Multi-Level Modeling: Two Levels
Multi-Level Models
- Hierarchical designs: Students nested in classrooms [Clustered data]
with student-level predictors
- We will examine the effect of adding level 1 random slopes first today
- Multilevel designs: Students nested in classrooms with
student-level and classroom-level predictors
- Examine random slopes of level 2 variables
Example
- Last week we found that active learning improved math scores. We replicate this study and expand into level 2 predictions and examine random slopes.
- You want to measure how students respond to a new type of active learning method (computer-based) in math class
- You measure students math scores (DV) and the
proportion of time (IV) they spend using the computer
(which you assign)
- You expect that the more time they spend doing the active learning method, the higher their math test scores will be
- You also measure how supportive (control and/or
moderator) each student feels the teacher is about this new method.
- Also, maybe if the students feel the teacher approves of the new method, they might engage with it more
- You tell two the teachers that the active learning method works and
the other two its experimental [Told level 2 variable]
- You want to know if the teacher needs to believe the program works for it to have an effect
- You have access to different classrooms with 50 students per class
- Let’s go collect (simulate) our study.
Simulation
- Set the same slope of proportion of time (plus noise)
- Different intercept per class (plus noise) [which will implicitly correlate with supportive]
- Different slope per class on supportive (plus noise)
- Teachers in Classrooms 1 and 2 were Told the program works and 3 & 4 that it is experimental
- Set an interaction between proportion of time and supportive
#Set seed so your answers are all the same
set.seed(9)
# Sample Per class room people
n1 <- 50; n2 <- 50; n3 <- 50; n4 <- 50
N<-n1+n2+n3+n4 # Total N
# Uniform distrobution of ActiveTime per classroom
X1 <- runif(n1, 0, 1); X2 <- runif(n2, 0, 1)
X3 <- runif(n3, 0, 1); X4 <- runif(n4, 0, 1)
# Uniform distrobution of support per classroom
Z1 <- runif(n1, 0, 1); Z2 <- runif(n2, 0, 1)
Z3 <- runif(n3, 0, 1); Z4 <- runif(n4, 0, 1)
# Intercepts per classroom
B0.1 <- 80; B0.2 <- 75
B0.3 <- 65; B0.4 <- 68
# Same slope for ActiveTime per classroom + Noise
B1 <- rnorm(n1, 10, sd=2.5); B2 <- rnorm(n2, 10, sd=2.5)
B3 <- rnorm(n3, 10, sd=2.5); B4 <- rnorm(n4, 10, sd=2.5)
# different slope for support per classroom + Noise
g1 <- rnorm(n1, 10, sd=2.5); g2 <- rnorm(n2, 5, sd=2.5)
g3 <- rnorm(n3, -5, sd=2.5); g4 <- rnorm(n4, 2, sd=2.5)
# Same interaction between ActiveTime*support support per classroom + Noise
f1<- rnorm(n3, 15, sd=2.5); f2<- rnorm(n3, 15, sd=2.5)
f3<- rnorm(n3, 15, sd=2.5); f4<- rnorm(n3, 15, sd=2.5)
# noise per student within each classroom
e1 <- rnorm(n1, 0, sd=2.5); e2 <- rnorm(n2, 0, sd=2.5)
e3 <- rnorm(n3, 0, sd=2.5); e4 <- rnorm(n4, 0, sd=2.5)
# Our equation to create Y for each classroom
Y1 = B1*scale(X1,scale=F)+g1*Z1+f1*scale(X1,scale=F)*scale(Z1,scale=F) + B0.1 + e1
Y2 = B2*scale(X2,scale=F)+g2*Z2+f2*scale(X2,scale=F)*scale(Z2,scale=F) + B0.2 + e2
Y3 = B3*scale(X3,scale=F)+g3*Z3+f3*scale(X3,scale=F)*scale(Z3,scale=F) + B0.3 + e3
Y4 = B4*scale(X4,scale=F)+g4*Z4+f4*scale(X4,scale=F)*scale(Z4,scale=F) + B0.4 + e4
# Merge classrooms into 1 data.frame
MLM.Data<-data.frame(Math=c(Y1,Y2,Y3,Y4),ActiveTime=c(X1,X2,X3,X4),Support=c(Z1,Z2,Z3,Z4),
Classroom=c(rep("C1",n1),rep("C2",n2),rep("C3",n3),rep("C4",n4)),
Told=c(rep("Works",n1),rep("Works",n2),
rep("Experimental",n3),rep("Experimental",n4)),
StudentID=as.factor(1:N))Plot our Clusters
- Students nested in classrooms
library(ggplot2)
theme_set(theme_bw(base_size = 12, base_family = ""))
ClassRoom.Active <-ggplot(data = MLM.Data, aes(x = ActiveTime, y=Math,group=Classroom))+
facet_grid(Told~.)+
geom_point(aes(colour = Classroom,shape=Classroom))+
geom_smooth(method = "lm", se = TRUE, aes(colour = Classroom, linetype=Classroom))+
xlab("Active Learning Time")+ylab("Math Score")+
theme(legend.position = "top")
ClassRoom.Active
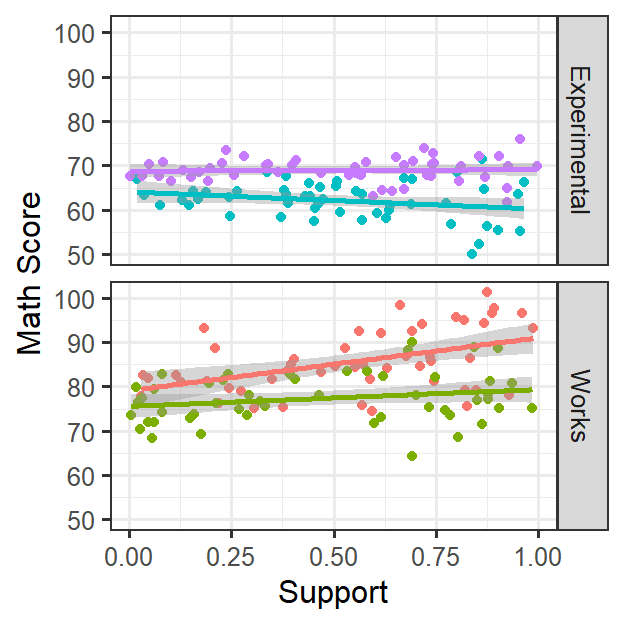
ClassRoom.Support <-ggplot(data = MLM.Data, aes(x = Support, y=Math,group=Classroom))+
facet_grid(Told~.)+
geom_point(aes(colour = Classroom, shape=Classroom))+
geom_smooth(method = "lm", se = TRUE, aes(colour = Classroom,linetype=Classroom))+
xlab("Support")+ylab("Math Score")+
theme(legend.position = "top")
ClassRoom.Support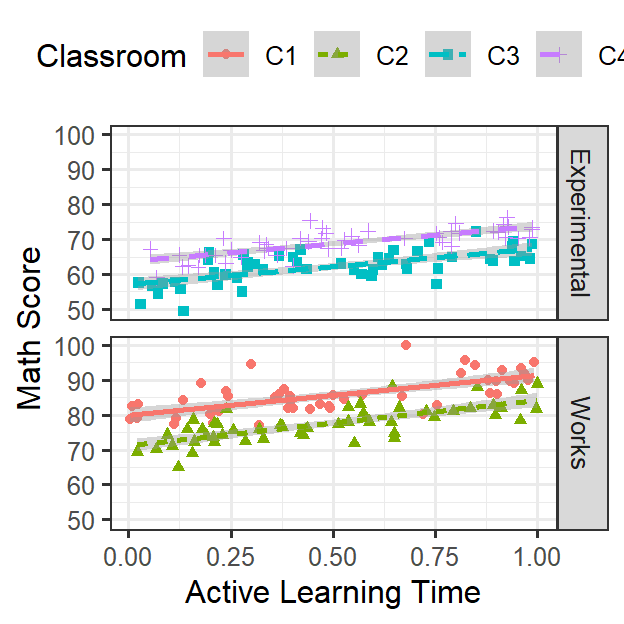
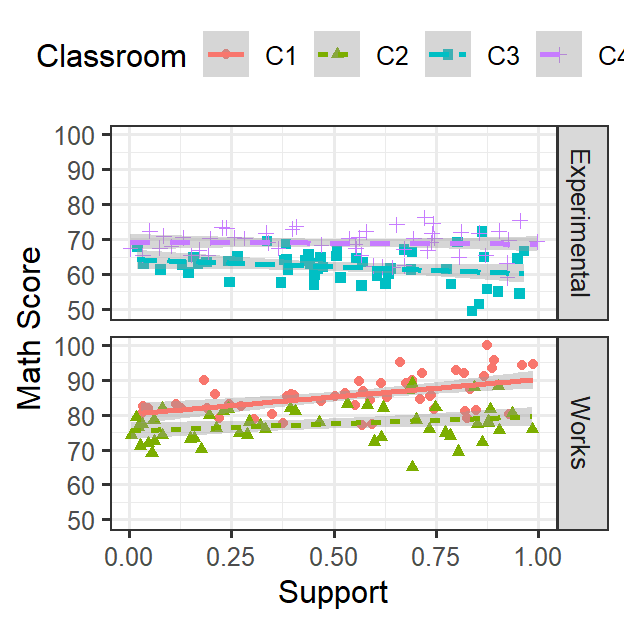
Random Intercepts & Random slopes
- Students are nested in their classroom
- Each classroom can have their own intercept [Random intercept] (like last week)
- As seen in the figure above, support each kid reported is not having
a consistent effect on math score
- This could be for many reasons (such as teachers attitude about active learning)
- You are mainly interested in the effect of active learning, thus you
want to control for support or look for moderation
- In this case, support seems related to math score, but the effect clearly varies by classroom [Random slope]
Random Slopes of Level 1
- When you set a random slope you are saying that each classroom can
have its own slope on that variable
- You are trying to capture the noise around the population slope, given the multiple measurements of the classrooms (remember which are sort of conceptually repeated measures)
- That “noise” could be systematic or unsystematic
- There are different perspectives about what should be allowed to be
a random slope
- It is clear that support slope varies as the function of the teacher (that might be systematic error that we want to control for, but in future studies, we could try to explain)
- It is clear that Active Learning times does not really vary across classrooms
Equations
Level 1 remains the same as last week
Level 2 Intercept
\[B_{0j} = \gamma_{01}W_j+\gamma_{00}+u_{0j} \]
- Where \(W_j\) = predictor of level 2 (classroom)
- Where \(\gamma_{10}\) = new fixed effect on the level 2 predictor of the classroom
- Where \(\gamma_{00}\) = intercept of the classroom
- Where \(u_{0j}\) = random deviation of the classroom intercept from fixed population intercept
- We assume students will vary randomly around the population intercept of classroom
Level 2 Slope
\[B_{1j} = \gamma_{11}W_j+\gamma_{10}+u_{1j} \]
- Where \(W_j\) = predictor of level 2 (classroom)
- Where \(\gamma_{11}\) = new fixed effect on the level 2 predictor of the classroom
- Where \(\gamma_{10}\) = slope of the classroom
- Where \(u_{1j}\) = random deviation of the classroom slope from fixed population slope
- We assume students will vary randomly around the population intercept of classroom
- Note: We would repeat this for each level of classroom we have (g, etc)
Mixed Equation
- We put level 1 and level 2 together \[y_{ij} = (\gamma_{11}W_j+\gamma_{10}+u_{1j})X_{ij} + (\gamma_{01}W_j+\gamma_{00}+u_{0j})+ r_{ij} \]
lmer function
- Review: lmer(DV ~ IV +(1|RandomFactor), …)
- (1|RandomFactor), means let the intercept of the random factor vary a function of the group (cluster).
- In our case, (1|Classroom), means that we let each classroom have its own intercept
- Random Slope & Correlated Random intercept: lmer(DV ~
IV +(1+Control|RandomFactor), …)
- We let each slope of the control variable vary as a function of the group
- Also, it means we allow each intercept of each classroom correlates with the slope of the control
- Random Slope & Non-Correlated Random intercept: lmer(DV
~ IV +(1+Control||RandomFactor), …)
- We let each slope of the control variable vary as a function of the group
- Also, it means we block the intercept of each classroom with correlating with the slope of the control
- Random Slope & No Random intercept: lmer(DV ~ IV
+(0+Control|RandomFactor), …)
- We let each slope of the control variable vary as a function of the group
- We block the model from calculating a random intercept
- We would use this model if the random slope and intercept basically yielded the same information (\(r = 1\))
Analysis of Random Level 1 Slopes
- You need to decide about centering. Grand mean or Cluster mean and for both the IV and control
- Support was measured per student, so clearly, its level 1 right…but is it? The degree of support depends on which classroom they belonged too and maybe depends on what the teacher was told about the program (Level 2)
- Activity time in this experiment was assigned condition and does not depends on the classroom, it depends on the student
- However, might how the student response to activity level (level 1) depend on (or be related to) the degree of support, maybe! Let’s find out.
Null Model
- No fixed factors (intercept only)
library(lme4) #mixed model package by Douglas Bates et al
Model.Null<-lmer(Math ~1+(1|Classroom),
data=MLM.Data, REML=FALSE)
summary(Model.Null)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ 1 + (1 | Classroom)
## Data: MLM.Data
##
## AIC BIC logLik deviance df.resid
## 1222.3 1232.2 -608.2 1216.3 197
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.66017 -0.69735 0.00735 0.68158 2.99470
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 78.44 8.857
## Residual 23.13 4.809
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.551 4.441 4.000 16.56 7.79e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1- Look at ICC: The var and sd of these values are what was seen in the table above
ICC.Model<-function(Model.Name) {
tau.Null<-as.numeric(lapply(summary(Model.Name)$varcor, diag))
sigma.Null <- as.numeric(attr(summary(Model.Name)$varcor, "sc")^2)
ICC.Null <- tau.Null/(tau.Null+sigma.Null)
return(ICC.Null)
}- \(ICC = \frac{\tau}{\tau + \sigma^2}\), where \(\tau\) = 78.443 & \(\sigma^2\) = 23.129
- The ICC = 0.7722889 > 0, meaning we were correct to think of this as MLM problem
Forward-Fitted Modeling Approach
- We want to understand how the models fit the data we will add them
in such a way to make sense of our questions and to ensure our model
fits
- We might not report all these models in a paper, but this process is helpful to understand
Add Random Intercepts
- We have to decide on centering for active learning time.
- Given it looks fairly stable across classrooms and we want to be able to talk about its as general effect, lets grand mean center it
MLM.Data$ActiveTime.GM<-scale(MLM.Data$ActiveTime,scale=F)
Model.1<-lmer(Math ~ActiveTime.GM+(1|Classroom),
data=MLM.Data, REML=FALSE)
summary(Model.1)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM + (1 | Classroom)
## Data: MLM.Data
##
## AIC BIC logLik deviance df.resid
## 1091.1 1104.3 -541.6 1083.1 196
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.5503 -0.6569 -0.0730 0.6226 3.6403
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 78.82 8.878
## Residual 11.72 3.423
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5514 4.4455 4.0000 16.55 7.82e-05 ***
## ActiveTime.GM 11.2642 0.8154 196.0050 13.81 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr)
## ActiveTm.GM 0.000- Our intercept was 73.55, which was significant
- Our slope was 11.26, which was significant
- Was this a better fit than the null model? Yes! (see below)
anova(Model.Null,Model.1)## Data: MLM.Data
## Models:
## Model.Null: Math ~ 1 + (1 | Classroom)
## Model.1: Math ~ ActiveTime.GM + (1 | Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## Model.Null 3 1222.3 1232.2 -608.17 1216.3
## Model.1 4 1091.1 1104.3 -541.55 1083.1 133.24 1 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Add Fixed Effects of Control
- We have to decide about centering
- If we center relative the cluster it will mean the degree of support each student felt relative to their teacher.
- If we center to the grand average it will mean the degree of support each student felt relative to each other.
- Lets go with cluster centering
library(plyr)
# Cluster mean
MLM.Data<-ddply(MLM.Data,.(Classroom), mutate, ClassSupport = mean(Support))
MLM.Data$Support.CC<-MLM.Data$Support-MLM.Data$ClassSupport- Only add fixed effect of support
Model.2<-lmer(Math ~ ActiveTime.GM+Support.CC+(1|Classroom),
data=MLM.Data, REML=FALSE)
summary(Model.2)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM + Support.CC + (1 | Classroom)
## Data: MLM.Data
##
## AIC BIC logLik deviance df.resid
## 1078.6 1095.1 -534.3 1068.6 195
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.9376 -0.6003 0.0133 0.5959 3.4624
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 78.84 8.879
## Residual 10.88 3.299
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5514 4.4456 4.0000 16.55 7.82e-05 ***
## ActiveTime.GM 11.4325 0.7870 196.0046 14.53 < 2e-16 ***
## Support.CC 3.1650 0.8157 196.0000 3.88 0.000143 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM
## ActiveTm.GM 0.000
## Support.CC 0.000 0.055- Our intercept was 73.55, which was significant
- Our active slope was 11.43, which was significant
- Our support slope was 3.17, which was significant
- Was this a better fit than the model 1? Yes! (see below)
anova(Model.1,Model.2)## Data: MLM.Data
## Models:
## Model.1: Math ~ ActiveTime.GM + (1 | Classroom)
## Model.2: Math ~ ActiveTime.GM + Support.CC + (1 | Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## Model.1 4 1091.1 1104.3 -541.55 1083.1
## Model.2 5 1078.6 1095.1 -534.30 1068.6 14.504 1 0.0001399 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Add Level 1 Random Slopes of Control
- But wait, support seemed to vary as a function of the class. We need to add the random slope of support
Model.3<-lmer(Math ~ ActiveTime.GM+Support.CC+(1+Support.CC|Classroom),
data=MLM.Data, REML=FALSE)
summary(Model.3)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM + Support.CC + (1 + Support.CC | Classroom)
## Data: MLM.Data
##
## AIC BIC logLik deviance df.resid
## 1064.3 1087.4 -525.2 1050.3 193
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.0342 -0.7269 0.0562 0.5989 3.1819
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Classroom (Intercept) 78.85 8.880
## Support.CC 13.27 3.643 1.00
## Residual 9.91 3.148
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5514 4.4454 4.0002 16.546 7.81e-05 ***
## ActiveTime.GM 10.9855 0.7514 196.0033 14.619 < 2e-16 ***
## Support.CC 2.9583 1.9811 3.9466 1.493 0.211
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM
## ActiveTm.GM 0.000
## Support.CC 0.918 0.021
## optimizer (nloptwrap) convergence code: 0 (OK)
## boundary (singular) fit: see help('isSingular')- Our intercept was 73.55, which was significant
- Our active slope was 10.99, which was significant
- Our support slope was 2.96, which was NOT significant
- Why did the fixed effect for support change?
- Was this a better fit than the model 2? Yes! (see below)
anova(Model.2,Model.3)## Data: MLM.Data
## Models:
## Model.2: Math ~ ActiveTime.GM + Support.CC + (1 | Classroom)
## Model.3: Math ~ ActiveTime.GM + Support.CC + (1 + Support.CC | Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## Model.2 5 1078.6 1095.1 -534.30 1068.6
## Model.3 7 1064.3 1087.4 -525.15 1050.3 18.301 2 0.0001062 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Correlation of Random Slopes
- Notice the correlation between random slope and the intercep (its
1)
- We can block it [(1+Support.CC||Classroom) OR USE (1|Classroom) + (0+Support.CC|Classroom))]
Model.3a<-lmer(Math ~ ActiveTime.GM+Support.CC+(1+Support.CC||Classroom),
data=MLM.Data, REML=FALSE)
summary(Model.3a)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM + Support.CC + (1 + Support.CC || Classroom)
## Data: MLM.Data
##
## AIC BIC logLik deviance df.resid
## 1071.8 1091.6 -529.9 1059.8 194
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.0272 -0.7003 0.0172 0.5958 3.3308
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 78.85 8.880
## Classroom.1 Support.CC 10.69 3.269
## Residual 10.06 3.171
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5514 4.4454 4.0001 16.545 7.81e-05 ***
## ActiveTime.GM 11.1567 0.7662 194.0181 14.560 < 2e-16 ***
## Support.CC 2.8910 1.8165 3.8582 1.591 0.189
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM
## ActiveTm.GM 0.000
## Support.CC 0.000 0.020- Does this change the fit?
- Note below that that 3 is a better fit than 3a,
- But Model 3 voilated the assumption. So we move on with Model 3a
anova(Model.3,Model.3a)## Data: MLM.Data
## Models:
## Model.3a: Math ~ ActiveTime.GM + Support.CC + (1 + Support.CC || Classroom)
## Model.3: Math ~ ActiveTime.GM + Support.CC + (1 + Support.CC | Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## Model.3a 6 1071.8 1091.6 -529.90 1059.8
## Model.3 7 1064.3 1087.4 -525.15 1050.3 9.491 1 0.002065 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1- Lets finally test the level 1 and 2 interaction
Model.4<-lmer(Math ~ ActiveTime.GM*Support.CC+(1+Support.CC||Classroom),
data=MLM.Data, REML=FALSE)
summary(Model.4)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM * Support.CC + (1 + Support.CC || Classroom)
## Data: MLM.Data
##
## AIC BIC logLik deviance df.resid
## 1055.0 1078.1 -520.5 1041.0 193
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.9810 -0.6582 -0.0185 0.5562 3.3230
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 76.629 8.754
## Classroom.1 Support.CC 13.796 3.714
## Residual 9.087 3.014
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.6073 4.3821 3.9997 16.797 7.37e-05 ***
## ActiveTime.GM 11.0667 0.7291 193.5746 15.178 < 2e-16 ***
## Support.CC 3.0609 2.0048 3.9023 1.527 0.203
## ActiveTime.GM:Support.CC 11.9355 2.6768 192.8449 4.459 1.40e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM Spp.CC
## ActiveTm.GM 0.000
## Support.CC 0.000 0.017
## AcT.GM:S.CC 0.003 -0.022 0.021- Our intercept was 73.61, which was significant
- Our active slope was 11.07, which was significant
- Our support slope was 3.06, which was NOT significant
- Our interaction was 3.06, which was significant
- Was this a better fit than the model 3a? Yes! (see below)
anova(Model.3a,Model.4)## Data: MLM.Data
## Models:
## Model.3a: Math ~ ActiveTime.GM + Support.CC + (1 + Support.CC || Classroom)
## Model.4: Math ~ ActiveTime.GM * Support.CC + (1 + Support.CC || Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## Model.3a 6 1071.8 1091.6 -529.9 1059.8
## Model.4 7 1055.0 1078.1 -520.5 1041.0 18.792 1 1.458e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Plot the final model
- We will plot in the traditional way
- Support (-1SD, Mean, +SD)
library(effects)
# Set levels of support
SLevels<-c(mean(MLM.Data$Support.CC)-sd(MLM.Data$Support.CC),
mean(MLM.Data$Support.CC),
mean(MLM.Data$Support.CC)+sd(MLM.Data$Support.CC))
#extract fixed effects
Results.Model.4<-Effect(c("ActiveTime.GM","Support.CC"),Model.4,
xlevels=list(ActiveTime.GM=seq(-.5,.5,.2),
Support.CC=SLevels))
#Convert to data frame for ggplot
Results.Model.4<-as.data.frame(Results.Model.4)
#Label Support for graphing
Results.Model.4$Support.F<-factor(Results.Model.4$Support.CC,
levels=SLevels,
labels=c("Low Support", "Mean Support", "High Support"))
#Plot fixed effect
Final.Fixed.Plot.1 <-ggplot(data = Results.Model.4,
aes(x = ActiveTime.GM, y =fit, group=Support.F))+
geom_line(size=2, aes(color=Support.F,linetype=Support.F))+
coord_cartesian(xlim = c(-.5, .5),ylim = c(50, 90))+
geom_ribbon(aes(ymin=fit-se, ymax=fit+se, group=Support.F, fill=Support.F),alpha=.2)+
xlab("Proportion of Time Engaged in Active Learning \nCentered")+
ylab("Math Score")+
theme(legend.position = "top",
legend.title=element_blank())
Final.Fixed.Plot.1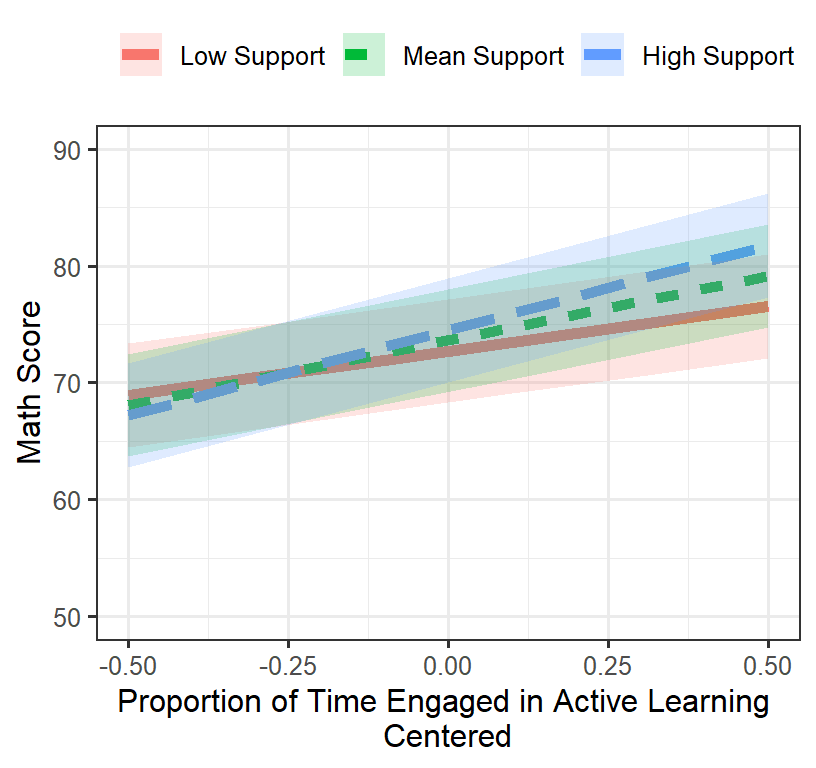
Format Output
library(texreg)
texreg(list(Model.1,Model.2,Model.3a,Model.4),
table = FALSE, use.packages = FALSE,
single.row = FALSE, stars = c(0.001, 0.01, 0.05,0.1),digits=3)Save the results of modeling
- This lets you make a Doc file
htmlreg(list(Model.1,Model.2,Model.3a,Model.4),file = "ModelResults.doc",
single.row = FALSE, stars = c(0.001, 0.01, 0.05,0.1),digits=3,
inline.css = FALSE, doctype = TRUE, html.tag = TRUE,
head.tag = TRUE, body.tag = TRUE)Re-Examine Random Effects
- Why don’t we let ActiveTime vary as a function of the classroom.
- There is of course unsystematic error (noise) that we could account for
Model.5<-lmer(Math ~ ActiveTime.GM*Support.CC+(1+ActiveTime.GM+Support.CC||Classroom),
data=MLM.Data, REML=FALSE)
summary(Model.5)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula:
## Math ~ ActiveTime.GM * Support.CC + (1 + ActiveTime.GM + Support.CC ||
## Classroom)
## Data: MLM.Data
##
## AIC BIC logLik deviance df.resid
## 1056.7 1083.1 -520.3 1040.7 192
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.8928 -0.6345 0.0072 0.5731 3.3479
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 76.7011 8.7579
## Classroom.1 ActiveTime.GM 0.9878 0.9939
## Classroom.2 Support.CC 14.5540 3.8150
## Residual 8.9915 2.9986
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.6159 4.3841 3.9997 16.792 7.38e-05 ***
## ActiveTime.GM 11.0832 0.8797 3.8113 12.599 0.000302 ***
## Support.CC 3.1048 2.0516 3.8739 1.513 0.207008
## ActiveTime.GM:Support.CC 12.0019 2.6642 188.7441 4.505 1.16e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM Spp.CC
## ActiveTm.GM 0.000
## Support.CC 0.000 0.015
## AcT.GM:S.CC 0.003 -0.017 0.021- We added alot of degrees of freedom to this model (more random slopes and more correlation between the terms)
- Will this improve the fit? In this case, NO! So adding the extra terms does not really help
anova(Model.4,Model.5)## Data: MLM.Data
## Models:
## Model.4: Math ~ ActiveTime.GM * Support.CC + (1 + Support.CC || Classroom)
## Model.5: Math ~ ActiveTime.GM * Support.CC + (1 + ActiveTime.GM + Support.CC || Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## Model.4 7 1055.0 1078.1 -520.50 1041.0
## Model.5 8 1056.7 1083.1 -520.35 1040.7 0.3082 1 0.5788- We added alot of degrees of freedom to this model (more random slopes and more correlation between the terms)
Simulation Take 2
- Set the different slope of proportion of time (plus noise)
- Different intercept per class (plus noise) [which will implicitly correlate with supportive]
- Different slope per class on supportive (plus noise)
- Set same interaction between proportion of time and supportive
- Teachers in Classrooms 1 and 2 were Told the program works and 3 & 4 that it is experimental
#Set seed so your answers are all the same
set.seed(9)
# Sample Per class room people
n1 <- 50; n2 <- 50; n3 <- 50; n4 <- 50
N<-n1+n2+n3+n4 # Total N
# Uniform distrobution of ActiveTime per classroom
X1 <- runif(n1, 0, 1); X2 <- runif(n2, 0, 1)
X3 <- runif(n3, 0, 1); X4 <- runif(n4, 0, 1)
# Uniform distrobution of support per classroom
Z1 <- runif(n1, 0, 1); Z2 <- runif(n2, 0, 1)
Z3 <- runif(n3, 0, 1); Z4 <- runif(n4, 0, 1)
# Intercepts per classroom
B0.1 <- 80; B0.2 <- 75
B0.3 <- 65; B0.4 <- 68
# Same slope for ActiveTime per classroom + Noise
B1 <- rnorm(n1, 17, sd=2.5); B2 <- rnorm(n2, 12, sd=2.5)
B3 <- rnorm(n3, 8, sd=2.5); B4 <- rnorm(n4, 4, sd=2.5)
# different slope for support per classroom + Noise
g1 <- rnorm(n1, 10, sd=2.5); g2 <- rnorm(n2, 5, sd=2.5)
g3 <- rnorm(n3, -5, sd=2.5); g4 <- rnorm(n4, 2, sd=2.5)
# Same interaction between ActiveTime*support support per classroom + Noise
f1<- rnorm(n3, 15, sd=2.5); f2<- rnorm(n3, 15, sd=2.5)
f3<- rnorm(n3, 15, sd=2.5); f4<- rnorm(n3, 15, sd=2.5)
# noise per student within each classroom
e1 <- rnorm(n1, 0, sd=2.5); e2 <- rnorm(n2, 0, sd=2.5)
e3 <- rnorm(n3, 0, sd=2.5); e4 <- rnorm(n4, 0, sd=2.5)
# Our equation to create Y for each classroom
Y1 = B1*scale(X1,scale=F)+g1*Z1+f1*scale(X1,scale=F)*scale(Z1,scale=F) + B0.1 + e1
Y2 = B2*scale(X2,scale=F)+g2*Z2+f2*scale(X2,scale=F)*scale(Z2,scale=F) + B0.2 + e2
Y3 = B3*scale(X3,scale=F)+g3*Z3+f3*scale(X3,scale=F)*scale(Z3,scale=F) + B0.3 + e3
Y4 = B4*scale(X4,scale=F)+g4*Z4+f4*scale(X4,scale=F)*scale(Z4,scale=F) + B0.4 + e4
# Merge classrooms into 1 data.frame
MLM.Data.2<-data.frame(Math=c(Y1,Y2,Y3,Y4),ActiveTime=c(X1,X2,X3,X4),Support=c(Z1,Z2,Z3,Z4),
Classroom=c(rep("C1",n1),rep("C2",n2),rep("C3",n3),rep("C4",n4)),
Told=c(rep("Works",n1),rep("Works",n2),
rep("Experimental",n3),rep("Experimental",n4)),
StudentID=as.factor(1:N))Plot our Clusters
- Students nested in classrooms
library(ggplot2)
theme_set(theme_bw(base_size = 12, base_family = ""))
ClassRoom.Active.2 <-ggplot(data = MLM.Data.2, aes(x = ActiveTime, y=Math,group=Classroom))+
facet_grid(Told~.)+
geom_point(aes(colour = Classroom))+
geom_smooth(method = "lm", se = TRUE, aes(colour = Classroom))+
xlab("Active Learning Time")+ylab("Math Score")+
theme(legend.position = "none")
ClassRoom.Active.2
ClassRoom.Support.2 <-ggplot(data = MLM.Data.2, aes(x = Support, y=Math,group=Classroom))+
facet_grid(Told~.)+
geom_point(aes(colour = Classroom))+
geom_smooth(method = "lm", se = TRUE, aes(colour = Classroom))+
xlab("Support")+ylab("Math Score")+
theme(legend.position = "none")
ClassRoom.Support.2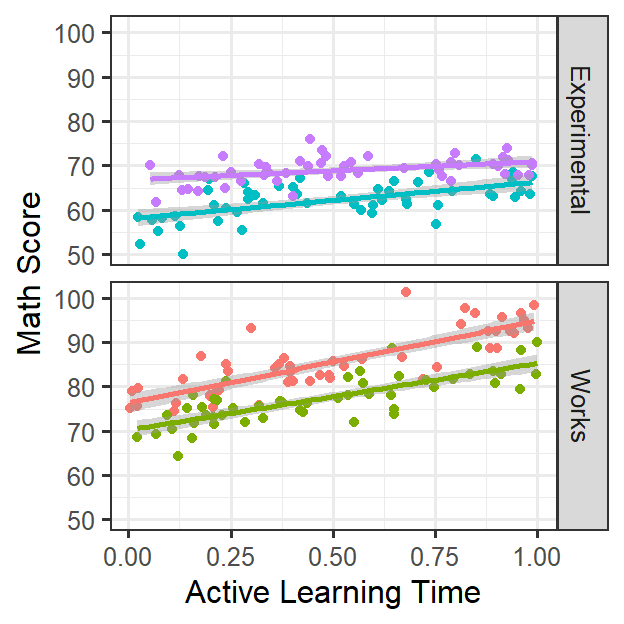
- Lets center the data just as before and do the modeling alittle faster, also lets just layer the random effects.
