTMuNSwgZmlnLmhlaWdodD0zLjB9DQpsb2dpdC5UcmFuc2Zvcm08LWZ1bmN0aW9uKHApIHtsb2cocC8oMS1wKSkgfQ0KDQpwbG90KGxvZ2l0LlRyYW5zZm9ybShzZXEoMCwxLC4wMDAxKSksc2VxKDAsMSwuMDAwMSksDQogICAgIG1haW49IkxvZ2l0IFRyYW5zZm9ybSIseWxpbSA9IGMoMCwxKSwNCiAgeGxhYj0iTG9naXQiLHlsYWI9IlByb2JhYmlsaXR5IikNCg0KYGBgDQoNCi0gWW91IGNhbiBzZWUgdGhlIHNpZ21vaWQgaXMgKmFzeW1wdG90aWMqIHRvIHRoZSBib3VuZGFyeSBjb25kaXRpb25zIG9mIDAgYW5kIDEgcHJvYmFiaWxpdHkhDQoNCiMjIEZpdCB0aGUgbG9naXN0aWMgcmVncmVzc2lvbiANCi0gJGxvZ2l0KEhpcHN0ZXIpID0gQl8xKFRyYW5zcG9ydCkgK0JfMihJcm9ueSkgKyBCXzAkDQotIFRoaXMgY2FuIGJlIGFjY29tcGxpc2hlZCBieSBjaGFuZ2luZyB0aGUgKmZ1bmN0aW9uKiBpbiBSIHRvICoqZ2xtKiogZnJvbSAqKmxtKiogYW5kIHNwZWNpZnlpbmcgdGhlICpmYW1pbHkqIGFzICoqYmlub21pYWwobGluayA9ICJsb2dpdCIpKioNCi0gRmlyc3QgbGV0J3MgcGxvdCBhbmQgdGhlbiBtYWtlIHNlbnNlIG9mIHRoZSBwYXJhbWV0ZXJzIGFmdGVyd2FyZHMNCg0KYGBge3J9DQpMUi4xPC1nbG0oSGlwc3Rlcn5UcmFuc3BvcnQrSXJvbnksZGF0YT1Mb2dpc3RpY1N0dWR5MSwgZmFtaWx5PWJpbm9taWFsKGxpbmsgPSAibG9naXQiKSkNCmBgYA0KDQojIyBQbG90IGluIHByb2JhYmlsaXRpZXMgDQotIFktYXhpcyA9IFByZWRpY3RlZCBwcm9iYWJpbGl0eSBvZiBIaXBzdGVyIGFzIGEgZnVuY3Rpb24gb2YgVHJhbnNwb3J0IHdlaXJkbmVzcyBvciBVc2Ugb2YgSXJvbnkNCi0gVXNpbmcgYHNqUGxvdGAgKHdoaWNoIGlzIGxpa2UgZWZmZWN0cyBwYWNrYWdlIG1lcmdlZCBpbnRvIGdncGxvdCkgd2UgY2FuIG5vdyBzZWUgDQoNCmBgYHtyLGVjaG89VFJVRSwgb3V0LndpZHRoPScuNDlcXGxpbmV3aWR0aCcsIGZpZy53aWR0aD0zLjI1LCBmaWcuaGVpZ2h0PTMuMjUsZmlnLnNob3c9J2hvbGQnLGZpZy5hbGlnbj0nY2VudGVyJ30NCmxpYnJhcnkoc2pQbG90KQ0KcGxvdF9tb2RlbChMUi4xLCB0eXBlID0gImVmZiIsDQogICAgICAgICAgIHRlcm1zPWMoIlRyYW5zcG9ydCIpKSt0aGVtZV9zanBsb3QyKCkNCnBsb3RfbW9kZWwoTFIuMSwgdHlwZSA9ICJlZmYiLA0KICAgICAgICAgICB0ZXJtcz1jKCJJcm9ueSIpKSt0aGVtZV9zanBsb3QyKCkNCmBgYA0KDQojIyBJbnRlcnByZXQgY29lZmZpY2llbnRzDQotIFJhdyBjb2VmZmljaWVudHMgYXJlIHRyYW5zZm9ybWVkIGFuZCB0aGlzIGhhcmQgdG8gbWFrZXMgc2Vuc2Ugb2YNCi0gU28gd2UgY2FuIHRyYW5zZm9ybSB0aGVtIGJhY2sgdG8gc29tZXRoaW5nIG1lYW5pbmdmdWw7IG9kZCByYXRpb3Mgb3IgcHJvYmFiaWxpdGllcw0KLSBPZGRzIHJhdGlvID0gc3VjY2VzcyBpcyBkZWZpbmVkIGFzIHRoZSByYXRpbyBvZiB0aGUgcHJvYmFiaWxpdHkgb2Ygc3VjY2VzcyBvdmVyIHRoZSBwcm9iYWJpbGl0eSBvZiBmYWlsdXJlDQotIDUwJSBjaGFuY2UgPSBvZGRzIHJhdGlvIG9mIDEgKDE6MSByYXRpbykNCg0KIVtdKFJlZ3Jlc3Npb25DbGFzcy9vZGRzLmpwZykNCg0KYGBge3IsIGVjaG89RkFMU0UsIHdhcm5pbmc9RkFMU0UsbWVzc2FnZT1GQUxTRSxyZXN1bHRzPSdhc2lzJ30NCnN0YXJnYXplcihMUi4xLHR5cGU9Imh0bWwiLA0KICAgICAgICAgIGNvbHVtbi5sYWJlbHMgPSBjKCJMb2dpc3RpYyIpLA0KICAgICAgICAgIGludGVyY2VwdC5ib3R0b20gPSBGQUxTRSwgIHNpbmdsZS5yb3c9VFJVRSwgbm90ZXMuYXBwZW5kID0gRkFMU0UsDQogICAgICAgICAgb21pdC5zdGF0PWMoInNlciIpLCBzdGFyLmN1dG9mZnMgPSBjKDAuMDUsIDAuMDEsIDAuMDAxKSwNCiAgICAgICAgICBoZWFkZXI9RkFMU0UpDQpgYGANCg0KJCRPZGRzID0gZV57bG9naXQoeCl9JCQgDQoNCmBgYHtyLCBmaWcud2lkdGg9My41LCBmaWcuaGVpZ2h0PTMuMH0NCkwudG8uTy5UcmFuc2Zvcm08LWZ1bmN0aW9uKHApIHtleHAobG9naXQuVHJhbnNmb3JtKHApKX0NCg0KcGxvdCgobG9naXQuVHJhbnNmb3JtKHNlcSgwLC45OSwuMDEpKSksTC50by5PLlRyYW5zZm9ybShzZXEoMCwuOTksLjAxKSksDQogICAgIG1haW49IkxvZ2l0IHRvIE9kZHMgVHJhbnNmb3JtIiwNCiAgeGxhYj0iTG9naXQiLHlsYWI9Ik9kZHMiKQ0KYGBgDQotIGhlcmUgYXJlIG91ciByZWdyZXNzaW9uIGVzdGltYXRlcyBhcyBvZGRzIHJhdGlvDQoNCmBgYHtyfQ0KTFIuMS5UcmFucyA8LSBjb2VmKHN1bW1hcnkoTFIuMSkpDQpMUi4xLlRyYW5zWywgIkVzdGltYXRlIl0gPC0gZXhwKGNvZWYoTFIuMSkpDQpgYGANCg0KYGBge3IsIGVjaG89RkFMU0V9DQprbml0cjo6a2FibGUoTFIuMS5UcmFucykNCmBgYA0KDQpvciB5b3UgY2FuIHVzZSB0aGUgc2pwbG90IHBhY2thZ2UNCmBgYHtyfQ0KIyB0YWJfbW9kZWwoTFIuMSwgDQojICAgICAgICAgIHNob3cuc2UgPSBUUlVFLHNob3cuYWljID0gVFJVRSwgc2hvdy5sb2dsaWs9VFJVRSxzaG93LmNpID0gRkFMU0UpDQpgYGANCg0KDQotIE1EcyB0YWxrIGluIG9kZHMsIGJ1dCBwc3ljaG9sb2dpc3RzIHNvbWV0aW1lIHByZWZlciBwcm9iYWJpbGl0aWVzDQokJFAgPSBcZnJhY3tPZGRzfSB7MSArIE9kZHN9JCQNCg0KYGBge3IsIGZpZy53aWR0aD0zLjUsIGZpZy5oZWlnaHQ9My4wfQ0KTy50by5QLlRyYW5zZm9ybTwtZnVuY3Rpb24ocCkge0wudG8uTy5UcmFuc2Zvcm0ocCkvKDErTC50by5PLlRyYW5zZm9ybShwKSl9DQoNCnBsb3QoTC50by5PLlRyYW5zZm9ybShzZXEoMCwuOTQsLjAxKSksTy50by5QLlRyYW5zZm9ybShzZXEoMCwuOTQsLjAxKSksDQogICAgIG1haW49Ik9kZHMgdG8gUHJvYmFibGl0eSBUcmFuc2Zvcm0iLA0KICB4bGFiPSJPZGRzIix5bGFiPSJQcm9iYWJsaXR5IikNCmBgYA0KDQotIFNvIHdlIGNhbiBjb252ZXJ0IG91ciByZWdyZXNzaW9uIGVxdWF0aW9uIHRvIGdpdmUgb3VyIHByb2JhYmlsaXRpZXMgZGlyZWN0bHkNCg0KJCRwX3soSGlwc3Rlcil9ID1cZnJhY3tlXnsoQl8xKFRyYW5zcG9ydCkrQl8yKElyb255KSArIEJfMH0pfXsxK2VeeyhCXzEoVHJhbnNwb3J0KStCXzIoSXJvbnkpICsgQl8wfSl9JCQNCg0KLSBvciBtb3JlIHNpbXBseSENCg0KJCRwX3soSGlwc3Rlcil9ID1cZnJhY3sxfXsxK2Veey0oQl8xKFRyYW5zcG9ydCkrQl8yKElyb255KSArIEJfMH0pfSQkDQoNCg0KYGBge3J9DQpMUi4xLlRyYW5zUCA8LSBjb2VmKHN1bW1hcnkoTFIuMSkpDQpMUi4xLlRyYW5zUFssICJFc3RpbWF0ZSJdIDwtIGV4cChjb2VmKExSLjEpKS8oMStleHAoY29lZihMUi4xKSkpDQpgYGANCg0KYGBge3IsIGVjaG89RkFMU0V9DQprbml0cjo6a2FibGUoTFIuMS5UcmFuc1ApDQoNCmBgYA0KDQpOb3RlOiBUaGVzZSBwcm9iYWJpbGl0aWVzIGFyZSBsaWtlIHRoZSBvZGRzIHJhdGlvLiBUaGV5IHJlcHJlc2VudCBob3cgbXVjaCBtb3JlIGxpa2VseSB0aGUgcmVzdWx0cyBiZXR3ZWVuIHRoZSBsZXZlbHMgb2YgdGhlIHByZWRpY3RvcnMuIFRoZXkgZG8gbm90IHRlbGwgeW91IHRoZSBsaWtlbGlob29kIG9mIGJlaW5nIGEgaGlwc3Rlci4gRm9yIHRoYXQgeW91IG11c3Qgc29sdmUgdGhlIGVxdWl0YXRpb24gYXMgSSBzaG93ZWQgYWJvdmUuIEFsc28geW91IGNhbiB1c2UgZWZmZWN0cyBvciBzanBsb3QgcGFja2FnZSB0byBwbG90IHRoZSByZXN1bHRzIGluIHByZWRpY3RlZCBwcm9iYWJpbGl0aWVzLiANCg0KDQojIyMgV2hhdCB0byByZXBvcnQNCi0gSG93ZXZlciwgeW91IGhhdmUgdG8gcmVwb3J0IHRoZSByYXcgdmFsdWVzIHRoYXQgY29tZSBmcm9tIHRoZSBsb2dpc3RpYyByZWdyZXNzaW9uIFtvciByZXBvcnQgdGhlbSBpbiBPZGRzIHJhdGlvc10NCi0gVGhpcyBpcyBiZWNhdXNlIHlvdXIgdW5pdHMgYXJlIHJhdyAoY2VudGVyZWQpIHVuaXRzIGFuZCBpZiB5b3UgdXNlZCB0aGlzIHRhYmxlIHlvdSB3b3VsZCBuZWVkIHRvIGZpZ3VyZSBvdXQgaG93IHRvIGNvbnZlcnQgYWxsIHlvdXIgSVYgdW5pdHMNCiAgICAtIFRodXMsIHlvdSB3b3VsZCBzaW1wbHkgdXNlIHRoZSBlcXVhdGlvbnMgYWJvdmUgd2hlbiB5b3UgYWRkIHVwIHlvdXIgcHJlZGljdG9ycw0KICAgIC0gU28ganVzdCBsaWtlIGluIGxpbmVhciByZWdyZXNzaW9uIHlvdSB3b3VsZCBhZGQgeW91ciBwcmVkaWN0b3IgZXN0aW1hdGVzIChsZXQncyBzYXkgaWYgeW91IGhhdmUgbm9taW5hbCB2YXJpYWJsZXMgYW5kIGludGVyYWN0aW9ucykgYW5kIHRoZW4gY29udmVydCB0aGVtIGFzIGFib3ZlDQoNCg0KDQojIFdhaXQhISBXaGF0IGFib3V0IG15IFItc3F1YXJlZD8NCi0gJFJeMiQgaGFzIG5vIG1lYW5pbmcgaGFzIG5vIG1lYW5pbmcgaW4gdGhlc2UgbW9kZWxzDQogICAgLSBUaGV5IGRvIG5vdCBtZWFzdXJlIHRoZSBhbW91bnQgb2YgKip2YXJpYW5jZSBhY2NvdW50ZWQgZm9yKioNCi0gQmlub21pbmFsIGRhdGEgY2Fubm90IGJlIGhvbW9zY2VkYXN0aWMsIGluIGZhY3QsIHlvdSBjb3VsZCBzZWUgdGhlcmUgaXMgbm8gc3ByZWFkIG9mIGRhdGEgYXJvdW5kIHRoZSBsaW5lLCBhbmQgYWxzbyB0aGUgdmFyaWFuY2UgYXQgZWFjaCB2YWx1ZSBtYXkgbm90IGJlIHNhbWUgDQotIE92ZXIgdGhlIHllYXJzIHBlb3BsZSBoYXZlIGNyZWF0ZWQgZGlmZmVyZW50IHR5cGVzIG9mIHBzZXVkby0kUl4yJCBpbiB3aGljaCB0byB0cnkgdG8gbWFrZSBsaW5lYXIgcmVncmVzc2lvbiB0eXBlcyBvZiB1bmRlcnN0YW5kaW5nIA0KICAgIC0gQ29tbW9uIGZhdm9yaXRlcyBhcmUgQ294ICYgU25lbGwgKGFrYSBNYXhpbXVtIGxpa2VsaWhvb2QpLCBOYWdlbGtlcmtlIChha2EgQ3JhZ2cgYW5kIFVobGVyJ3MpLCBNY0ZhZGRlbiwgRWZyb24ncywgZXRjDQogICAgLSBZb3UgY2FuIHNlZSBhbiBlYXN5IGRlc2NyaXB0aW9uIG9mIGVhY2ggdHlwZSBoZXJlOiBodHRwOi8vc3RhdHMuaWRyZS51Y2xhLmVkdS9vdGhlci9tdWx0LXBrZy9mYXEvZ2VuZXJhbC9mYXEtd2hhdC1hcmUtcHNldWRvLXItc3F1YXJlZHMvDQotIEVhY2ggb2YgdGhlbSB0cmllcyB0byBjYXB0dXJlIHNvbWV0aGluZyBsaWtlIG91ciBvcmlnaW5hbCAkUl4yJCwgc3VjaCBhcyAoQSkgZXhwbGFpbmluZyB2YXJpYWJpbGl0eSwgKEIpIG1vZGVsIGltcHJvdmVtZW50IHN1Y2ggYXMgJGNoYW5nZSBpbiBSXjIkIGJldHdlZW4gbW9kZWxzLCAoQykgYW5kIGZpbmFsbHkgYXMgYSBtZWFzdXJlIG9mIG11bHRpcGxlLWNvcnJlbGF0aW9uDQotIE1hbnkgb2YgdGhlc2UgYmV0d2VlbiB0ZXN0aW5nIGJldHdlZW4gYSByZXN0cmljdGVkIG1vZGVsIChOdWxsIG1vZGVsKSBhbmQgeW91ciBtb2RlbCwgc28gZmlyc3Qgd2UgbmVlZCB0byBleGFtaW5lIG1vZGVsIGZpdHRpbmcgZm9yIEdMTXMNCg0KIyMgRGV2aWFuY2UgVGVzdGluZyANCi0gSW4gbGluZWFyIHJlZ3Jlc3Npb24sIE9MUyB3YXMgdGhlIGZpdHRpbmcgcHJvY2VkdXJlLCBhbmQgaXQgd29ya2VkIGJlY2F1c2UgT0xTIGNhbiBmaW5kIG1lYW4gYW5kIHZhcmlhbmNlIG9mIHRoZSBub3JtYWwgZGlzdHJpYnV0aW9uLCBidXQgbm93IHdlIGFyZSBub3Qgd29ya2luZyB3aXRoIG5vcm1hbCBkaXN0cmlidXRpb25zLCBzbyB3ZSBuZWVkIGEgbmV3IGZpdHRpbmcgcHJvY2VkdXJlDQogICAgLSBJbiBvdXIgT0xTIHJlZ3Jlc3Npb24gd2UgaGFkIHRoaXMgY29uY2VwdDogJCRTU197UmVzaWR9ID0gU1NfWSAtIFNTX3tSZWdyZXNzaW9ufSQkDQogICAgICAgIC0gSW4gb3RoZXIgd29yZHMsIHJlc2lkdWFsID0gQWN0dWFsIC0gRml0dGVkIHZhbHVlcyANCiAgICAtIGluIE9MUywgd2UgY2FuIGdldCB0aGUgYmVzdCBmaXQgKmFuYWx5dGljYWxseSogKHNvbHZpbmcgYW4gZXF1YXRpb24pLCBidXQgd2l0aCBHTE0geW91IGNhbm5vdCBkbyB0aGF0IQ0KLSBGb3IgR0xNLCBXZSBjYW4gY2FsY3VsYXRlIHRoZSAqZGV2aWFuY2UqIG9mIHNjb3Jlcywgd2hpY2ggaXMgYnVpbHQgb24gdGhlIGlkZWEgb2YgKiptYXhpbXVtIGxpa2VsaWhvb2QqKg0KICAgIC0gV2UgKml0ZXJhdGUqIGEgc29sdXRpb24gKHNpbmNlIHdlIGNhbm5vdCBzb2x2ZSBpdCB3aXRob3V0IHRyaWFsIGFuZCBlcnJvcikNCiAgICAtIFdlIG5lZWQgdG8gZmluZCB0aGUgbGlrZWxpaG9vZDsgd2hpY2ggaXMgImEgaHlwb3RoZXRpY2FsIHByb2JhYmlsaXR5IHRoYXQgYW4gZXZlbnQgdGhhdCBoYXMgKiphbHJlYWR5Kiogb2NjdXJyZWQgd291bGQgeWllbGQgYSBzcGVjaWZpYyBvdXRjb21lIiAoaHR0cDovL21hdGh3b3JsZC53b2xmcmFtLmNvbS9MaWtlbGlob29kLmh0bWwpDQogICAgLSBXZSB3aWxsIGl0ZXJhdGUgdGhyb3VnaCBwYXJhbWV0ZXJzIHVudGlsIHdlIG1heGltaXplIG91ciBsaWtlbGlob29kIChjYWxsZWQgbWF4aW1hbCBsaWtlbGlob29kIGVzdGltYXRpb24pIA0KICAgIC0gVGhlcmUgYXJlIGRpZmZlcmVudCBNTCAob3IganVzdCBMKSBmdW5jdGlvbnMgdGhhdCBjYW4gYmUgdXNlZCBhbmQgdGhleSBjYW4gYXBwbHkgdG8gbW9zdCBkaXN0cmlidXRpb25zDQogICAgLSBXaGVuIHRoZSBmaXQgaXMgcGVyZmVjdCwgJCRMX3twZXJmZWN0fSA9IDEkJA0KICAgIC0gVGhlIG51bGwgY2FzZSAoc3RhcnRpbmcgbW9kZWwpIHRoYXQgT05MWSBoYXMgYW4gaW50ZXJjZXB0LCB0aGlzIHdpbGwgcHJvYmFibHkgeWllbGQgdGhlIGxvd2VzdCBsaWtlbGlob29kDQogICAgICAgIC0gT3VyIHRlc3QgbW9kZWwgd2lsbCBiZSBpbnRlcmNlcHQgKyBwcmVkaWN0b3JzIChwYXJhbWV0ZXJzIC0gaykNCg0KJCRMaWtlbGlob29kIHJhdGlvID1cZnJhY3tMX3tTaW1wbGV9fXtMX3tDb21wbGV4fX0kJA0KDQotIERldmlhbmNlIHRoaXMgaXMgdGhlICQtMiokIG5hdHVyYWwgbG9nTGlrZWxpaG9vZCByYXRpbyAgJCREID0gMipsb2coTGlrZWxpaG9vZCByYXRpbykkJCBBS0EgJCREID0gLTJMTCQkDQpGaXJzdCwgSSB3aWxsIHNob3cgeW91IHRoZSBwc2V1ZG8tJFJeMiQgYW5kIHRoZW4gd2Ugd2lsbCBleGFtaW5lIGhvdyB0byB0ZXN0IGJldHdlZW4gbW9kZWwgZml0cw0KDQotIE51bGwgRGV2aWFuY2UgDQokJERfe051bGx9ID0gLTJbbG9nKExfe051bGx9KSAtIGxvZyhMX3tQZXJmZWN0fSldJCQNCg0KLSBNb2RlbCBEZXZpYW5jZQ0KJCREX3tLfSA9IC0yW2xvZyhMX3tLfSAtIGxvZyhMX3tQZXJmZWN0fSldJCQNCi0gVGhpcyBpcyBsaWtlIG91ciBTUyByZXNpZHVhbCBmcm9tIE9MUw0KDQojIyMgUHNldWRvLVItc3FhdXJlZA0KLSBXZSBuZWVkIHRob3NlIGNyYXp5IERldmllbmNlIHNjb3JlcyBmb3Igc29tZSBvZiBvdXIgcHNldWRvLSRSXjIkIG1lYXN1cmVtZW50cywgZm9yIGV4YW1wbGU6IA0KJCRSX0xeMiA9IFxmcmFje0Rfe051bGx9IC1EX3trfX17RF97TnVsbH19JCQNCi0gQ294IGFuZCBTbmVsbCBpcyB3aGF0IFNQU1MgZ2l2ZXMgYW5kIHBlb3BsZSByZXBvcnQgaXQgb2Z0ZW4NCiAgICAtIE5hZ2Vsa2Vya2UgaXMgYW4gaW1wcm92ZW1lbnQgKEMmUykgYXMgaXQgY29ycmVjdHMgc29tZSBwcm9ibGVtcw0KLSBCdXQgcGVvcGxlIGxpa2UgTWNGYWRkZW4ncyBjYXVzZSBpdHMgZWFzeSB0byB1bmRlcnN0YW5kDQoNCiQkUl97TWNGYWRkZW59XjIgPSAxIC0gXGZyYWN7TExfe2t9fXtMTF97TnVsbH19JCQNCiANCi0gV2UgY2FuIGp1c3QgZ2V0IHRoZW0gZnJvbSB0aGUgYHBzY2xgIHBhY2thZ2UNCi0gbGxoID0gIGxvZy1saWtlbGlob29kIGZyb20gdGhlIGZpdHRlZCBtb2RlbCAobGxrIGFib3ZlKQ0KLSBsbGhOdWxsID0gVGhlIGxvZy1saWtlbGlob29kIGZyb20gdGhlIGludGVyY2VwdC1vbmx5IHJlc3RyaWN0ZWQgbW9kZWwNCi0gJEdeMiA9IC0yKExMX3tLfSAtIExMX3tOVUxMfSkkIGlzIGEgb25lIG9mIHRoZSBwcm9wb3NlZCBnb29kbmVzcyBvZiBmaXQgbWVhc3VyZXMgKHdlIHdpbGwgY29tZSBiYWNrIHRvIHRoaXMgbGF0ZXIpDQotIE1jRmFkZGVuID0gTWNGYWRkZW4gcHNldWRvLSRSXjIkDQotIHIyTUwgPSBDb3ggJiBTbmVsbCBwc2V1ZG8tJFJeMiQNCi0gcjJDVSA9IE5hZ2Vsa2Vya2UgcHNldWRvLSRSXjIkDQpgYGB7cn0NCmxpYnJhcnkocHNjbCkNCnBSMihMUi4xKQ0KYGBgDQogDQojIyMgV2FpdCB3aHkgSSBkbyBzZWUgWiBhbmQgbm90IHQtdmFsdWVzPw0KLSBXaGVuIHRlc3RpbmcgaW5kaXZpZHVhbCBwcmVkaWN0b3JzLCB5b3UgZG8gbm90IHNlZSB0LXRlc3RzIHlvdSBhcmUgbG9va2luZyBhdCAqV2FsZCBaLXNjb3JlcyoNCi0gU29tZSBhcmd1ZSB0aGF0IGluZGl2