- As we add more random effects, watch what happens to the SE for each term
Random Intercept
MLM.Data.2$ActiveTime.GM<-scale(MLM.Data.2$ActiveTime,scale=F)
MLM.Data.2<-ddply(MLM.Data.2,.(Classroom), mutate, ClassSupport = mean(Support))
MLM.Data.2$Support.CC<-MLM.Data.2$Support-MLM.Data.2$ClassSupport
MLM.Model.1<-lmer(Math ~ ActiveTime.GM*Support.CC+(1|Classroom),
data=MLM.Data.2, REML=FALSE)Random Slope & Intercept
MLM.Model.2<-lmer(Math ~ ActiveTime.GM*Support.CC+(1+Support.CC|Classroom),
data=MLM.Data.2, REML=FALSE)Random Slopes & Intercept
MLM.Model.3<-lmer(Math ~ ActiveTime.GM*Support.CC+(1+ActiveTime.GM+Support.CC|Classroom),
data=MLM.Data.2, REML=FALSE)- See the change in SE
- Helps protect out type I error rate
library(texreg)
texreg(list(MLM.Model.1,MLM.Model.2,MLM.Model.3),
table = FALSE, use.packages = FALSE,
single.row = FALSE, stars = c(0.001, 0.01, 0.05,0.1),digits=3)Model fits
- In this case adding the L1 slope as random improved the fit
anova(MLM.Model.1,MLM.Model.2,MLM.Model.3)## Data: MLM.Data.2
## Models:
## MLM.Model.1: Math ~ ActiveTime.GM * Support.CC + (1 | Classroom)
## MLM.Model.2: Math ~ ActiveTime.GM * Support.CC + (1 + Support.CC | Classroom)
## MLM.Model.3: Math ~ ActiveTime.GM * Support.CC + (1 + ActiveTime.GM + Support.CC | Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## MLM.Model.1 6 1105.8 1125.6 -546.91 1093.8
## MLM.Model.2 8 1088.0 1114.4 -535.98 1072.0 21.848 2 1.802e-05 ***
## MLM.Model.3 11 1056.8 1093.0 -517.38 1034.8 37.205 3 4.165e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Plot the final model
- We will plot in the traditional way
- Support (-1SD, Mean, +SD)
# Set levels of support
SLevels.2<-c(mean(MLM.Data.2$Support.CC)-sd(MLM.Data.2$Support.CC),
mean(MLM.Data.2$Support.CC),
mean(MLM.Data.2$Support.CC)+sd(MLM.Data.2$Support.CC))
Results.MLM.Model.3<-Effect(c("ActiveTime.GM","Support.CC"),MLM.Model.3,
xlevels=list(ActiveTime.GM=seq(-.5,.5,.2),
Support.CC=SLevels.2))
Results.MLM.Model.3<-as.data.frame(Results.MLM.Model.3)
Results.MLM.Model.3$Support.F<-factor(Results.MLM.Model.3$Support.CC,
levels=SLevels.2,
labels=c("Low Support", "Mean Support", "High Support"))
Final.Fixed.Plot.2 <-ggplot(data = Results.MLM.Model.3,
aes(x = ActiveTime.GM, y =fit, group=Support.F))+
geom_line(size=2, aes(color=Support.F,linetype=Support.F))+
coord_cartesian(xlim = c(-.5, .5),ylim = c(50, 90))+
geom_ribbon(aes(ymin=fit-se, ymax=fit+se, group=Support.F, fill=Support.F),alpha=.2)+
xlab("Proportion of Time Engaged in Active Learning \nCentered")+
ylab("Math Score")+
theme(legend.position = "top",
legend.title=element_blank())
Final.Fixed.Plot.2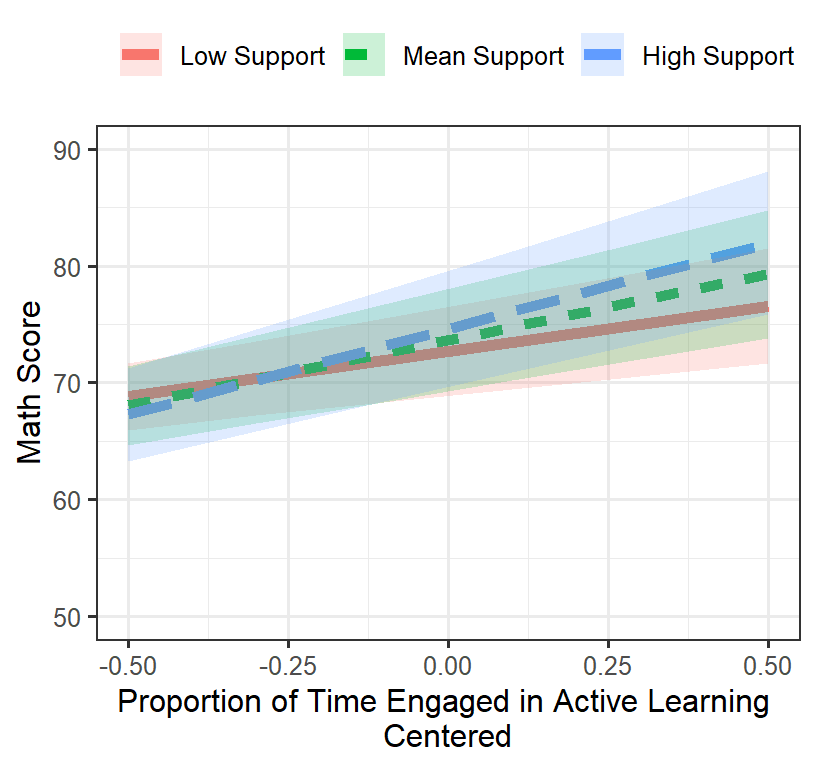
Multi-Level Model with Cross-level Interactions
- So far we examined the level 1 slopes, but there is Level 2 variable to deal with: what the teacher was told about the program
- The problem is going to be that teachers are nested in their
classrooms, so we have implicitly controlled for the intercept
differences for the Told variable
- [Note: Told has 2 measurements we will not treat it as random]
- Lets go back to simulation 1 and re-examine the results given this Level 2 factor
- First lets make the variable numeric and center it.
MLM.Data.2$Told.N<-as.numeric(as.factor(MLM.Data.2$Told))
MLM.Data.2$Told.C<-scale(MLM.Data.2$Told.N,scale=F)[,]Add Level 2 Fixed Effects
- Let’s start by working from Model 1 and add the Level 2
library(lme4)
L2test.1<-lmer(Math ~ ActiveTime.GM+Told.C
+(1|Classroom),
data=MLM.Data.2, REML=FALSE)
summary(L2test.1)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM + Told.C + (1 | Classroom)
## Data: MLM.Data.2
##
## AIC BIC logLik deviance df.resid
## 1127.7 1144.2 -558.9 1117.7 195
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.3473 -0.7294 -0.0060 0.6084 3.5710
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 12.91 3.593
## Residual 14.50 3.808
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5514 1.8164 3.9994 40.493 2.23e-06 ***
## ActiveTime.GM 11.8418 0.9071 196.0286 13.054 < 2e-16 ***
## Told.C 16.2312 3.6328 3.9996 4.468 0.0111 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM
## ActiveTm.GM 0.000
## Told.C 0.000 0.004- Our intercept was 73.55, which was significant
- Our active slope was 11.84, which was significant
- Our teacher slope was 16.23, which was significant
- Was this a better fit than the model 1? Yes! (see below)
anova(MLM.Model.1,L2test.1)## Data: MLM.Data.2
## Models:
## L2test.1: Math ~ ActiveTime.GM + Told.C + (1 | Classroom)
## MLM.Model.1: Math ~ ActiveTime.GM * Support.CC + (1 | Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## L2test.1 5 1127.7 1144.2 -558.86 1117.7
## MLM.Model.1 6 1105.8 1125.6 -546.91 1093.8 23.907 1 1.011e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Add Cross-Level Interactions
L2test.2<-lmer(Math ~ ActiveTime.GM*Told.C+(1|Classroom),
data=MLM.Data.2, REML=FALSE)
summary(L2test.2)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM * Told.C + (1 | Classroom)
## Data: MLM.Data.2
##
## AIC BIC logLik deviance df.resid
## 1091.4 1111.2 -539.7 1079.4 194
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.8458 -0.6170 -0.1151 0.6326 3.6811
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 12.88 3.589
## Residual 11.93 3.454
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5986 1.8108 3.9996 40.643 2.19e-06 ***
## ActiveTime.GM 11.6254 0.8233 196.0235 14.120 < 2e-16 ***
## Told.C 16.2274 3.6217 3.9996 4.481 0.011 *
## ActiveTime.GM:Told.C 10.7132 1.6467 196.0235 6.506 6.29e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM Told.C
## ActiveTm.GM 0.000
## Told.C 0.000 0.004
## ActT.GM:T.C 0.004 -0.040 0.000- Our intercept was 73.6, which was significant
- Our active slope was 11.63, which was significant
- Our teacher slope was 16.23, which was significant
- Our interaction slope was 10.71, which was significant
- Was this a better fit than the L2test.1? No! (see below)
anova(L2test.1,L2test.2)## Data: MLM.Data.2
## Models:
## L2test.1: Math ~ ActiveTime.GM + Told.C + (1 | Classroom)
## L2test.2: Math ~ ActiveTime.GM * Told.C + (1 | Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## L2test.1 5 1127.7 1144.2 -558.86 1117.7
## L2test.2 6 1091.4 1111.2 -539.70 1079.4 38.328 1 5.98e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Adding Back Support
- We know from the figures and previous models that support was an important variable
- What Support and told in the same model as Told we are going to have a problem because we can see in figures it is basically confounded
L2test.3<-lmer(Math ~ ActiveTime.GM*Told.C+Support.CC+(1+Support.CC|Classroom),
data=MLM.Data.2, REML=FALSE)
summary(L2test.3)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM * Told.C + Support.CC + (1 + Support.CC |
## Classroom)
## Data: MLM.Data.2
##
## AIC BIC logLik deviance df.resid
## 1065.8 1095.5 -523.9 1047.8 191
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.9037 -0.6303 -0.0269 0.5935 3.2055
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Classroom (Intercept) 49.802 7.057
## Support.CC 15.402 3.924 1.00
## Residual 9.875 3.142
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5960 3.5355 2.5652 20.816 0.000625 ***
## ActiveTime.GM 11.3120 0.7543 194.0727 14.997 < 2e-16 ***
## Told.C 4.0842 2.6563 5.7194 1.538 0.177460
## Support.CC 3.1934 2.1128 3.9054 1.511 0.206885
## ActiveTime.GM:Told.C 10.1190 1.5091 193.8334 6.705 2.14e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM Told.C Spp.CC
## ActiveTm.GM 0.000
## Told.C 0.000 0.094
## Support.CC 0.927 0.024 0.031
## ActT.GM:T.C 0.002 -0.048 -0.061 -0.036
## optimizer (nloptwrap) convergence code: 0 (OK)
## boundary (singular) fit: see help('isSingular')- Our random slopes are correlated at 1 with the random intercept. That makes sense given our figures!
- The the random slopes are confounded with intercept, lets remove the correlation
L2test.3a<-lmer(Math ~ ActiveTime.GM*Told.C+Support.CC+(1+Support.CC||Classroom),
data=MLM.Data.2, REML=FALSE)
summary(L2test.3a)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM * Told.C + Support.CC + (1 + Support.CC ||
## Classroom)
## Data: MLM.Data.2
##
## AIC BIC logLik deviance df.resid
## 1067.1 1093.5 -525.5 1051.1 192
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.9306 -0.5811 -0.0084 0.5860 3.3844
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 12.936 3.597
## Classroom.1 Support.CC 13.558 3.682
## Residual 9.937 3.152
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5975 1.8121 3.9997 40.615 2.20e-06 ***
## ActiveTime.GM 11.5009 0.7625 193.6600 15.084 < 2e-16 ***
## Told.C 16.2252 3.6242 3.9997 4.477 0.011 *
## Support.CC 3.0440 2.0045 3.8964 1.519 0.205
## ActiveTime.GM:Told.C 10.4661 1.5261 193.2390 6.858 9.17e-11 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM Told.C Spp.CC
## ActiveTm.GM 0.000
## Told.C 0.000 0.004
## Support.CC 0.000 0.019 0.000
## ActT.GM:T.C 0.004 -0.031 0.000 -0.043- Our main effect of Told came back and the model fitted better
anova(L2test.2,L2test.3a)## Data: MLM.Data.2
## Models:
## L2test.2: Math ~ ActiveTime.GM * Told.C + (1 | Classroom)
## L2test.3a: Math ~ ActiveTime.GM * Told.C + Support.CC + (1 + Support.CC || Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## L2test.2 6 1091.4 1111.2 -539.70 1079.4
## L2test.3a 8 1067.1 1093.5 -525.55 1051.1 28.306 2 7.137e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Counfounded Random Slope
- What happens if we try to interact Support with Told
- The slope on support should basically decrease or disappear (cause
we have so few classrooms and told conditions), why?
- Because those random slopes of support are not really random! They can be explained by a fixed effect what the teacher was told
- The same thing will happen if we do it with ActiveTime
L2test.4<-lmer(Math ~ ActiveTime.GM*Told.C+Support.CC*Told.C+(1+Support.CC||Classroom),
data=MLM.Data.2, REML=FALSE)
summary(L2test.4)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula:
## Math ~ ActiveTime.GM * Told.C + Support.CC * Told.C + (1 + Support.CC ||
## Classroom)
## Data: MLM.Data.2
##
## AIC BIC logLik deviance df.resid
## 1060.9 1090.6 -521.5 1042.9 191
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.0715 -0.5576 0.0091 0.6209 3.3709
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 12.937 3.597
## Classroom.1 Support.CC 0.000 0.000
## Residual 9.904 3.147
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.5981 1.8121 3.9997 40.614 2.20e-06 ***
## ActiveTime.GM 11.4833 0.7549 196.0197 15.211 < 2e-16 ***
## Told.C 16.2249 3.6243 3.9997 4.477 0.011020 *
## Support.CC 3.0568 0.7846 195.9998 3.896 0.000134 ***
## ActiveTime.GM:Told.C 10.5940 1.5099 196.0197 7.016 3.62e-11 ***
## Told.C:Support.CC 7.2397 1.5692 195.9998 4.614 7.13e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM Told.C Spp.CC AT.GM:
## ActiveTm.GM 0.000
## Told.C 0.000 0.004
## Support.CC 0.000 0.067 0.000
## ActT.GM:T.C 0.004 -0.051 0.000 -0.095
## Tld.C:Sp.CC 0.000 -0.095 0.000 -0.091 0.067
## optimizer (nloptwrap) convergence code: 0 (OK)
## boundary (singular) fit: see help('isSingular')- we can remove the random effect just test the for a three way (to speed things up)
L2test.4a<-lmer(Math ~ ActiveTime.GM*Told.C*Support.CC+(1|Classroom),
data=MLM.Data.2, REML=FALSE)
summary(L2test.4a)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: Math ~ ActiveTime.GM * Told.C * Support.CC + (1 | Classroom)
## Data: MLM.Data.2
##
## AIC BIC logLik deviance df.resid
## 1042.4 1075.4 -511.2 1022.4 190
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.7532 -0.5890 -0.0383 0.5852 3.3567
##
## Random effects:
## Groups Name Variance Std.Dev.
## Classroom (Intercept) 12.20 3.493
## Residual 8.93 2.988
## Number of obs: 200, groups: Classroom, 4
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 73.6591 1.7594 3.9983 41.867 1.95e-06
## ActiveTime.GM 11.3861 0.7177 196.0116 15.865 < 2e-16
## Told.C 16.0345 3.5187 3.9983 4.557 0.0104
## Support.CC 3.2730 0.7506 196.0002 4.361 2.09e-05
## ActiveTime.GM:Told.C 10.3461 1.4354 196.0116 7.208 1.20e-11
## ActiveTime.GM:Support.CC 12.3497 2.6575 196.1172 4.647 6.17e-06
## Told.C:Support.CC 7.9631 1.5012 196.0002 5.305 3.04e-07
## ActiveTime.GM:Told.C:Support.CC -1.1512 5.3149 196.1172 -0.217 0.8288
##
## (Intercept) ***
## ActiveTime.GM ***
## Told.C *
## Support.CC ***
## ActiveTime.GM:Told.C ***
## ActiveTime.GM:Support.CC ***
## Told.C:Support.CC ***
## ActiveTime.GM:Told.C:Support.CC
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) AcT.GM Told.C Spp.CC AcT.GM:T.C AT.GM:S T.C:S.
## ActiveTm.GM 0.000
## Told.C 0.000 0.004
## Support.CC -0.001 0.061 0.000
## ActT.GM:T.C 0.004 -0.049 0.000 -0.100
## AcT.GM:S.CC 0.008 -0.028 -0.012 0.059 -0.036
## Tld.C:Sp.CC 0.000 -0.100 -0.001 -0.077 0.061 0.102
## AT.GM:T.C:S -0.012 -0.036 0.008 0.102 -0.028 -0.076 0.059- Check fit
anova(L2test.3a,L2test.4a)## Data: MLM.Data.2
## Models:
## L2test.3a: Math ~ ActiveTime.GM * Told.C + Support.CC + (1 + Support.CC || Classroom)
## L2test.4a: Math ~ ActiveTime.GM * Told.C * Support.CC + (1 | Classroom)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## L2test.3a 8 1067.1 1093.5 -525.55 1051.1
## L2test.4a 10 1042.4 1075.4 -511.21 1022.4 28.676 2 5.931e-07 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Plot Final Model
# Set levels of support
SLevels.2<-c(mean(MLM.Data.2$Support.CC)-sd(MLM.Data.2$Support.CC),
mean(MLM.Data.2$Support.CC),
mean(MLM.Data.2$Support.CC)+sd(MLM.Data.2$Support.CC))
Results.L2test.4a<-Effect(c("ActiveTime.GM","Support.CC","Told.C"),L2test.4a,
xlevels=list(ActiveTime.GM=seq(-.5,.5,.2),
Support.CC=SLevels.2,
Told.C=c(min(MLM.Data.2$Told.C),max(MLM.Data.2$Told.C))))
Results.L2test.4a<-as.data.frame(Results.L2test.4a)
Results.L2test.4a$Support.F<-factor(Results.L2test.4a$Support.CC,
levels=SLevels.2,
labels=c("Low Support", "Mean Support", "High Support"))
Results.L2test.4a$Told.F<-factor(Results.L2test.4a$Told.C,
levels=c(min(MLM.Data.2$Told.C),max(MLM.Data.2$Told.C)),
labels=c("Experimental","Works"))
Final.Fixed.Plot.3 <-ggplot(data = Results.L2test.4a,
aes(x = ActiveTime.GM, y =fit, group=Support.F))+
facet_grid(.~Told.F)+
geom_line(size=2, aes(color=Support.F,linetype=Support.F))+
coord_cartesian(xlim = c(-.5, .5),ylim = c(50, 100))+
geom_ribbon(aes(ymin=fit-se, ymax=fit+se, group=Support.F, fill=Support.F),alpha=.2)+
xlab("Proportion of Time Engaged in Active Learning \nCentered")+
ylab("Math Score")+
theme(legend.position = "top",
legend.title=element_blank())
Final.Fixed.Plot.3
Recommenations
- Random slopes and intercepts can protect against deflation of SE and protect against type I error
- When to treat slopes and intercepts [plus their correlations] as
random?