aWR1YWwgcHJlZGljdG9ycyBzaG91bGQgdGVzdGVkIGFnYWluc3QgYSBtb2RlbCB0aGF0IGRvZXMgbm90IGhhdmUgdGhhdCB0ZXJtIChsaWtlIGEgc3RlcHdpc2UgcmVncmVzc2lvbiksIGJ1dCBvdXIgcHJvZ3JhbXMgd2lsbCBjYWxjdWxhdGUgYSB0ZXN0LXN0YXRpc3RpY3MgYmFzZWQgb24gZWFjaCBwcmVkaWN0b3IgaW4gdGhlIG1vZGVsIChtb3JlIHBlb3BsZSBpZ25vcmUgdGhlc2UgYW5kIGp1c3QgbG9vayBhdCB0aGUgY2hhbmdlIGluIG92ZXJhbGwgbW9kZWwgZml0KSANCiANCiAkJCBXYWxkID0gXGZyYWN7Ql9qfXtTRV97Ql9qfV4yfSQkDQogDQotIFdhbGQgei1zY29yZXMgZm9sbG93IGEgY2hpLXNxdWFyZSBkaXN0cmlidXRpb24NCg0KLSBPciB5b3UgY2FuIHJ1biBhIHN0ZXB3aXNlIGFuZCB0ZXN0IGVhY2ggcHJlZGljdG9yIGFnYWluIHRoZSBudWxsIG1vZGVsIGxpa2UgdGhpcyAoKipvcmRlciBvZiBwcmVkaWN0b3JzIG1hdHRlcioqKQ0KDQpgYGB7ciwgZWNobz1UUlVFLCB3YXJuaW5nPUZBTFNFLG1lc3NhZ2U9RkFMU0V9DQphbm92YShMUi4xLCB0ZXN0PSJDaGlzcSIpDQpgYGANCiANCiMjIEhpZXJhcmNoaWNhbCB0ZXN0aW5nIA0KLSBHb2luZyBzdGVwd2lzZSBjYW4gYmUgZGlmZmljdWx0IGlmIHlvdSBoYXZlIGxvdHMgb2YgcHJlZGljdG9ycw0KLSBTaW5jZSB3ZSBjYW5ub3QgdGVzdCB0aGUgY2hhbmdlIGluICRSXjIkIHdlIHdpbGwgaW5zdGVhZCB0ZXN0IHdoZXRoZXIgdGhlIGRldmlhbmNlIGlzIHNpZ25pZmljYW50bHkgZ3JlYXRlciB0aGFuIHRoZSBtb2RlbCB3aXRob3V0IHRoZSBwcmVkaWN0b3IgKGp1c3QgbGlrZSBhYm92ZSkNCi0gU28gd2UgcnVuIGxpa2VsaWhvb2QgcmF0aW8gdGVzdCBiZXR3ZWVuIHRoZSBtb2RlbHMgd2hpY2ggdGVzdHMgYWdhaW5zdCB0aGUgY2hpLXNxdWFyZSBkaXN0cmlidXRpb24NCg0KYGBge3J9DQpMUi5Nb2RlbC4xPC1nbG0oSGlwc3Rlcn5Jcm9ueSxkYXRhPUxvZ2lzdGljU3R1ZHkxLCBmYW1pbHk9Ymlub21pYWwobGluayA9ICJsb2dpdCIpKQ0KTFIuTW9kZWwuMjwtZ2xtKEhpcHN0ZXJ+SXJvbnkrVHJhbnNwb3J0LGRhdGE9TG9naXN0aWNTdHVkeTEsIGZhbWlseT1iaW5vbWlhbChsaW5rID0gImxvZ2l0IikpDQphbm92YShMUi5Nb2RlbC4xLExSLk1vZGVsLjIsdGVzdCA9ICJDaGlzcSIpDQpgYGANCg0KLSBIZXJlIHdlIHNlZSBtb2RlbCAyIGhhcyBpbXByb3ZlbWVudCBpbiBkZXZpYW5jZSAoaXQgZml0cyBiZXR0ZXIpIGFuZCB0aHVzIGl0IG1lYW5zIFRyYW5zcG9ydCBkaWQgaGVscCB0aGUgcHJlZGljdGlvbg0KDQojIyBIb3cgd2VsbCBhbSBJIHByZWRpY3Rpbmc/DQotIE1vZGVsIDENCmBgYHtyfQ0KZml0dGVkLnJlc3VsdHMgPC0gcHJlZGljdChMUi5Nb2RlbC4xLG5ld2RhdGE9TG9naXN0aWNTdHVkeTEsdHlwZT0ncmVzcG9uc2UnKQ0KZml0dGVkLnJlc3VsdHMgPC0gaWZlbHNlKGZpdHRlZC5yZXN1bHRzID4gMC41LDEsMCkNCm1pc0NsYXNpZmljRXJyb3IgPC0gbWVhbihmaXR0ZWQucmVzdWx0cyAhPSBMb2dpc3RpY1N0dWR5MSRIaXBzdGVyKQ0KcHJpbnQocGFzdGUoJ0FjY3VyYWN5ID0gJyxyb3VuZCgxLW1pc0NsYXNpZmljRXJyb3IsMykpKQ0KYGBgDQotIE1vZGVsIDINCmBgYHtyLCBlY2hvPVRSVUUsIHdhcm5pbmc9RkFMU0UsbWVzc2FnZT1GQUxTRX0NCmZpdHRlZC5yZXN1bHRzIDwtIHByZWRpY3QoTFIuTW9kZWwuMixuZXdkYXRhPUxvZ2lzdGljU3R1ZHkxLHR5cGU9J3Jlc3BvbnNlJykNCmZpdHRlZC5yZXN1bHRzIDwtIGlmZWxzZShmaXR0ZWQucmVzdWx0cyA+IDAuNSwxLDApDQptaXNDbGFzaWZpY0Vycm9yIDwtIG1lYW4oZml0dGVkLnJlc3VsdHMgIT0gTG9naXN0aWNTdHVkeTEkSGlwc3RlcikNCnByaW50KHBhc3RlKCdBY2N1cmFjeSA9ICcscm91bmQoMS1taXNDbGFzaWZpY0Vycm9yLDMpKSkNCmBgYA0KDQotIFRoaXMgaXMgbm90IHRoZSBvbmx5IHdheSB0byBleGFtaW5lIGFjY3VyYWN5DQogICAgLSBUbyBnZXQgY29ycmVjdCByZXNwb25zZXMsIG1pc3NlcyBhbmQgZmFsc2UgYWxhcm1zIChyZW1lbWJlciBvdXIgdHlwZSBJIGFuZCBJSSBib3hlcykNCiAgICAtIFRvIHZpc3VhbGl6ZSB0aGlzLCB3ZSB3aWxsIGV4YW1pbmUgKnJlY2VpdmVyIG9wZXJhdG9yIGN1cnZlcyogKFJPQykNCiAgICAgICAgLSBJdCBpcyB0aGUgcmVsYXRpb25zaGlwIGJldHdlZW4gY29ycmVjdCByZXNwb25zZXMgYW5kIGZhbHNlIGFsYXJtcw0KDQpgYGB7ciwgZWNobz1UUlVFLCB3YXJuaW5nPUZBTFNFLG1lc3NhZ2U9RkFMU0V9DQpsaWJyYXJ5KFJPQ1IpDQpmaXR0ZWQucmVzdWx0cyA8LSBwcmVkaWN0KExSLk1vZGVsLjIsbmV3ZGF0YT1Mb2dpc3RpY1N0dWR5MSx0eXBlPSdyZXNwb25zZScpDQpwciA8LSBwcmVkaWN0aW9uKGZpdHRlZC5yZXN1bHRzLCBMb2dpc3RpY1N0dWR5MSRIaXBzdGVyKQ0KDQpwcmYgPC0gcGVyZm9ybWFuY2UocHIsIG1lYXN1cmUgPSAidHByIiwgeC5tZWFzdXJlID0gImZwciIpDQpwbG90KHByZikNCmBgYA0KDQotIFdlIHdpbGwgY2FsY3VsYXRlIHRoZSBhcmVhIHVuZGVyIHRoZSBjdXJ2ZSB0byBnZXQgYSBnb29kIG1lYXN1cmUgb2YgYWNjdXJhY3kgKHRoZSBjbG9zZXIgdG8gMSB0aGUgYmV0dGVyKQ0KICAgIC0gQWxzbywgdGhlIGN1cnZlIHNob3VsZCBmb2xsb3cgdGhlIHNoYXBlIHlvdSBzZWUgYmVsb3cgKGlmIGl0IGlzIHRoZSBvcHBvc2l0ZSBzaGFwZSB5b3UgaGF2ZSBhIHByb2JsZW0pDQogICAgDQpgYGB7cn0NCmF1YyA8LSBwZXJmb3JtYW5jZShwciwgbWVhc3VyZSA9ICJhdWMiKQ0KYXVjIDwtIGF1Y0B5LnZhbHVlc1tbMV1dDQpwcmludChwYXN0ZSgnQXJlYSB1bmRlciB0aGUgQ3VydmUgPSAnLHJvdW5kKGF1YywzKSkpDQpgYGANCg0KIyBJbnRlcmFjdGlvbnMgDQotIEp1c3QgbGlrZSBpbiBtdWx0aXBsZSByZWdyZXNzaW9uIHlvdSB0ZXN0IGZvciBpbnRlcmFjdGlvbnMNCg0KYGBge3J9DQpMUi5Nb2RlbC4yPC1nbG0oSGlwc3Rlcn5UcmFuc3BvcnQrSXJvbnksZGF0YT1Mb2dpc3RpY1N0dWR5MSwgZmFtaWx5PWJpbm9taWFsKGxpbmsgPSAibG9naXQiKSkNCkxSLk1vZGVsLjM8LWdsbShIaXBzdGVyflRyYW5zcG9ydCpJcm9ueSxkYXRhPUxvZ2lzdGljU3R1ZHkxLCBmYW1pbHk9Ymlub21pYWwobGluayA9ICJsb2dpdCIpKQ0KYW5vdmEoTFIuTW9kZWwuMixMUi5Nb2RlbC4zLHRlc3QgPSAiQ2hpc3EiKQ0KYGBgDQoNCi0gVGhlcmUgaXMgbm8gaW1wcm92ZW1lbnQgb2YgZml0LCBidXQgaGVyZSBhcmUgdGhlIG1vZGVscyBzaWRlIGJ5IHNpZGUNCg0KYGBge3IsIGVjaG89RkFMU0UscmVzdWx0cz0nYXNpcyd9DQpsaWJyYXJ5KHN0YXJnYXplcikNCnN0YXJnYXplcihMUi5Nb2RlbC4yLExSLk1vZGVsLjMsdHlwZT0iaHRtbCIsDQogICAgICAgICAgY29sdW1uLmxhYmVscyA9IGMoIk1haW4gRWZmZWN0cyIsIkludGVyYWN0aW9uIiksDQogICAgICAgICAgaW50ZXJjZXB0LmJvdHRvbSA9IEZBTFNFLCAgc2luZ2xlLnJvdz1UUlVFLCBub3Rlcy5hcHBlbmQgPSBGQUxTRSwNCiAgICAgICAgICBvbWl0LnN0YXQ9Yygic2VyIiksIHN0YXIuY3V0b2ZmcyA9IGMoMC4wNSwgMC4wMSwgMC4wMDEpLA0KICAgICAgICAgIGhlYWRlcj1GQUxTRSkNCmBgYA0KDQotIFdlIGNhbiBwbG90IHRoZW0gKGV2ZW4gdGhvdWdoIHRoZXkgYXJlIG5vdCBzaWduaWZpY2FudCkuIA0KDQotIFdlIGNhbiB1c2UgYHNqUGxvdGAgeW91IG11c3QgbWFudWFsbHkgc2V0IHRoZSBsZXZlbCBmb3Igd2hpY2ggeW91IHdhbnQgdG8gc2VlIHRoZSBtb2RlcmF0b3IgKGxpa2Ugd2UgZGlkIHdpdGggUm9ja2NoYWxrKS4gWW91IGNhbiBzZXQgU0QgYW5kIGZvciBJcm9ueSB0aGF0IHZhbHVlcyBpcyBgciByb3VuZChzZChMb2dpc3RpY1N0dWR5MSRJcm9ueSksMilgIG9yIHdoYXRldmVyIG1vZGVyYXRvciB2YWx1ZXMgeW91IHdhbnQuICpOb3RlIHlvdSBjYW5ub3QgcGFzcyB0aGUgdmFyaWFibGVzLCB5b3UgbXVzdCBoYW5kIHR5cGUgdGhlbSouIA0KDQpgYGB7cn0NCnBsb3RfbW9kZWwoTFIuTW9kZWwuMywgdHlwZSA9ICJwcmVkIiwgDQogICAgICAgICAgIHRlcm1zID0gYygiVHJhbnNwb3J0IiwgIklyb255IFstMS44NCwxLjg0XSIpKSsNCiAgdGhlbWVfc2pwbG90MigpDQpgYGANCg0KIyMjIE90aGVyIHR5cGVzIG9mIHBsb3RzDQotIFlvdSBjYW4gYWxzbyBwbG90IGZvcmVzdCBwbG90cy4gVGhpcyBpcyB1c2VmdWwgd2hlbiB5b3UgaGF2ZSBsb3RzIG9mIHByZWRpY3RzDQotIFlvdSB3aWxsIHdhbnQgdGhlc2UgdmFsdWVzIHRvIG5vdCBvdmVybGFwIC41MCAoYW4gb2RkcyBvZiAxOjEpIG9yIGNvaW4gZmxpcA0KYGBge3J9DQpwbG90X21vZGVsKExSLk1vZGVsLjMsIHRyYW5zZm9ybSA9ICJwbG9naXMiKSt0aGVtZV9zanBsb3QyKCkNCmBgYA0KDQotIHNlZSB0aGVtIGluIG9kZCByYXRpb3MgYmVsb3cNCg0KYGBge3J9DQpwbG90X21vZGVsKExSLk1vZGVsLjMsIHZsaW5lLmNvbG9yID0gInJlZCIpK3RoZW1lX3NqcGxvdDIoKQ0KYGBgDQoNCjxzY3JpcHQ+DQogIChmdW5jdGlvbihpLHMsbyxnLHIsYSxtKXtpWydHb29nbGVBbmFseXRpY3NPYmplY3QnXT1yO2lbcl09aVtyXXx8ZnVuY3Rpb24oKXsNCiAgKGlbcl0ucT1pW3JdLnF8fFtdKS5wdXNoKGFyZ3VtZW50cyl9LGlbcl0ubD0xKm5ldyBEYXRlKCk7YT1zLmNyZWF0ZUVsZW1lbnQobyksDQogIG09cy5nZXRFbGVtZW50c0J5VGFnTmFtZShvKVswXTthLmFzeW5jPTE7YS5zcmM9ZzttLnBhcmVudE5vZGUuaW5zZXJ0QmVmb3JlKGEsbSkNCiAgfSkod2luZG93LGRvY3VtZW50LCdzY3JpcHQnLCdodHRwczovL3d3dy5nb29nbGUtYW5hbHl0aWNzLmNvbS9hbmFseXRpY3MuanMnLCdnYScpOw0KDQogIGdhKCdjcmVhdGUnLCAnVUEtOTA0MTUxNjAtMScsICdhdXRvJyk7DQogIGdhKCdzZW5kJywgJ3BhZ2V2aWV3Jyk7DQoNCjwvc2NyaXB0Pg0K