- Ultra Conservative: Treat everything as random relative the cluster
- Often results in failure for the model to fit (you will see lots of convergence errors)
- Theory-Driven: Follow your design and theory as to what should be
random
- Sometimes theories are wrong and thus your model will not fit the data correctly
- Data Driven: Use the best random structure for your data
- Driving to the best fit does not always have meaning or make sense
- Recommendation: Balance Theory and Data-driven approaches
- Graph the data, see it follows your theories and if the random structure makes sense
- Next, work towards a random structure that is logical and fits the data
- Ultra Conservative: Treat everything as random relative the cluster
- Balancing fixed and random effects
- Sometimes your data cannot handle being treated as random and fixed
- You cannot just treat everything as random as we saw because in this crazy case it was not really random (it was all sysmatic error due). This was an extreme example in some sense, but I have seen many times when the random structure falls apart. This is very common is small N or small clusters.
- Other times you will add a random effect, and your effect of
interest will disappear
- Does that mean your results was type 1 error?
- Not always: Watch your random structure closely, the correlations, and graph the model fit
- Compare your fit to your spaghetti plots!
- Does that mean your results was type 1 error?
- Watch carefully how the fixed effect and random effect change as you add new fixed term. As you add many fixed terms (you could have multicollinearity or suppression effects)
- Sometimes your data cannot handle being treated as random and fixed
LS0tDQp0aXRsZTogJ011bHRpLUxldmVsIE1vZGVsaW5nOiBUd28gTGV2ZWxzJw0Kb3V0cHV0Og0KICBodG1sX2RvY3VtZW50Og0KICAgIGNvZGVfZG93bmxvYWQ6IHllcw0KICAgIGZvbnRzaXplOiA4cHQNCiAgICBoaWdobGlnaHQ6IHRleHRtYXRlDQogICAgbnVtYmVyX3NlY3Rpb25zOiBubw0KICAgIHRoZW1lOiBmbGF0bHkNCiAgICB0b2M6IHllcw0KICAgIHRvY19mbG9hdDoNCiAgICAgIGNvbGxhcHNlZDogbm8NCi0tLQ0KDQpgYGB7ciBzZXR1cCwgaW5jbHVkZT1GQUxTRX0NCmtuaXRyOjpvcHRzX2NodW5rJHNldChjYWNoZT1UUlVFKQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGVjaG8gPSBUUlVFKQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KG1lc3NhZ2UgPSBGQUxTRSkNCmtuaXRyOjpvcHRzX2NodW5rJHNldCh3YXJuaW5nID0gIEZBTFNFKQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGZpZy53aWR0aD00LjI1KQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGZpZy5oZWlnaHQ9NC4wKQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGZpZy5hbGlnbj0nY2VudGVyJykgDQpgYGANCg0KDQojIE11bHRpLUxldmVsIE1vZGVscw0KLSBIaWVyYXJjaGljYWwgZGVzaWduczogU3R1ZGVudHMgbmVzdGVkIGluIGNsYXNzcm9vbXMgW0NsdXN0ZXJlZCBkYXRhXSB3aXRoIHN0dWRlbnQtbGV2ZWwgcHJlZGljdG9ycyANCiAgICAtIFdlIHdpbGwgZXhhbWluZSB0aGUgZWZmZWN0IG9mIGFkZGluZyBsZXZlbCAxIHJhbmRvbSBzbG9wZXMgZmlyc3QgdG9kYXkNCi0gTXVsdGlsZXZlbCBkZXNpZ25zOiBTdHVkZW50cyBuZXN0ZWQgaW4gY2xhc3Nyb29tcyB3aXRoICpzdHVkZW50LWxldmVsKiBhbmQgKmNsYXNzcm9vbS1sZXZlbCogcHJlZGljdG9ycyANCiAgICAtIEV4YW1pbmUgcmFuZG9tIHNsb3BlcyBvZiBsZXZlbCAyIHZhcmlhYmxlcw0KDQojIyBFeGFtcGxlDQotIExhc3Qgd2VlayB3ZSBmb3VuZCB0aGF0IGFjdGl2ZSBsZWFybmluZyBpbXByb3ZlZCBtYXRoIHNjb3Jlcy4gV2UgcmVwbGljYXRlIHRoaXMgc3R1ZHkgYW5kIGV4cGFuZCBpbnRvIGxldmVsIDIgcHJlZGljdGlvbnMgYW5kIGV4YW1pbmUgcmFuZG9tIHNsb3Blcy4NCi0gWW91IHdhbnQgdG8gbWVhc3VyZSBob3cgc3R1ZGVudHMgcmVzcG9uZCB0byBhIG5ldyB0eXBlIG9mIGFjdGl2ZSBsZWFybmluZyBtZXRob2QgKGNvbXB1dGVyLWJhc2VkKSBpbiBtYXRoIGNsYXNzDQotIFlvdSBtZWFzdXJlIHN0dWRlbnRzICoqbWF0aCBzY29yZXMqKiAoRFYpIGFuZCB0aGUgKipwcm9wb3J0aW9uIG9mIHRpbWUqKiAoSVYpIHRoZXkgc3BlbmQgdXNpbmcgdGhlIGNvbXB1dGVyICh3aGljaCB5b3UgYXNzaWduKQ0KICAgIC0gWW91IGV4cGVjdCB0aGF0IHRoZSBtb3JlIHRpbWUgdGhleSBzcGVuZCBkb2luZyB0aGUgYWN0aXZlIGxlYXJuaW5nIG1ldGhvZCwgdGhlIGhpZ2hlciB0aGVpciBtYXRoIHRlc3Qgc2NvcmVzIHdpbGwgYmUNCi0gWW91IGFsc28gbWVhc3VyZSBob3cgKipzdXBwb3J0aXZlKiogKGNvbnRyb2wgYW5kL29yIG1vZGVyYXRvcikgZWFjaCBzdHVkZW50IGZlZWxzIHRoZSB0ZWFjaGVyIGlzIGFib3V0IHRoaXMgbmV3IG1ldGhvZC4gIA0KICAgIC0gQWxzbywgbWF5YmUgaWYgdGhlIHN0dWRlbnRzIGZlZWwgdGhlIHRlYWNoZXIgYXBwcm92ZXMgb2YgdGhlIG5ldyBtZXRob2QsIHRoZXkgbWlnaHQgZW5nYWdlIHdpdGggaXQgbW9yZQ0KLSBZb3UgdGVsbCB0d28gdGhlIHRlYWNoZXJzIHRoYXQgdGhlIGFjdGl2ZSBsZWFybmluZyBtZXRob2Qgd29ya3MgYW5kIHRoZSBvdGhlciB0d28gaXRzIGV4cGVyaW1lbnRhbCBbKipUb2xkKiogbGV2ZWwgMiB2YXJpYWJsZV0NCiAgICAtIFlvdSB3YW50IHRvIGtub3cgaWYgdGhlIHRlYWNoZXIgbmVlZHMgdG8gYmVsaWV2ZSB0aGUgcHJvZ3JhbSB3b3JrcyBmb3IgaXQgdG8gaGF2ZSBhbiBlZmZlY3QNCi0gWW91IGhhdmUgYWNjZXNzIHRvIGRpZmZlcmVudCBjbGFzc3Jvb21zIHdpdGggKio1MCoqIHN0dWRlbnRzIHBlciBjbGFzcw0KLSBMZXQncyBnbyAqY29sbGVjdCogKHNpbXVsYXRlKSBvdXIgc3R1ZHkuIA0KDQojIyBTaW11bGF0aW9uIA0KLSBTZXQgdGhlIHNhbWUgc2xvcGUgb2YgKipwcm9wb3J0aW9uIG9mIHRpbWUqKiAocGx1cyBub2lzZSkgDQotIERpZmZlcmVudCBpbnRlcmNlcHQgcGVyIGNsYXNzIChwbHVzIG5vaXNlKSBbd2hpY2ggd2lsbCBpbXBsaWNpdGx5IGNvcnJlbGF0ZSB3aXRoICoqc3VwcG9ydGl2ZSoqXQ0KLSBEaWZmZXJlbnQgc2xvcGUgcGVyIGNsYXNzIG9uICoqc3VwcG9ydGl2ZSoqIChwbHVzIG5vaXNlKQ0KLSBUZWFjaGVycyBpbiBDbGFzc3Jvb21zIDEgYW5kIDIgd2VyZSAqKlRvbGQqKiB0aGUgcHJvZ3JhbSAqd29ya3MqIGFuZCAzICYgNCB0aGF0IGl0IGlzICpleHBlcmltZW50YWwqDQotIFNldCBhbiBpbnRlcmFjdGlvbiBiZXR3ZWVuICoqcHJvcG9ydGlvbiBvZiB0aW1lKiogYW5kICoqc3VwcG9ydGl2ZSoqDQoNCmBgYHtyfQ0KI1NldCBzZWVkIHNvIHlvdXIgYW5zd2VycyBhcmUgYWxsIHRoZSBzYW1lDQpzZXQuc2VlZCg5KQ0KIyBTYW1wbGUgUGVyIGNsYXNzIHJvb20gcGVvcGxlDQpuMSA8LSA1MDsgbjIgPC0gNTA7IG4zIDwtIDUwOyBuNCA8LSA1MA0KTjwtbjErbjIrbjMrbjQgIyBUb3RhbCBODQojIFVuaWZvcm0gZGlzdHJvYnV0aW9uIG9mIEFjdGl2ZVRpbWUgcGVyIGNsYXNzcm9vbQ0KWDEgPC0gcnVuaWYobjEsIDAsIDEpOyBYMiA8LSBydW5pZihuMiwgMCwgMSkNClgzIDwtIHJ1bmlmKG4zLCAwLCAxKTsgWDQgPC0gcnVuaWYobjQsIDAsIDEpDQojIFVuaWZvcm0gZGlzdHJvYnV0aW9uIG9mIHN1cHBvcnQgcGVyIGNsYXNzcm9vbQ0KWjEgPC0gcnVuaWYobjEsIDAsIDEpOyBaMiA8LSBydW5pZihuMiwgMCwgMSkNClozIDwtIHJ1bmlmKG4zLCAwLCAxKTsgWjQgPC0gcnVuaWYobjQsIDAsIDEpDQojIEludGVyY2VwdHMgcGVyIGNsYXNzcm9vbQ0KQjAuMSA8LSA4MDsgQjAuMiA8LSA3NQ0KQjAuMyA8LSA2NTsgQjAuNCA8LSA2OA0KIyBTYW1lIHNsb3BlIGZvciBBY3RpdmVUaW1lIHBlciBjbGFzc3Jvb20gKyBOb2lzZQ0KQjEgPC0gcm5vcm0objEsIDEwLCBzZD0yLjUpOyBCMiA8LSBybm9ybShuMiwgMTAsIHNkPTIuNSkNCkIzIDwtIHJub3JtKG4zLCAxMCwgc2Q9Mi41KTsgQjQgPC0gcm5vcm0objQsIDEwLCBzZD0yLjUpDQojIGRpZmZlcmVudCBzbG9wZSBmb3Igc3VwcG9ydCBwZXIgY2xhc3Nyb29tICsgTm9pc2UNCmcxIDwtIHJub3JtKG4xLCAxMCwgc2Q9Mi41KTsgZzIgPC0gcm5vcm0objIsIDUsIHNkPTIuNSkNCmczIDwtIHJub3JtKG4zLCAtNSwgc2Q9Mi41KTsgZzQgPC0gcm5vcm0objQsIDIsIHNkPTIuNSkNCiMgU2FtZSBpbnRlcmFjdGlvbiBiZXR3ZWVuIEFjdGl2ZVRpbWUqc3VwcG9ydCBzdXBwb3J0IHBlciBjbGFzc3Jvb20gKyBOb2lzZQ0KZjE8LSBybm9ybShuMywgMTUsIHNkPTIuNSk7IGYyPC0gcm5vcm0objMsIDE1LCBzZD0yLjUpDQpmMzwtIHJub3JtKG4zLCAxNSwgc2Q9Mi41KTsgZjQ8LSBybm9ybShuMywgMTUsIHNkPTIuNSkNCiMgbm9pc2UgcGVyIHN0dWRlbnQgd2l0aGluIGVhY2ggY2xhc3Nyb29tDQplMSA8LSBybm9ybShuMSwgMCwgc2Q9Mi41KTsgZTIgPC0gcm5vcm0objIsIDAsIHNkPTIuNSkNCmUzIDwtIHJub3JtKG4zLCAwLCBzZD0yLjUpOyBlNCA8LSBybm9ybShuNCwgMCwgc2Q9Mi41KQ0KDQojIE91ciBlcXVhdGlvbiB0byAgY3JlYXRlIFkgZm9yIGVhY2ggY2xhc3Nyb29tDQpZMSA9IEIxKnNjYWxlKFgxLHNjYWxlPUYpK2cxKloxK2YxKnNjYWxlKFgxLHNjYWxlPUYpKnNjYWxlKFoxLHNjYWxlPUYpICsgQjAuMSArIGUxDQpZMiA9IEIyKnNjYWxlKFgyLHNjYWxlPUYpK2cyKloyK2YyKnNjYWxlKFgyLHNjYWxlPUYpKnNjYWxlKFoyLHNjYWxlPUYpICsgQjAuMiArIGUyDQpZMyA9IEIzKnNjYWxlKFgzLHNjYWxlPUYpK2czKlozK2YzKnNjYWxlKFgzLHNjYWxlPUYpKnNjYWxlKFozLHNjYWxlPUYpICsgQjAuMyArIGUzDQpZNCA9IEI0KnNjYWxlKFg0LHNjYWxlPUYpK2c0Klo0K2Y0KnNjYWxlKFg0LHNjYWxlPUYpKnNjYWxlKFo0LHNjYWxlPUYpICsgQjAuNCArIGU0DQojIE1lcmdlIGNsYXNzcm9vbXMgaW50byAxIGRhdGEuZnJhbWUNCk1MTS5EYXRhPC1kYXRhLmZyYW1lKE1hdGg9YyhZMSxZMixZMyxZNCksQWN0aXZlVGltZT1jKFgxLFgyLFgzLFg0KSxTdXBwb3J0PWMoWjEsWjIsWjMsWjQpLA0KICAgICAgICAgICAgICAgICAgICAgQ2xhc3Nyb29tPWMocmVwKCJDMSIsbjEpLHJlcCgiQzIiLG4yKSxyZXAoIkMzIixuMykscmVwKCJDNCIsbjQpKSwNCiAgICAgICAgICAgICAgICAgICAgIFRvbGQ9YyhyZXAoIldvcmtzIixuMSkscmVwKCJXb3JrcyIsbjIpLA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIHJlcCgiRXhwZXJpbWVudGFsIixuMykscmVwKCJFeHBlcmltZW50YWwiLG40KSksDQogICAgICAgICAgICAgICAgICAgICBTdHVkZW50SUQ9YXMuZmFjdG9yKDE6TikpDQpgYGANCg0KIyMjIFBsb3Qgb3VyIENsdXN0ZXJzDQotIFN0dWRlbnRzIG5lc3RlZCBpbiBjbGFzc3Jvb21zDQoNCmBgYHtyLCBvdXQud2lkdGg9Jy40OVxcbGluZXdpZHRoJywgZmlnLndpZHRoPTMuMjUsIGZpZy5oZWlnaHQ9My4yNSxmaWcuc2hvdz0naG9sZCcsZmlnLmFsaWduPSdjZW50ZXInfQ0KbGlicmFyeShnZ3Bsb3QyKQ0KdGhlbWVfc2V0KHRoZW1lX2J3KGJhc2Vfc2l6ZSA9IDEyLCBiYXNlX2ZhbWlseSA9ICIiKSkgDQoNCkNsYXNzUm9vbS5BY3RpdmUgPC1nZ3Bsb3QoZGF0YSA9IE1MTS5EYXRhLCBhZXMoeCA9IEFjdGl2ZVRpbWUsIHk9TWF0aCxncm91cD1DbGFzc3Jvb20pKSsNCiAgZmFjZXRfZ3JpZChUb2xkfi4pKw0KICBnZW9tX3BvaW50KGFlcyhjb2xvdXIgPSBDbGFzc3Jvb20sc2hhcGU9Q2xhc3Nyb29tKSkrDQogIGdlb21fc21vb3RoKG1ldGhvZCA9ICJsbSIsIHNlID0gVFJVRSwgYWVzKGNvbG91ciA9IENsYXNzcm9vbSwgbGluZXR5cGU9Q2xhc3Nyb29tKSkrDQogIHhsYWIoIkFjdGl2ZSBMZWFybmluZyBUaW1lIikreWxhYigiTWF0aCBTY29yZSIpKw0KICB0aGVtZShsZWdlbmQucG9zaXRpb24gPSAidG9wIikNCkNsYXNzUm9vbS5BY3RpdmUNCg0KQ2xhc3NSb29tLlN1cHBvcnQgPC1nZ3Bsb3QoZGF0YSA9IE1MTS5EYXRhLCBhZXMoeCA9IFN1cHBvcnQsIHk9TWF0aCxncm91cD1DbGFzc3Jvb20pKSsNCiBmYWNldF9ncmlkKFRvbGR+LikrDQogIGdlb21fcG9pbnQoYWVzKGNvbG91ciA9IENsYXNzcm9vbSwgc2hhcGU9Q2xhc3Nyb29tKSkrDQogIGdlb21fc21vb3RoKG1ldGhvZCA9ICJsbSIsIHNlID0gVFJVRSwgYWVzKGNvbG91ciA9IENsYXNzcm9vbSxsaW5ldHlwZT1DbGFzc3Jvb20pKSsNCiAgeGxhYigiU3VwcG9ydCIpK3lsYWIoIk1hdGggU2NvcmUiKSsNCiAgdGhlbWUobGVnZW5kLnBvc2l0aW9uID0gInRvcCIpDQpDbGFzc1Jvb20uU3VwcG9ydA0KYGBgDQoNCiMgUmFuZG9tIEludGVyY2VwdHMgJiBSYW5kb20gc2xvcGVzDQotIFN0dWRlbnRzIGFyZSBuZXN0ZWQgaW4gdGhlaXIgY2xhc3Nyb29tIA0KLSBFYWNoIGNsYXNzcm9vbSBjYW4gaGF2ZSB0aGVpciBvd24gaW50ZXJjZXB0IFsqKlJhbmRvbSBpbnRlcmNlcHQqKl0gKGxpa2UgbGFzdCB3ZWVrKQ0KLSBBcyBzZWVuIGluIHRoZSBmaWd1cmUgYWJvdmUsIHN1cHBvcnQgZWFjaCBraWQgcmVwb3J0ZWQgaXMgbm90IGhhdmluZyBhIGNvbnNpc3RlbnQgZWZmZWN0IG9uIG1hdGggc2NvcmUNCiAgICAtIFRoaXMgY291bGQgYmUgZm9yIG1hbnkgcmVhc29ucyAoc3VjaCBhcyB0ZWFjaGVycyBhdHRpdHVkZSBhYm91dCBhY3RpdmUgbGVhcm5pbmcpDQogICAgLSBZb3UgYXJlIG1haW5seSBpbnRlcmVzdGVkIGluIHRoZSBlZmZlY3Qgb2YgYWN0aXZlIGxlYXJuaW5nLCB0aHVzIHlvdSB3YW50IHRvIGNvbnRyb2wgZm9yIHN1cHBvcnQgb3IgbG9vayBmb3IgbW9kZXJhdGlvbg0KICAgICAgICAtIEluIHRoaXMgY2FzZSwgc3VwcG9ydCBzZWVtcyByZWxhdGVkIHRvIG1hdGggc2NvcmUsIGJ1dCB0aGUgZWZmZWN0IGNsZWFybHkgdmFyaWVzIGJ5IGNsYXNzcm9vbSBbKipSYW5kb20gc2xvcGUqKl0NCg0KDQojIyBSYW5kb20gU2xvcGVzIG9mIExldmVsIDEgDQotIFdoZW4geW91IHNldCBhIHJhbmRvbSBzbG9wZSB5b3UgYXJlIHNheWluZyB0aGF0IGVhY2ggY2xhc3Nyb29tIGNhbiBoYXZlIGl0cyBvd24gc2xvcGUgb24gdGhhdCB2YXJpYWJsZQ0KICAgIC0gWW91IGFyZSB0cnlpbmcgdG8gY2FwdHVyZSB0aGUgbm9pc2UgYXJvdW5kIHRoZSBwb3B1bGF0aW9uIHNsb3BlLCBnaXZlbiB0aGUgbXVsdGlwbGUgbWVhc3VyZW1lbnRzIG9mIHRoZSBjbGFzc3Jvb21zIChyZW1lbWJlciB3aGljaCBhcmUgc29ydCBvZiBjb25jZXB0dWFsbHkgKnJlcGVhdGVkIG1lYXN1cmVzKikNCiAgICAtIFRoYXQgIm5vaXNlIiBjb3VsZCBiZSBzeXN0ZW1hdGljIG9yIHVuc3lzdGVtYXRpYw0KLSBUaGVyZSBhcmUgZGlmZmVyZW50IHBlcnNwZWN0aXZlcyBhYm91dCB3aGF0IHNob3VsZCBiZSBhbGxvd2VkIHRvIGJlIGEgcmFuZG9tIHNsb3BlDQogICAgLSBJdCBpcyBjbGVhciB0aGF0ICoqc3VwcG9ydCoqIHNsb3BlIHZhcmllcyBhcyB0aGUgZnVuY3Rpb24gb2YgdGhlIHRlYWNoZXIgKHRoYXQgbWlnaHQgYmUgc3lzdGVtYXRpYyBlcnJvciB0aGF0IHdlIHdhbnQgdG8gY29udHJvbCBmb3IsIGJ1dCBpbiBmdXR1cmUgc3R1ZGllcywgd2UgY291bGQgdHJ5IHRvIGV4cGxhaW4pDQogICAgLSBJdCBpcyBjbGVhciB0aGF0ICoqQWN0aXZlIExlYXJuaW5nIHRpbWVzKiogZG9lcyBub3QgcmVhbGx5IHZhcnkgYWNyb3NzIGNsYXNzcm9vbXMNCg0KIyMgRXF1YXRpb25zDQoqTGV2ZWwgMSogcmVtYWlucyB0aGUgc2FtZSBhcyBsYXN0IHdlZWsNCg0KKkxldmVsIDIgSW50ZXJjZXB0KiANCg0KJCRCX3swan0gPSBcZ2FtbWFfezAxfVdfaitcZ2FtbWFfezAwfSt1X3swan0gJCQNCg0KLSBXaGVyZSAkV19qJCA9IHByZWRpY3RvciBvZiBsZXZlbCAyIChjbGFzc3Jvb20pDQotIFdoZXJlICRcZ2FtbWFfezEwfSQgPSBuZXcgZml4ZWQgZWZmZWN0IG9uIHRoZSBsZXZlbCAyIHByZWRpY3RvciBvZiB0aGUgY2xhc3Nyb29tDQotIFdoZXJlICRcZ2FtbWFfezAwfSQgPSBpbnRlcmNlcHQgb2YgdGhlIGNsYXNzcm9vbQ0KLSBXaGVyZSAkdV97MGp9JCA9IHJhbmRvbSBkZXZpYXRpb24gb2YgdGhlIGNsYXNzcm9vbSBpbnRlcmNlcHQgZnJvbSBmaXhlZCBwb3B1bGF0aW9uIGludGVyY2VwdA0KLSBXZSBhc3N1bWUgc3R1ZGVudHMgd2lsbCB2YXJ5IHJhbmRvbWx5IGFyb3VuZCB0aGUgcG9wdWxhdGlvbiBpbnRlcmNlcHQgb2YgY2xhc3Nyb29tDQogDQoqTGV2ZWwgMiBTbG9wZSogDQoNCiQkQl97MWp9ID0gXGdhbW1hX3sxMX1XX2orXGdhbW1hX3sxMH0rdV97MWp9ICQkDQoNCi0gV2hlcmUgJFdfaiQgPSBwcmVkaWN0b3Igb2YgbGV2ZWwgMiAoY2xhc3Nyb29tKQ0KLSBXaGVyZSAkXGdhbW1hX3sxMX0kID0gbmV3IGZpeGVkIGVmZmVjdCBvbiB0aGUgbGV2ZWwgMiBwcmVkaWN0b3Igb2YgdGhlIGNsYXNzcm9vbQ0KLSBXaGVyZSAkXGdhbW1hX3sxMH0kID0gc2xvcGUgb2YgdGhlIGNsYXNzcm9vbQ0KLSBXaGVyZSAkdV97MWp9JCA9IHJhbmRvbSBkZXZpYXRpb24gb2YgdGhlIGNsYXNzcm9vbSBzbG9wZSBmcm9tIGZpeGVkIHBvcHVsYXRpb24gc2xvcGUNCi0gV2UgYXNzdW1lIHN0dWRlbnRzIHdpbGwgdmFyeSByYW5kb21seSBhcm91bmQgdGhlIHBvcHVsYXRpb24gaW50ZXJjZXB0IG9mIGNsYXNzcm9vbQ0KLSBOb3RlOiBXZSB3b3VsZCByZXBlYXQgdGhpcyBmb3IgZWFjaCBsZXZlbCBvZiBjbGFzc3Jvb20gd2UgaGF2ZSAoZywgZXRjKQ0KDQojIyMgTWl4ZWQgRXF1YXRpb24NCi0gV2UgcHV0IGxldmVsIDEgYW5kIGxldmVsIDIgdG9nZXRoZXINCiQkeV97aWp9ID0gKFxnYW1tYV97MTF9V19qK1xnYW1tYV97MTB9K3VfezFqfSlYX3tpan0gKyAgKFxnYW1tYV97MDF9V19qK1xnYW1tYV97MDB9K3VfezBqfSkrIHJfe2lqfSAkJA0KDQoNCiMjIGxtZXIgZnVuY3Rpb24NCi0gUmV2aWV3OiBsbWVyKERWIH4gSVYgKygxfFJhbmRvbUZhY3RvciksIC4uLikNCiAgICAtICgxfFJhbmRvbUZhY3RvciksIG1lYW5zIGxldCB0aGUgaW50ZXJjZXB0IG9mIHRoZSByYW5kb20gZmFjdG9yIHZhcnkgYSBmdW5jdGlvbiBvZiB0aGUgZ3JvdXAgKGNsdXN0ZXIpLiANCiAgICAtIEluIG91ciBjYXNlLCAoMXxDbGFzc3Jvb20pLCBtZWFucyB0aGF0IHdlIGxldCBlYWNoIGNsYXNzcm9vbSBoYXZlIGl0cyBvd24gaW50ZXJjZXB0DQotICpSYW5kb20gU2xvcGUgJiBDb3JyZWxhdGVkIFJhbmRvbSBpbnRlcmNlcHQqOiBsbWVyKERWIH4gSVYgKygxK0NvbnRyb2x8UmFuZG9tRmFjdG9yKSwgLi4uKSAgICANCiAgICAtIFdlIGxldCBlYWNoIHNsb3BlIG9mIHRoZSBjb250cm9sIHZhcmlhYmxlIHZhcnkgYXMgYSBmdW5jdGlvbiBvZiB0aGUgZ3JvdXANCiAgICAtIEFsc28sIGl0IG1lYW5zIHdlICphbGxvdyogZWFjaCBpbnRlcmNlcHQgb2YgZWFjaCBjbGFzc3Jvb20gY29ycmVsYXRlcyB3aXRoIHRoZSBzbG9wZSBvZiB0aGUgY29udHJvbA0KLSAqUmFuZG9tIFNsb3BlICYgTm9uLUNvcnJlbGF0ZWQgUmFuZG9tIGludGVyY2VwdCo6IGxtZXIoRFYgfiBJViArKDErQ29udHJvbHx8UmFuZG9tRmFjdG9yKSwgLi4uKSAgICANCiAgICAtIFdlIGxldCBlYWNoIHNsb3BlIG9mIHRoZSBjb250cm9sIHZhcmlhYmxlIHZhcnkgYXMgYSBmdW5jdGlvbiBvZiB0aGUgZ3JvdXANCiAgICAtIEFsc28sIGl0IG1lYW5zIHdlICpibG9jayogdGhlIGludGVyY2VwdCBvZiBlYWNoIGNsYXNzcm9vbSB3aXRoIGNvcnJlbGF0aW5nIHdpdGggdGhlIHNsb3BlIG9mIHRoZSBjb250cm9sDQotICpSYW5kb20gU2xvcGUgJiBObyBSYW5kb20gaW50ZXJjZXB0KjogbG1lcihEViB+IElWICsoMCtDb250cm9sfFJhbmRvbUZhY3RvciksIC4uLikgICAgDQogICAgLSBXZSBsZXQgZWFjaCBzbG9wZSBvZiB0aGUgY29udHJvbCB2YXJpYWJsZSB2YXJ5IGFzIGEgZnVuY3Rpb24gb2YgdGhlIGdyb3VwDQogICAgLSBXZSAqYmxvY2sqIHRoZSBtb2RlbCBmcm9tIGNhbGN1bGF0aW5nIGEgcmFuZG9tIGludGVyY2VwdCANCiAgICAgICAgLSBXZSB3b3VsZCB1c2UgdGhpcyBtb2RlbCBpZiB0aGUgcmFuZG9tIHNsb3BlIGFuZCBpbnRlcmNlcHQgYmFzaWNhbGx5IHlpZWxkZWQgdGhlIHNhbWUgaW5mb3JtYXRpb24gKCRyID0gMSQpIA0KICAgICAgICANCiMjIEFuYWx5c2lzIG9mIFJhbmRvbSBMZXZlbCAxIFNsb3Blcw0KLSBZb3UgbmVlZCB0byBkZWNpZGUgYWJvdXQgY2VudGVyaW5nLiBHcmFuZCBtZWFuIG9yIENsdXN0ZXIgbWVhbiBhbmQgZm9yIGJvdGggdGhlIElWIGFuZCBjb250cm9sDQotIFN1cHBvcnQgd2FzIG1lYXN1cmVkIHBlciBzdHVkZW50LCBzbyBjbGVhcmx5LCBpdHMgbGV2ZWwgMSByaWdodC4uLmJ1dCBpcyBpdD8gVGhlIGRlZ3JlZSBvZiBzdXBwb3J0IGRlcGVuZHMgb24gd2hpY2ggY2xhc3Nyb29tIHRoZXkgYmVsb25nZWQgdG9vIGFuZCBtYXliZSBkZXBlbmRzIG9uIHdoYXQgdGhlIHRlYWNoZXIgd2FzIHRvbGQgYWJvdXQgdGhlIHByb2dyYW0gKCoqTGV2ZWwgMioqKQ0KLSBBY3Rpdml0eSB0aW1lIGluIHRoaXMgZXhwZXJpbWVudCB3YXMgYXNzaWduZWQgY29uZGl0aW9uIGFuZCBkb2VzIG5vdCBkZXBlbmRzIG9uIHRoZSBjbGFzc3Jvb20sIGl0IGRlcGVuZHMgb24gdGhlIHN0dWRlbnQgDQotIEhvd2V2ZXIsIG1pZ2h0IGhvdyB0aGUgc3R1ZGVudCByZXNwb25zZSB0byBhY3Rpdml0eSBsZXZlbCAoKipsZXZlbCAxKiopIGRlcGVuZCBvbiAob3IgYmUgcmVsYXRlZCB0bykgdGhlIGRlZ3JlZSBvZiBzdXBwb3J0LCBtYXliZSEgTGV0J3MgZmluZCBvdXQuIA0KDQojIyMgTnVsbCBNb2RlbA0KLSBObyBmaXhlZCBmYWN0b3JzIChpbnRlcmNlcHQgb25seSkNCg0KYGBge3J9DQpsaWJyYXJ5KGxtZTQpICAgICAjbWl4ZWQgbW9kZWwgcGFja2FnZSBieSBEb3VnbGFzIEJhdGVzIGV0IGFsDQpNb2RlbC5OdWxsPC1sbWVyKE1hdGggfjErKDF8Q2xhc3Nyb29tKSwgIA0KICAgICAgICAgICAgICAgICAgIGRhdGE9TUxNLkRhdGEsIFJFTUw9RkFMU0UpDQpzdW1tYXJ5KE1vZGVsLk51bGwpDQpgYGANCg0KLSBMb29rIGF0IElDQzogVGhlIHZhciBhbmQgc2Qgb2YgdGhlc2UgdmFsdWVzIGFyZSB3aGF0IHdhcyBzZWVuIGluIHRoZSB0YWJsZSBhYm92ZQ0KDQpgYGB7cn0NCklDQy5Nb2RlbDwtZnVuY3Rpb24oTW9kZWwuTmFtZSkgew0KICB0YXUuTnVsbDwtYXMubnVtZXJpYyhsYXBwbHkoc3VtbWFyeShNb2RlbC5OYW1lKSR2YXJjb3IsIGRpYWcpKQ0KICBzaWdtYS5OdWxsIDwtIGFzLm51bWVyaWMoYXR0cihzdW1tYXJ5KE1vZGVsLk5hbWUpJHZhcmNvciwgInNjIileMikNCiAgSUNDLk51bGwgPC0gdGF1Lk51bGwvKHRhdS5OdWxsK3NpZ21hLk51bGwpDQogIHJldHVybihJQ0MuTnVsbCkNCn0NCmBgYA0KDQotICRJQ0MgPSBcZnJhY3tcdGF1fXtcdGF1ICsgXHNpZ21hXjJ9JCwgd2hlcmUgJFx0YXUkID0gYHIgcm91bmQoYXMubnVtZXJpYyhsYXBwbHkoc3VtbWFyeShNb2RlbC5OdWxsKSR2YXJjb3IsIGRpYWcpKSwzKWAgJiAkXHNpZ21hXjIkID0gYHIgcm91bmQoYXMubnVtZXJpYyhhdHRyKHN1bW1hcnkoTW9kZWwuTnVsbCkkdmFyY29yLCAic2MiKV4yKSwzKWANCi0gVGhlIElDQyA9IGByIElDQy5Nb2RlbChNb2RlbC5OdWxsKWAgPiAwLCBtZWFuaW5nIHdlIHdlcmUgY29ycmVjdCB0byB0aGluayBvZiB0aGlzIGFzIE1MTSBwcm9ibGVtDQoNCiMjIyBGb3J3YXJkLUZpdHRlZCBNb2RlbGluZyBBcHByb2FjaA0KLSBXZSB3YW50IHRvIHVuZGVyc3RhbmQgaG93IHRoZSBtb2RlbHMgZml0IHRoZSBkYXRhIHdlIHdpbGwgYWRkIHRoZW0gaW4gc3VjaCBhIHdheSB0byBtYWtlIHNlbnNlIG9mIG91ciBxdWVzdGlvbnMgYW5kIHRvIGVuc3VyZSBvdXIgbW9kZWwgZml0cw0KICAgIC0gV2UgbWlnaHQgbm90IHJlcG9ydCBhbGwgdGhlc2UgbW9kZWxzIGluIGEgcGFwZXIsIGJ1dCB0aGlzIHByb2Nlc3MgaXMgaGVscGZ1bCB0byB1bmRlcnN0YW5kIA0KDQojIyMjIEFkZCBSYW5kb20gSW50ZXJjZXB0cw0KLSBXZSBoYXZlIHRvIGRlY2lkZSBvbiBjZW50ZXJpbmcgZm9yIGFjdGl2ZSBsZWFybmluZyB0aW1lLg0KICAgIC0gR2l2ZW4gaXQgbG9va3MgZmFpcmx5IHN0YWJsZSBhY3Jvc3MgY2xhc3Nyb29tcyBhbmQgd2Ugd2FudCB0byBiZSBhYmxlIHRvIHRhbGsgYWJvdXQgaXRzIGFzIGdlbmVyYWwgZWZmZWN0LCBsZXRzIGdyYW5kIG1lYW4gY2VudGVyIGl0DQogICAgDQpgYGB7cn0NCk1MTS5EYXRhJEFjdGl2ZVRpbWUuR008LXNjYWxlKE1MTS5EYXRhJEFjdGl2ZVRpbWUsc2NhbGU9RikNCg0KTW9kZWwuMTwtbG1lcihNYXRoIH5BY3RpdmVUaW1lLkdNKygxfENsYXNzcm9vbSksICANCiAgICAgICAgICAgICAgICAgICBkYXRhPU1MTS5EYXRhLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShNb2RlbC4xKQ0KYGBgDQoNCmBgYHtyLCBlY2hvPUZBTFNFfQ0KSTA8LXJvdW5kKHVubmFtZShmaXhlZihNb2RlbC4xKVsxXSksMikNClNBMDwtcm91bmQodW5uYW1lKGZpeGVmKE1vZGVsLjEpWzJdKSwyKQ0KYGBgDQoNCg0KLSBPdXIgaW50ZXJjZXB0IHdhcyBgciBJMGAsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBPdXIgc2xvcGUgd2FzIGByIFNBMGAsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBXYXMgdGhpcyBhIGJldHRlciBmaXQgdGhhbiB0aGUgbnVsbCBtb2RlbD8gWWVzISAoc2VlIGJlbG93KQ0KDQpgYGB7cn0NCmFub3ZhKE1vZGVsLk51bGwsTW9kZWwuMSkNCmBgYA0KDQoNCiMjIyMgQWRkIEZpeGVkIEVmZmVjdHMgb2YgQ29udHJvbA0KLSBXZSBoYXZlIHRvIGRlY2lkZSBhYm91dCBjZW50ZXJpbmcNCiAgICAtIElmIHdlIGNlbnRlciByZWxhdGl2ZSB0aGUgY2x1c3RlciBpdCB3aWxsIG1lYW4gdGhlIGRlZ3JlZSBvZiBzdXBwb3J0IGVhY2ggc3R1ZGVudCBmZWx0IHJlbGF0aXZlIHRvIHRoZWlyIHRlYWNoZXIuIA0KICAgIC0gSWYgd2UgY2VudGVyIHRvIHRoZSBncmFuZCBhdmVyYWdlIGl0IHdpbGwgbWVhbiB0aGUgZGVncmVlIG9mIHN1cHBvcnQgZWFjaCBzdHVkZW50IGZlbHQgcmVsYXRpdmUgdG8gZWFjaCBvdGhlci4gDQotICpMZXRzIGdvIHdpdGggY2x1c3RlciBjZW50ZXJpbmcqDQoNCmBgYHtyfQ0KbGlicmFyeShwbHlyKQ0KIyBDbHVzdGVyIG1lYW4NCk1MTS5EYXRhPC1kZHBseShNTE0uRGF0YSwuKENsYXNzcm9vbSksIG11dGF0ZSwgQ2xhc3NTdXBwb3J0ID0gbWVhbihTdXBwb3J0KSkNCk1MTS5EYXRhJFN1cHBvcnQuQ0M8LU1MTS5EYXRhJFN1cHBvcnQtTUxNLkRhdGEkQ2xhc3NTdXBwb3J0DQpgYGANCg0KLSBPbmx5IGFkZCBmaXhlZCBlZmZlY3Qgb2Ygc3VwcG9ydA0KDQpgYGB7cn0NCk1vZGVsLjI8LWxtZXIoTWF0aCB+IEFjdGl2ZVRpbWUuR00rU3VwcG9ydC5DQysoMXxDbGFzc3Jvb20pLCAgDQogICAgICAgICAgICAgIGRhdGE9TUxNLkRhdGEsIFJFTUw9RkFMU0UpDQpzdW1tYXJ5KE1vZGVsLjIpDQpgYGANCg0KYGBge3IsIGVjaG89RkFMU0V9DQpNSTI8LXJvdW5kKHVubmFtZShmaXhlZihNb2RlbC4yKVsxXSksMikNCk1TQTI8LXJvdW5kKHVubmFtZShmaXhlZihNb2RlbC4yKVsyXSksMikNCk1TUzI8LXJvdW5kKHVubmFtZShmaXhlZihNb2RlbC4yKVszXSksMikNCmBgYA0KDQoNCi0gT3VyIGludGVyY2VwdCB3YXMgYHIgTUkyYCwgd2hpY2ggd2FzIHNpZ25pZmljYW50DQotIE91ciBhY3RpdmUgc2xvcGUgd2FzIGByIE1TQTJgLCB3aGljaCB3YXMgc2lnbmlmaWNhbnQNCi0gT3VyIHN1cHBvcnQgc2xvcGUgd2FzIGByIE1TUzJgLCB3aGljaCB3YXMgc2lnbmlmaWNhbnQNCi0gV2FzIHRoaXMgYSBiZXR0ZXIgZml0IHRoYW4gdGhlIG1vZGVsIDE/IFllcyEgKHNlZSBiZWxvdykNCg0KYGBge3J9DQphbm92YShNb2RlbC4xLE1vZGVsLjIpDQpgYGANCg0KIyMjIyBBZGQgTGV2ZWwgMSBSYW5kb20gU2xvcGVzIG9mIENvbnRyb2wNCi0gQnV0IHdhaXQsIHN1cHBvcnQgc2VlbWVkIHRvIHZhcnkgYXMgYSBmdW5jdGlvbiBvZiB0aGUgY2xhc3MuIFdlIG5lZWQgdG8gYWRkIHRoZSByYW5kb20gc2xvcGUgb2Ygc3VwcG9ydA0KDQpgYGB7cn0NCk1vZGVsLjM8LWxtZXIoTWF0aCB+IEFjdGl2ZVRpbWUuR00rU3VwcG9ydC5DQysoMStTdXBwb3J0LkNDfENsYXNzcm9vbSksICANCiAgICAgICAgICAgICAgZGF0YT1NTE0uRGF0YSwgUkVNTD1GQUxTRSkNCnN1bW1hcnkoTW9kZWwuMykNCmBgYA0KDQpgYGB7ciwgZWNobz1GQUxTRX0NCk1JMzwtcm91bmQodW5uYW1lKGZpeGVmKE1vZGVsLjMpWzFdKSwyKQ0KTVNBMzwtcm91bmQodW5uYW1lKGZpeGVmKE1vZGVsLjMpWzJdKSwyKQ0KTVNTMzwtcm91bmQodW5uYW1lKGZpeGVmKE1vZGVsLjMpWzNdKSwyKQ0KYGBgDQoNCg0KLSBPdXIgaW50ZXJjZXB0IHdhcyBgciBNSTNgLCB3aGljaCB3YXMgc2lnbmlmaWNhbnQNCi0gT3VyIGFjdGl2ZSBzbG9wZSB3YXMgYHIgTVNBM2AsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBPdXIgc3VwcG9ydCBzbG9wZSB3YXMgYHIgTVNTM2AsIHdoaWNoIHdhcyBOT1Qgc2lnbmlmaWNhbnQNCiAgICAtIFdoeSBkaWQgdGhlIGZpeGVkIGVmZmVjdCBmb3Igc3VwcG9ydCBjaGFuZ2U/IA0KLSBXYXMgdGhpcyBhIGJldHRlciBmaXQgdGhhbiB0aGUgbW9kZWwgMj8gWWVzISAoc2VlIGJlbG93KQ0KDQpgYGB7cn0NCmFub3ZhKE1vZGVsLjIsTW9kZWwuMykNCmBgYA0KDQojIyMjIENvcnJlbGF0aW9uIG9mIFJhbmRvbSBTbG9wZXMgDQotIE5vdGljZSB0aGUgY29ycmVsYXRpb24gYmV0d2VlbiByYW5kb20gc2xvcGUgYW5kIHRoZSBpbnRlcmNlcCAoaXRzIDEpICANCi0gV2UgY2FuIGJsb2NrIGl0IFsoMStTdXBwb3J0LkNDfHxDbGFzc3Jvb20pIE9SIFVTRSAoMXxDbGFzc3Jvb20pICsgKDArU3VwcG9ydC5DQ3xDbGFzc3Jvb20pKV0NCg0KYGBge3J9DQpNb2RlbC4zYTwtbG1lcihNYXRoIH4gQWN0aXZlVGltZS5HTStTdXBwb3J0LkNDKygxK1N1cHBvcnQuQ0N8fENsYXNzcm9vbSksICANCiAgICAgICAgICAgICAgZGF0YT1NTE0uRGF0YSwgUkVNTD1GQUxTRSkNCnN1bW1hcnkoTW9kZWwuM2EpDQpgYGANCg0KLSBEb2VzIHRoaXMgY2hhbmdlIHRoZSBmaXQ/IA0KLSBOb3RlIGJlbG93IHRoYXQgdGhhdCAzIGlzIGEgYmV0dGVyIGZpdCB0aGFuIDNhLCANCiAgICAtIEJ1dCBNb2RlbCAzIHZvaWxhdGVkIHRoZSBhc3N1bXB0aW9uLiBTbyB3ZSBtb3ZlIG9uIHdpdGggTW9kZWwgM2ENCg0KYGBge3J9DQphbm92YShNb2RlbC4zLE1vZGVsLjNhKQ0KYGBgDQoNCi0gTGV0cyBmaW5hbGx5IHRlc3QgdGhlIGxldmVsIDEgYW5kIDIgaW50ZXJhY3Rpb24NCg0KYGBge3J9DQpNb2RlbC40PC1sbWVyKE1hdGggfiBBY3RpdmVUaW1lLkdNKlN1cHBvcnQuQ0MrKDErU3VwcG9ydC5DQ3x8Q2xhc3Nyb29tKSwgIA0KICAgICAgICAgICAgICBkYXRhPU1MTS5EYXRhLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShNb2RlbC40KQ0KYGBgDQoNCg0KYGBge3IsIGVjaG89RkFMU0V9DQpNSTQ8LXJvdW5kKHVubmFtZShmaXhlZihNb2RlbC40KVsxXSksMikNCk1TQTQ8LXJvdW5kKHVubmFtZShmaXhlZihNb2RlbC40KVsyXSksMikNCk1TUzQ8LXJvdW5kKHVubmFtZShmaXhlZihNb2RlbC40KVszXSksMikNCk1JbnRlcjQ8LXJvdW5kKHVubmFtZShmaXhlZihNb2RlbC40KVszXSksMikNCmBgYA0KDQotIE91ciBpbnRlcmNlcHQgd2FzIGByIE1JNGAsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBPdXIgYWN0aXZlIHNsb3BlIHdhcyBgciBNU0E0YCwgd2hpY2ggd2FzIHNpZ25pZmljYW50DQotIE91ciBzdXBwb3J0IHNsb3BlIHdhcyBgciBNU1M0YCwgd2hpY2ggd2FzIE5PVCBzaWduaWZpY2FudA0KLSBPdXIgaW50ZXJhY3Rpb24gd2FzIGByIE1JbnRlcjRgLCB3aGljaCB3YXMgc2lnbmlmaWNhbnQNCi0gV2FzIHRoaXMgYSBiZXR0ZXIgZml0IHRoYW4gdGhlIG1vZGVsIDNhPyBZZXMhIChzZWUgYmVsb3cpDQoNCmBgYHtyfQ0KYW5vdmEoTW9kZWwuM2EsTW9kZWwuNCkNCmBgYA0KDQojIyMgUGxvdCB0aGUgZmluYWwgbW9kZWwNCi0gV2Ugd2lsbCBwbG90IGluIHRoZSB0cmFkaXRpb25hbCB3YXkNCiAgICAtIFN1cHBvcnQgKC0xU0QsIE1lYW4sICtTRCkNCg0KYGBge3J9DQpsaWJyYXJ5KGVmZmVjdHMpDQojIFNldCBsZXZlbHMgb2Ygc3VwcG9ydA0KU0xldmVsczwtYyhtZWFuKE1MTS5EYXRhJFN1cHBvcnQuQ0MpLXNkKE1MTS5EYXRhJFN1cHBvcnQuQ0MpLA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIG1lYW4oTUxNLkRhdGEkU3VwcG9ydC5DQyksDQogICAgICAgICAgIG1lYW4oTUxNLkRhdGEkU3VwcG9ydC5DQykrc2QoTUxNLkRhdGEkU3VwcG9ydC5DQykpDQojZXh0cmFjdCBmaXhlZCBlZmZlY3RzDQpSZXN1bHRzLk1vZGVsLjQ8LUVmZmVjdChjKCJBY3RpdmVUaW1lLkdNIiwiU3VwcG9ydC5DQyIpLE1vZGVsLjQsDQogICAgIHhsZXZlbHM9bGlzdChBY3RpdmVUaW1lLkdNPXNlcSgtLjUsLjUsLjIpLCANCiAgICAgICAgICAgICAgICAgIFN1cHBvcnQuQ0M9U0xldmVscykpDQojQ29udmVydCB0byBkYXRhIGZyYW1lIGZvciBnZ3Bsb3QNClJlc3VsdHMuTW9kZWwuNDwtYXMuZGF0YS5mcmFtZShSZXN1bHRzLk1vZGVsLjQpDQojTGFiZWwgU3VwcG9ydCBmb3IgZ3JhcGhpbmcNClJlc3VsdHMuTW9kZWwuNCRTdXBwb3J0LkY8LWZhY3RvcihSZXN1bHRzLk1vZGVsLjQkU3VwcG9ydC5DQywNCiAgICAgICAgICAgICAgICAgICAgICAgIGxldmVscz1TTGV2ZWxzLA0KICAgICAgICAgICAgICAgICAgICAgICAgIGxhYmVscz1jKCJMb3cgU3VwcG9ydCIsICJNZWFuIFN1cHBvcnQiLCAiSGlnaCBTdXBwb3J0IikpDQoNCiNQbG90IGZpeGVkIGVmZmVjdA0KRmluYWwuRml4ZWQuUGxvdC4xIDwtZ2dwbG90KGRhdGEgPSBSZXN1bHRzLk1vZGVsLjQsIA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgIGFlcyh4ID0gQWN0aXZlVGltZS5HTSwgeSA9Zml0LCBncm91cD1TdXBwb3J0LkYpKSsNCiAgZ2VvbV9saW5lKHNpemU9MiwgYWVzKGNvbG9yPVN1cHBvcnQuRixsaW5ldHlwZT1TdXBwb3J0LkYpKSsNCiAgY29vcmRfY2FydGVzaWFuKHhsaW0gPSBjKC0uNSwgLjUpLHlsaW0gPSBjKDUwLCA5MCkpKyANCiAgZ2VvbV9yaWJib24oYWVzKHltaW49Zml0LXNlLCB5bWF4PWZpdCtzZSwgZ3JvdXA9U3VwcG9ydC5GLCBmaWxsPVN1cHBvcnQuRiksYWxwaGE9LjIpKw0KICB4bGFiKCJQcm9wb3J0aW9uIG9mIFRpbWUgRW5nYWdlZCBpbiBBY3RpdmUgTGVhcm5pbmcgXG5DZW50ZXJlZCIpKw0KICB5bGFiKCJNYXRoIFNjb3JlIikrIA0KICB0aGVtZShsZWdlbmQucG9zaXRpb24gPSAidG9wIiwgDQogICAgICAgIGxlZ2VuZC50aXRsZT1lbGVtZW50X2JsYW5rKCkpDQpGaW5hbC5GaXhlZC5QbG90LjENCmBgYA0KDQojIEZvcm1hdCBPdXRwdXQNCg0KYGBge3IsIHJlc3VsdHM9J2FzaXMnfQ0KbGlicmFyeSh0ZXhyZWcpDQp0ZXhyZWcobGlzdChNb2RlbC4xLE1vZGVsLjIsTW9kZWwuM2EsTW9kZWwuNCksIA0KICAgICAgIHRhYmxlID0gRkFMU0UsIHVzZS5wYWNrYWdlcyA9IEZBTFNFLA0KICAgICAgIHNpbmdsZS5yb3cgPSBGQUxTRSwgc3RhcnMgPSBjKDAuMDAxLCAwLjAxLCAwLjA1LDAuMSksZGlnaXRzPTMpDQpgYGANCg0KIyMgU2F2ZSB0aGUgcmVzdWx0cyBvZiBtb2RlbGluZw0KLSBUaGlzIGxldHMgeW91IG1ha2UgYSBEb2MgZmlsZQ0KYGBge3IsIGV2YWw9RkFMU0V9DQpodG1scmVnKGxpc3QoTW9kZWwuMSxNb2RlbC4yLE1vZGVsLjNhLE1vZGVsLjQpLGZpbGUgPSAiTW9kZWxSZXN1bHRzLmRvYyIsIA0KICAgICAgICBzaW5nbGUucm93ID0gRkFMU0UsIHN0YXJzID0gYygwLjAwMSwgMC4wMSwgMC4wNSwwLjEpLGRpZ2l0cz0zLA0KICAgICAgICBpbmxpbmUuY3NzID0gRkFMU0UsIGRvY3R5cGUgPSBUUlVFLCBodG1sLnRhZyA9IFRSVUUsIA0KICAgICAgICBoZWFkLnRhZyA9IFRSVUUsIGJvZHkudGFnID0gVFJVRSkNCmBgYA0KDQojIFJlLUV4YW1pbmUgUmFuZG9tIEVmZmVjdHMNCi0gV2h5IGRvbid0IHdlIGxldCBBY3RpdmVUaW1lIHZhcnkgYXMgYSBmdW5jdGlvbiBvZiB0aGUgY2xhc3Nyb29tLiANCiAgICAtIFRoZXJlIGlzIG9mIGNvdXJzZSB1bnN5c3RlbWF0aWMgZXJyb3IgKG5vaXNlKSB0aGF0IHdlIGNvdWxkIGFjY291bnQgZm9yDQoNCmBgYHtyfQ0KTW9kZWwuNTwtbG1lcihNYXRoIH4gQWN0aXZlVGltZS5HTSpTdXBwb3J0LkNDKygxK0FjdGl2ZVRpbWUuR00rU3VwcG9ydC5DQ3x8Q2xhc3Nyb29tKSwgIA0KICAgICAgICAgICAgICBkYXRhPU1MTS5EYXRhLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShNb2RlbC41KQ0KYGBgDQoNCi0gV2UgYWRkZWQgYWxvdCBvZiBkZWdyZWVzIG9mIGZyZWVkb20gdG8gdGhpcyBtb2RlbCAobW9yZSByYW5kb20gc2xvcGVzIGFuZCBtb3JlIGNvcnJlbGF0aW9uIGJldHdlZW4gdGhlIHRlcm1zKQ0KLSBXaWxsIHRoaXMgaW1wcm92ZSB0aGUgZml0PyBJbiB0aGlzIGNhc2UsIE5PISBTbyBhZGRpbmcgdGhlIGV4dHJhIHRlcm1zIGRvZXMgbm90IHJlYWxseSBoZWxwDQoNCmBgYHtyfQ0KYW5vdmEoTW9kZWwuNCxNb2RlbC41KQ0KYGBgDQoNCi0gV2UgYWRkZWQgYWxvdCBvZiBkZWdyZWVzIG9mIGZyZWVkb20gdG8gdGhpcyBtb2RlbCAobW9yZSByYW5kb20gc2xvcGVzIGFuZCBtb3JlIGNvcnJlbGF0aW9uIGJldHdlZW4gdGhlIHRlcm1zKQ0KDQoNCiMjIFNpbXVsYXRpb24gVGFrZSAyDQotIFNldCB0aGUgZGlmZmVyZW50IHNsb3BlIG9mICoqcHJvcG9ydGlvbiBvZiB0aW1lKiogKHBsdXMgbm9pc2UpIA0KLSAqRGlmZmVyZW50KiBpbnRlcmNlcHQgcGVyIGNsYXNzIChwbHVzIG5vaXNlKSBbd2hpY2ggd2lsbCBpbXBsaWNpdGx5IGNvcnJlbGF0ZSB3aXRoICoqc3VwcG9ydGl2ZSoqXQ0KLSAqRGlmZmVyZW50KiBzbG9wZSBwZXIgY2xhc3Mgb24gKipzdXBwb3J0aXZlKiogKHBsdXMgbm9pc2UpDQotIFNldCBzYW1lIGludGVyYWN0aW9uIGJldHdlZW4gKipwcm9wb3J0aW9uIG9mIHRpbWUqKiBhbmQgKipzdXBwb3J0aXZlKioNCi0gVGVhY2hlcnMgaW4gQ2xhc3Nyb29tcyAxIGFuZCAyIHdlcmUgKipUb2xkKiogdGhlIHByb2dyYW0gKndvcmtzKiBhbmQgMyAmIDQgdGhhdCBpdCBpcyAqZXhwZXJpbWVudGFsKg0KDQpgYGB7cn0NCiNTZXQgc2VlZCBzbyB5b3VyIGFuc3dlcnMgYXJlIGFsbCB0aGUgc2FtZQ0Kc2V0LnNlZWQoOSkNCiMgU2FtcGxlIFBlciBjbGFzcyByb29tIHBlb3BsZQ0KbjEgPC0gNTA7IG4yIDwtIDUwOyBuMyA8LSA1MDsgbjQgPC0gNTANCk48LW4xK24yK24zK240ICMgVG90YWwgTg0KIyBVbmlmb3JtIGRpc3Ryb2J1dGlvbiBvZiBBY3RpdmVUaW1lIHBlciBjbGFzc3Jvb20NClgxIDwtIHJ1bmlmKG4xLCAwLCAxKTsgWDIgPC0gcnVuaWYobjIsIDAsIDEpDQpYMyA8LSBydW5pZihuMywgMCwgMSk7IFg0IDwtIHJ1bmlmKG40LCAwLCAxKQ0KIyBVbmlmb3JtIGRpc3Ryb2J1dGlvbiBvZiBzdXBwb3J0IHBlciBjbGFzc3Jvb20NCloxIDwtIHJ1bmlmKG4xLCAwLCAxKTsgWjIgPC0gcnVuaWYobjIsIDAsIDEpDQpaMyA8LSBydW5pZihuMywgMCwgMSk7IFo0IDwtIHJ1bmlmKG40LCAwLCAxKQ0KIyBJbnRlcmNlcHRzIHBlciBjbGFzc3Jvb20NCkIwLjEgPC0gODA7IEIwLjIgPC0gNzUNCkIwLjMgPC0gNjU7IEIwLjQgPC0gNjgNCiMgU2FtZSBzbG9wZSBmb3IgQWN0aXZlVGltZSBwZXIgY2xhc3Nyb29tICsgTm9pc2UNCkIxIDwtIHJub3JtKG4xLCAxNywgc2Q9Mi41KTsgQjIgPC0gcm5vcm0objIsIDEyLCBzZD0yLjUpDQpCMyA8LSBybm9ybShuMywgOCwgc2Q9Mi41KTsgQjQgPC0gcm5vcm0objQsIDQsIHNkPTIuNSkNCiMgZGlmZmVyZW50IHNsb3BlIGZvciBzdXBwb3J0IHBlciBjbGFzc3Jvb20gKyBOb2lzZQ0KZzEgPC0gcm5vcm0objEsIDEwLCBzZD0yLjUpOyBnMiA8LSBybm9ybShuMiwgNSwgc2Q9Mi41KQ0KZzMgPC0gcm5vcm0objMsIC01LCBzZD0yLjUpOyBnNCA8LSBybm9ybShuNCwgMiwgc2Q9Mi41KQ0KIyBTYW1lIGludGVyYWN0aW9uIGJldHdlZW4gQWN0aXZlVGltZSpzdXBwb3J0IHN1cHBvcnQgcGVyIGNsYXNzcm9vbSArIE5vaXNlDQpmMTwtIHJub3JtKG4zLCAxNSwgc2Q9Mi41KTsgZjI8LSBybm9ybShuMywgMTUsIHNkPTIuNSkNCmYzPC0gcm5vcm0objMsIDE1LCBzZD0yLjUpOyBmNDwtIHJub3JtKG4zLCAxNSwgc2Q9Mi41KQ0KIyBub2lzZSBwZXIgc3R1ZGVudCB3aXRoaW4gZWFjaCBjbGFzc3Jvb20NCmUxIDwtIHJub3JtKG4xLCAwLCBzZD0yLjUpOyBlMiA8LSBybm9ybShuMiwgMCwgc2Q9Mi41KQ0KZTMgPC0gcm5vcm0objMsIDAsIHNkPTIuNSk7IGU0IDwtIHJub3JtKG40LCAwLCBzZD0yLjUpDQoNCiMgT3VyIGVxdWF0aW9uIHRvICBjcmVhdGUgWSBmb3IgZWFjaCBjbGFzc3Jvb20NClkxID0gQjEqc2NhbGUoWDEsc2NhbGU9RikrZzEqWjErZjEqc2NhbGUoWDEsc2NhbGU9Rikqc2NhbGUoWjEsc2NhbGU9RikgKyBCMC4xICsgZTENClkyID0gQjIqc2NhbGUoWDIsc2NhbGU9RikrZzIqWjIrZjIqc2NhbGUoWDIsc2NhbGU9Rikqc2NhbGUoWjIsc2NhbGU9RikgKyBCMC4yICsgZTINClkzID0gQjMqc2NhbGUoWDMsc2NhbGU9RikrZzMqWjMrZjMqc2NhbGUoWDMsc2NhbGU9Rikqc2NhbGUoWjMsc2NhbGU9RikgKyBCMC4zICsgZTMNClk0ID0gQjQqc2NhbGUoWDQsc2NhbGU9RikrZzQqWjQrZjQqc2NhbGUoWDQsc2NhbGU9Rikqc2NhbGUoWjQsc2NhbGU9RikgKyBCMC40ICsgZTQNCiMgTWVyZ2UgY2xhc3Nyb29tcyBpbnRvIDEgZGF0YS5mcmFtZQ0KTUxNLkRhdGEuMjwtZGF0YS5mcmFtZShNYXRoPWMoWTEsWTIsWTMsWTQpLEFjdGl2ZVRpbWU9YyhYMSxYMixYMyxYNCksU3VwcG9ydD1jKFoxLFoyLFozLFo0KSwNCiAgICAgICAgICAgICAgICAgICAgIENsYXNzcm9vbT1jKHJlcCgiQzEiLG4xKSxyZXAoIkMyIixuMikscmVwKCJDMyIsbjMpLHJlcCgiQzQiLG40KSksDQogICAgICAgICAgICAgICAgICAgICBUb2xkPWMocmVwKCJXb3JrcyIsbjEpLHJlcCgiV29ya3MiLG4yKSwNCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICByZXAoIkV4cGVyaW1lbnRhbCIsbjMpLHJlcCgiRXhwZXJpbWVudGFsIixuNCkpLA0KICAgICAgICAgICAgICAgICAgICAgU3R1ZGVudElEPWFzLmZhY3RvcigxOk4pKQ0KYGBgDQoNCiMjIyBQbG90IG91ciBDbHVzdGVycw0KLSBTdHVkZW50cyBuZXN0ZWQgaW4gY2xhc3Nyb29tcw0KDQpgYGB7ciwgb3V0LndpZHRoPScuNDlcXGxpbmV3aWR0aCcsIGZpZy53aWR0aD0zLjI1LCBmaWcuaGVpZ2h0PTMuMjUsZmlnLnNob3c9J2hvbGQnLGZpZy5hbGlnbj0nY2VudGVyJ30NCmxpYnJhcnkoZ2dwbG90MikNCnRoZW1lX3NldCh0aGVtZV9idyhiYXNlX3NpemUgPSAxMiwgYmFzZV9mYW1pbHkgPSAiIikpIA0KDQpDbGFzc1Jvb20uQWN0aXZlLjIgPC1nZ3Bsb3QoZGF0YSA9IE1MTS5EYXRhLjIsIGFlcyh4ID0gQWN0aXZlVGltZSwgeT1NYXRoLGdyb3VwPUNsYXNzcm9vbSkpKw0KICBmYWNldF9ncmlkKFRvbGR+LikrDQogIGdlb21fcG9pbnQoYWVzKGNvbG91ciA9IENsYXNzcm9vbSkpKw0KICBnZW9tX3Ntb290aChtZXRob2QgPSAibG0iLCBzZSA9IFRSVUUsIGFlcyhjb2xvdXIgPSBDbGFzc3Jvb20pKSsNCiAgeGxhYigiQWN0aXZlIExlYXJuaW5nIFRpbWUiKSt5bGFiKCJNYXRoIFNjb3JlIikrDQogIHRoZW1lKGxlZ2VuZC5wb3NpdGlvbiA9ICJub25lIikNCkNsYXNzUm9vbS5BY3RpdmUuMg0KDQpDbGFzc1Jvb20uU3VwcG9ydC4yIDwtZ2dwbG90KGRhdGEgPSBNTE0uRGF0YS4yLCBhZXMoeCA9IFN1cHBvcnQsIHk9TWF0aCxncm91cD1DbGFzc3Jvb20pKSsNCiAgZmFjZXRfZ3JpZChUb2xkfi4pKw0KICBnZW9tX3BvaW50KGFlcyhjb2xvdXIgPSBDbGFzc3Jvb20pKSsNCiAgZ2VvbV9zbW9vdGgobWV0aG9kID0gImxtIiwgc2UgPSBUUlVFLCBhZXMoY29sb3VyID0gQ2xhc3Nyb29tKSkrDQogIHhsYWIoIlN1cHBvcnQiKSt5bGFiKCJNYXRoIFNjb3JlIikrDQogIHRoZW1lKGxlZ2VuZC5wb3NpdGlvbiA9ICJub25lIikNCkNsYXNzUm9vbS5TdXBwb3J0LjINCmBgYA0KDQotIExldHMgY2VudGVyIHRoZSBkYXRhIGp1c3QgYXMgYmVmb3JlIGFuZCBkbyB0aGUgbW9kZWxpbmcgYWxpdHRsZSBmYXN0ZXIsIGFsc28gbGV0cyBqdXN0IGxheWVyIHRoZSByYW5kb20gZWZmZWN0cy4NCi0gQXMgd2UgYWRkIG1vcmUgcmFuZG9tIGVmZmVjdHMsIHdhdGNoIHdoYXQgaGFwcGVucyB0byB0aGUgU0UgZm9yIGVhY2ggdGVybQ0KDQojIyMgUmFuZG9tIEludGVyY2VwdA0KYGBge3J9DQpNTE0uRGF0YS4yJEFjdGl2ZVRpbWUuR008LXNjYWxlKE1MTS5EYXRhLjIkQWN0aXZlVGltZSxzY2FsZT1GKQ0KTUxNLkRhdGEuMjwtZGRwbHkoTUxNLkRhdGEuMiwuKENsYXNzcm9vbSksIG11dGF0ZSwgQ2xhc3NTdXBwb3J0ID0gbWVhbihTdXBwb3J0KSkNCk1MTS5EYXRhLjIkU3VwcG9ydC5DQzwtTUxNLkRhdGEuMiRTdXBwb3J0LU1MTS5EYXRhLjIkQ2xhc3NTdXBwb3J0DQoNCk1MTS5Nb2RlbC4xPC1sbWVyKE1hdGggfiBBY3RpdmVUaW1lLkdNKlN1cHBvcnQuQ0MrKDF8Q2xhc3Nyb29tKSwgIA0KICAgICAgICAgICAgICBkYXRhPU1MTS5EYXRhLjIsIFJFTUw9RkFMU0UpDQpgYGANCg0KIyMjIFJhbmRvbSBTbG9wZSAmIEludGVyY2VwdA0KYGBge3J9DQpNTE0uTW9kZWwuMjwtbG1lcihNYXRoIH4gQWN0aXZlVGltZS5HTSpTdXBwb3J0LkNDKygxK1N1cHBvcnQuQ0N8Q2xhc3Nyb29tKSwgIA0KICAgICAgICAgICAgICBkYXRhPU1MTS5EYXRhLjIsIFJFTUw9RkFMU0UpDQpgYGANCg0KIyMjIFJhbmRvbSBTbG9wZXMgJiBJbnRlcmNlcHQNCmBgYHtyfQ0KTUxNLk1vZGVsLjM8LWxtZXIoTWF0aCB+IEFjdGl2ZVRpbWUuR00qU3VwcG9ydC5DQysoMStBY3RpdmVUaW1lLkdNK1N1cHBvcnQuQ0N8Q2xhc3Nyb29tKSwgIA0KICAgICAgICAgICAgICBkYXRhPU1MTS5EYXRhLjIsIFJFTUw9RkFMU0UpDQpgYGANCg0KLSBTZWUgdGhlIGNoYW5nZSBpbiBTRQ0KICAgIC0gSGVscHMgcHJvdGVjdCBvdXQgdHlwZSBJIGVycm9yIHJhdGUNCg0KYGBge3IsIHJlc3VsdHM9J2FzaXMnfQ0KbGlicmFyeSh0ZXhyZWcpDQp0ZXhyZWcobGlzdChNTE0uTW9kZWwuMSxNTE0uTW9kZWwuMixNTE0uTW9kZWwuMyksIA0KICAgICAgIHRhYmxlID0gRkFMU0UsIHVzZS5wYWNrYWdlcyA9IEZBTFNFLA0KICAgICAgIHNpbmdsZS5yb3cgPSBGQUxTRSwgc3RhcnMgPSBjKDAuMDAxLCAwLjAxLCAwLjA1LDAuMSksZGlnaXRzPTMpDQpgYGANCg0KIyMjIE1vZGVsIGZpdHMNCi0gSW4gdGhpcyBjYXNlIGFkZGluZyB0aGUgTDEgc2xvcGUgYXMgcmFuZG9tIGltcHJvdmVkIHRoZSBmaXQNCg0KYGBge3J9DQphbm92YShNTE0uTW9kZWwuMSxNTE0uTW9kZWwuMixNTE0uTW9kZWwuMykNCmBgYA0KDQojIyMgUGxvdCB0aGUgZmluYWwgbW9kZWwNCi0gV2Ugd2lsbCBwbG90IGluIHRoZSB0cmFkaXRpb25hbCB3YXkNCiAgICAtIFN1cHBvcnQgKC0xU0QsIE1lYW4sICtTRCkNCg0KYGBge3J9DQojIFNldCBsZXZlbHMgb2Ygc3VwcG9ydA0KU0xldmVscy4yPC1jKG1lYW4oTUxNLkRhdGEuMiRTdXBwb3J0LkNDKS1zZChNTE0uRGF0YS4yJFN1cHBvcnQuQ0MpLA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIG1lYW4oTUxNLkRhdGEuMiRTdXBwb3J0LkNDKSwNCiAgICAgICAgICAgbWVhbihNTE0uRGF0YS4yJFN1cHBvcnQuQ0MpK3NkKE1MTS5EYXRhLjIkU3VwcG9ydC5DQykpDQpSZXN1bHRzLk1MTS5Nb2RlbC4zPC1FZmZlY3QoYygiQWN0aXZlVGltZS5HTSIsIlN1cHBvcnQuQ0MiKSxNTE0uTW9kZWwuMywNCiAgICAgeGxldmVscz1saXN0KEFjdGl2ZVRpbWUuR009c2VxKC0uNSwuNSwuMiksIA0KICAgICAgICAgICAgICAgICAgU3VwcG9ydC5DQz1TTGV2ZWxzLjIpKQ0KUmVzdWx0cy5NTE0uTW9kZWwuMzwtYXMuZGF0YS5mcmFtZShSZXN1bHRzLk1MTS5Nb2RlbC4zKQ0KUmVzdWx0cy5NTE0uTW9kZWwuMyRTdXBwb3J0LkY8LWZhY3RvcihSZXN1bHRzLk1MTS5Nb2RlbC4zJFN1cHBvcnQuQ0MsDQogICAgICAgICAgICAgICAgICAgICAgICBsZXZlbHM9U0xldmVscy4yLA0KICAgICAgICAgICAgICAgICAgICAgICAgIGxhYmVscz1jKCJMb3cgU3VwcG9ydCIsICJNZWFuIFN1cHBvcnQiLCAiSGlnaCBTdXBwb3J0IikpDQpGaW5hbC5GaXhlZC5QbG90LjIgPC1nZ3Bsb3QoZGF0YSA9IFJlc3VsdHMuTUxNLk1vZGVsLjMsIA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgIGFlcyh4ID0gQWN0aXZlVGltZS5HTSwgeSA9Zml0LCBncm91cD1TdXBwb3J0LkYpKSsNCiAgZ2VvbV9saW5lKHNpemU9MiwgYWVzKGNvbG9yPVN1cHBvcnQuRixsaW5ldHlwZT1TdXBwb3J0LkYpKSsNCiAgY29vcmRfY2FydGVzaWFuKHhsaW0gPSBjKC0uNSwgLjUpLHlsaW0gPSBjKDUwLCA5MCkpKyANCiAgZ2VvbV9yaWJib24oYWVzKHltaW49Zml0LXNlLCB5bWF4PWZpdCtzZSwgZ3JvdXA9U3VwcG9ydC5GLCBmaWxsPVN1cHBvcnQuRiksYWxwaGE9LjIpKw0KICB4bGFiKCJQcm9wb3J0aW9uIG9mIFRpbWUgRW5nYWdlZCBpbiBBY3RpdmUgTGVhcm5pbmcgXG5DZW50ZXJlZCIpKw0KICB5bGFiKCJNYXRoIFNjb3JlIikrIA0KICB0aGVtZShsZWdlbmQucG9zaXRpb24gPSAidG9wIiwgDQogICAgICAgIGxlZ2VuZC50aXRsZT1lbGVtZW50X2JsYW5rKCkpDQpGaW5hbC5GaXhlZC5QbG90LjINCmBgYA0KDQoNCiMgTXVsdGktTGV2ZWwgTW9kZWwgd2l0aCBDcm9zcy1sZXZlbCBJbnRlcmFjdGlvbnMNCi0gU28gZmFyIHdlIGV4YW1pbmVkIHRoZSBsZXZlbCAxIHNsb3BlcywgYnV0IHRoZXJlIGlzIExldmVsIDIgdmFyaWFibGUgdG8gZGVhbCB3aXRoOiAqd2hhdCB0aGUgdGVhY2hlciB3YXMgdG9sZCBhYm91dCB0aGUgcHJvZ3JhbSoNCi0gVGhlIHByb2JsZW0gaXMgZ29pbmcgdG8gYmUgdGhhdCB0ZWFjaGVycyBhcmUgbmVzdGVkIGluIHRoZWlyIGNsYXNzcm9vbXMsIHNvIHdlIGhhdmUgaW1wbGljaXRseSBjb250cm9sbGVkIGZvciB0aGUgaW50ZXJjZXB0IGRpZmZlcmVuY2VzIGZvciB0aGUgKipUb2xkKiogdmFyaWFibGUgDQogICAgLSBbTm90ZTogVG9sZCBoYXMgMiBtZWFzdXJlbWVudHMgd2Ugd2lsbCBub3QgdHJlYXQgaXQgYXMgcmFuZG9tXQ0KLSBMZXRzIGdvIGJhY2sgdG8gc2ltdWxhdGlvbiAxIGFuZCByZS1leGFtaW5lIHRoZSByZXN1bHRzIGdpdmVuIHRoaXMgTGV2ZWwgMiBmYWN0b3INCi0gRmlyc3QgbGV0cyBtYWtlIHRoZSB2YXJpYWJsZSBudW1lcmljIGFuZCBjZW50ZXIgaXQuIA0KDQpgYGB7cn0NCk1MTS5EYXRhLjIkVG9sZC5OPC1hcy5udW1lcmljKGFzLmZhY3RvcihNTE0uRGF0YS4yJFRvbGQpKQ0KTUxNLkRhdGEuMiRUb2xkLkM8LXNjYWxlKE1MTS5EYXRhLjIkVG9sZC5OLHNjYWxlPUYpWyxdDQpgYGANCg0KIyMgQWRkIExldmVsIDIgRml4ZWQgRWZmZWN0cw0KLSBMZXQncyBzdGFydCBieSB3b3JraW5nIGZyb20gTW9kZWwgMSBhbmQgYWRkIHRoZSBMZXZlbCAyIA0KDQpgYGB7cn0NCmxpYnJhcnkobG1lNCkNCkwydGVzdC4xPC1sbWVyKE1hdGggfiBBY3RpdmVUaW1lLkdNK1RvbGQuQw0KICAgICAgICAgICAgICAgKygxfENsYXNzcm9vbSksICANCiAgICAgICAgICAgICAgZGF0YT1NTE0uRGF0YS4yLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShMMnRlc3QuMSkNCmBgYA0KDQpgYGB7ciwgZWNobz1GQUxTRX0NCkkxPC1yb3VuZCh1bm5hbWUoZml4ZWYoTDJ0ZXN0LjEpWzFdKSwyKQ0KU0ExPC1yb3VuZCh1bm5hbWUoZml4ZWYoTDJ0ZXN0LjEpWzJdKSwyKQ0KU1QxPC1yb3VuZCh1bm5hbWUoZml4ZWYoTDJ0ZXN0LjEpWzNdKSwyKQ0KDQpgYGANCg0KLSBPdXIgaW50ZXJjZXB0IHdhcyBgciBJMWAsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBPdXIgYWN0aXZlIHNsb3BlIHdhcyBgciBTQTFgLCB3aGljaCB3YXMgc2lnbmlmaWNhbnQNCi0gT3VyIHRlYWNoZXIgc2xvcGUgd2FzIGByIFNUMWAsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBXYXMgdGhpcyBhIGJldHRlciBmaXQgdGhhbiB0aGUgbW9kZWwgMT8gWWVzISAoc2VlIGJlbG93KQ0KDQpgYGB7cn0NCmFub3ZhKE1MTS5Nb2RlbC4xLEwydGVzdC4xKQ0KYGBgDQoNCiMjIEFkZCBDcm9zcy1MZXZlbCBJbnRlcmFjdGlvbnMNCmBgYHtyfQ0KTDJ0ZXN0LjI8LWxtZXIoTWF0aCB+IEFjdGl2ZVRpbWUuR00qVG9sZC5DKygxfENsYXNzcm9vbSksICANCiAgICAgICAgICAgICAgZGF0YT1NTE0uRGF0YS4yLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShMMnRlc3QuMikNCmBgYA0KDQpgYGB7ciwgZWNobz1GQUxTRX0NCkkyPC1yb3VuZCh1bm5hbWUoZml4ZWYoTDJ0ZXN0LjIpWzFdKSwyKQ0KU0EyPC1yb3VuZCh1bm5hbWUoZml4ZWYoTDJ0ZXN0LjIpWzJdKSwyKQ0KU1QyPC1yb3VuZCh1bm5hbWUoZml4ZWYoTDJ0ZXN0LjIpWzNdKSwyKQ0KSW50ZXIyPC1yb3VuZCh1bm5hbWUoZml4ZWYoTDJ0ZXN0LjIpWzRdKSwyKQ0KYGBgDQoNCg0KLSBPdXIgaW50ZXJjZXB0IHdhcyBgciBJMmAsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBPdXIgYWN0aXZlIHNsb3BlIHdhcyBgciBTQTJgLCB3aGljaCB3YXMgc2lnbmlmaWNhbnQNCi0gT3VyIHRlYWNoZXIgc2xvcGUgd2FzIGByIFNUMmAsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBPdXIgaW50ZXJhY3Rpb24gc2xvcGUgd2FzIGByIEludGVyMmAsIHdoaWNoIHdhcyBzaWduaWZpY2FudA0KLSBXYXMgdGhpcyBhIGJldHRlciBmaXQgdGhhbiB0aGUgTDJ0ZXN0LjE/IE5vISAoc2VlIGJlbG93KQ0KDQpgYGB7cn0NCmFub3ZhKEwydGVzdC4xLEwydGVzdC4yKQ0KYGBgDQoNCiMjIyBBZGRpbmcgQmFjayBTdXBwb3J0DQotIFdlIGtub3cgZnJvbSB0aGUgZmlndXJlcyBhbmQgcHJldmlvdXMgbW9kZWxzIHRoYXQgc3VwcG9ydCB3YXMgYW4gaW1wb3J0YW50IHZhcmlhYmxlDQotIFdoYXQgKipTdXBwb3J0KiogYW5kIHRvbGQgaW4gdGhlIHNhbWUgbW9kZWwgYXMgKipUb2xkKiogd2UgYXJlIGdvaW5nIHRvIGhhdmUgYSBwcm9ibGVtIGJlY2F1c2Ugd2UgY2FuIHNlZSBpbiBmaWd1cmVzIGl0IGlzIGJhc2ljYWxseSBjb25mb3VuZGVkDQoNCmBgYHtyfQ0KTDJ0ZXN0LjM8LWxtZXIoTWF0aCB+IEFjdGl2ZVRpbWUuR00qVG9sZC5DK1N1cHBvcnQuQ0MrKDErU3VwcG9ydC5DQ3xDbGFzc3Jvb20pLCAgDQogICAgICAgICAgICAgIGRhdGE9TUxNLkRhdGEuMiwgUkVNTD1GQUxTRSkNCnN1bW1hcnkoTDJ0ZXN0LjMpDQpgYGANCg0KLSBPdXIgcmFuZG9tIHNsb3BlcyBhcmUgY29ycmVsYXRlZCBhdCAxIHdpdGggdGhlIHJhbmRvbSBpbnRlcmNlcHQuIFRoYXQgbWFrZXMgc2Vuc2UgZ2l2ZW4gb3VyIGZpZ3VyZXMhDQotIFRoZSB0aGUgcmFuZG9tIHNsb3BlcyBhcmUgY29uZm91bmRlZCB3aXRoIGludGVyY2VwdCwgbGV0cyByZW1vdmUgdGhlIGNvcnJlbGF0aW9uDQoNCmBgYHtyfQ0KTDJ0ZXN0LjNhPC1sbWVyKE1hdGggfiBBY3RpdmVUaW1lLkdNKlRvbGQuQytTdXBwb3J0LkNDKygxK1N1cHBvcnQuQ0N8fENsYXNzcm9vbSksICANCiAgICAgICAgICAgICAgZGF0YT1NTE0uRGF0YS4yLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShMMnRlc3QuM2EpDQpgYGANCg0KLSBPdXIgbWFpbiBlZmZlY3Qgb2YgKipUb2xkKiogY2FtZSBiYWNrIGFuZCB0aGUgbW9kZWwgZml0dGVkIGJldHRlcg0KDQpgYGB7cn0NCmFub3ZhKEwydGVzdC4yLEwydGVzdC4zYSkNCmBgYA0KDQojIyMgQ291bmZvdW5kZWQgUmFuZG9tIFNsb3BlDQotIFdoYXQgaGFwcGVucyBpZiB3ZSB0cnkgdG8gaW50ZXJhY3QgKipTdXBwb3J0Kiogd2l0aCAqKlRvbGQqKg0KLSBUaGUgc2xvcGUgb24gc3VwcG9ydCBzaG91bGQgYmFzaWNhbGx5IGRlY3JlYXNlIG9yIGRpc2FwcGVhciAoY2F1c2Ugd2UgaGF2ZSBzbyBmZXcgY2xhc3Nyb29tcyBhbmQgdG9sZCBjb25kaXRpb25zKSwgKip3aHkqKj8gDQogICAgLSBCZWNhdXNlIHRob3NlIHJhbmRvbSBzbG9wZXMgb2Ygc3VwcG9ydCBhcmUgbm90IHJlYWxseSByYW5kb20hIFRoZXkgY2FuIGJlIGV4cGxhaW5lZCBieSBhIGZpeGVkIGVmZmVjdCB3aGF0IHRoZSB0ZWFjaGVyIHdhcyB0b2xkDQogICAgLSBUaGUgc2FtZSB0aGluZyB3aWxsIGhhcHBlbiBpZiB3ZSBkbyBpdCB3aXRoICoqQWN0aXZlVGltZSoqDQoNCmBgYHtyfQ0KTDJ0ZXN0LjQ8LWxtZXIoTWF0aCB+IEFjdGl2ZVRpbWUuR00qVG9sZC5DK1N1cHBvcnQuQ0MqVG9sZC5DKygxK1N1cHBvcnQuQ0N8fENsYXNzcm9vbSksICANCiAgICAgICAgICAgICAgZGF0YT1NTE0uRGF0YS4yLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShMMnRlc3QuNCkNCmBgYA0KDQotIHdlIGNhbiByZW1vdmUgdGhlIHJhbmRvbSBlZmZlY3QganVzdCB0ZXN0IHRoZSBmb3IgYSB0aHJlZSB3YXkgKHRvIHNwZWVkIHRoaW5ncyB1cCkNCg0KYGBge3J9DQpMMnRlc3QuNGE8LWxtZXIoTWF0aCB+IEFjdGl2ZVRpbWUuR00qVG9sZC5DKlN1cHBvcnQuQ0MrKDF8Q2xhc3Nyb29tKSwgIA0KICAgICAgICAgICAgICBkYXRhPU1MTS5EYXRhLjIsIFJFTUw9RkFMU0UpDQpzdW1tYXJ5KEwydGVzdC40YSkNCmBgYA0KDQotIENoZWNrIGZpdA0KDQpgYGB7cn0NCmFub3ZhKEwydGVzdC4zYSxMMnRlc3QuNGEpDQpgYGANCg0KIyMjIFBsb3QgRmluYWwgTW9kZWwNCg0KYGBge3J9DQojIFNldCBsZXZlbHMgb2Ygc3VwcG9ydA0KU0xldmVscy4yPC1jKG1lYW4oTUxNLkRhdGEuMiRTdXBwb3J0LkNDKS1zZChNTE0uRGF0YS4yJFN1cHBvcnQuQ0MpLA0KICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgIG1lYW4oTUxNLkRhdGEuMiRTdXBwb3J0LkNDKSwNCiAgICAgICAgICAgbWVhbihNTE0uRGF0YS4yJFN1cHBvcnQuQ0MpK3NkKE1MTS5EYXRhLjIkU3VwcG9ydC5DQykpDQoNClJlc3VsdHMuTDJ0ZXN0LjRhPC1FZmZlY3QoYygiQWN0aXZlVGltZS5HTSIsIlN1cHBvcnQuQ0MiLCJUb2xkLkMiKSxMMnRlc3QuNGEsDQogICAgIHhsZXZlbHM9bGlzdChBY3RpdmVUaW1lLkdNPXNlcSgtLjUsLjUsLjIpLCANCiAgICAgICAgICAgICAgICAgIFN1cHBvcnQuQ0M9U0xldmVscy4yLA0KICAgICAgICAgICAgICAgICAgVG9sZC5DPWMobWluKE1MTS5EYXRhLjIkVG9sZC5DKSxtYXgoTUxNLkRhdGEuMiRUb2xkLkMpKSkpIA0KDQpSZXN1bHRzLkwydGVzdC40YTwtYXMuZGF0YS5mcmFtZShSZXN1bHRzLkwydGVzdC40YSkNCg0KUmVzdWx0cy5MMnRlc3QuNGEkU3VwcG9ydC5GPC1mYWN0b3IoUmVzdWx0cy5MMnRlc3QuNGEkU3VwcG9ydC5DQywNCiAgICAgICAgICAgICAgICAgICAgICAgIGxldmVscz1TTGV2ZWxzLjIsDQogICAgICAgICAgICAgICAgICAgICAgICAgbGFiZWxzPWMoIkxvdyBTdXBwb3J0IiwgIk1lYW4gU3VwcG9ydCIsICJIaWdoIFN1cHBvcnQiKSkNCg0KDQpSZXN1bHRzLkwydGVzdC40YSRUb2xkLkY8LWZhY3RvcihSZXN1bHRzLkwydGVzdC40YSRUb2xkLkMsDQogICAgICAgICAgICAgICAgICAgICAgICBsZXZlbHM9YyhtaW4oTUxNLkRhdGEuMiRUb2xkLkMpLG1heChNTE0uRGF0YS4yJFRvbGQuQykpLA0KICAgICAgICAgICAgICAgICAgICAgICAgIGxhYmVscz1jKCJFeHBlcmltZW50YWwiLCJXb3JrcyIpKQ0KDQpGaW5hbC5GaXhlZC5QbG90LjMgPC1nZ3Bsb3QoZGF0YSA9IFJlc3VsdHMuTDJ0ZXN0LjRhLCANCiAgICAgICAgICAgICAgICAgICAgICAgICAgICBhZXMoeCA9IEFjdGl2ZVRpbWUuR00sIHkgPWZpdCwgZ3JvdXA9U3VwcG9ydC5GKSkrDQogIGZhY2V0X2dyaWQoLn5Ub2xkLkYpKw0KICBnZW9tX2xpbmUoc2l6ZT0yLCBhZXMoY29sb3I9U3VwcG9ydC5GLGxpbmV0eXBlPVN1cHBvcnQuRikpKw0KICBjb29yZF9jYXJ0ZXNpYW4oeGxpbSA9IGMoLS41LCAuNSkseWxpbSA9IGMoNTAsIDEwMCkpKyANCiAgZ2VvbV9yaWJib24oYWVzKHltaW49Zml0LXNlLCB5bWF4PWZpdCtzZSwgZ3JvdXA9U3VwcG9ydC5GLCBmaWxsPVN1cHBvcnQuRiksYWxwaGE9LjIpKw0KICB4bGFiKCJQcm9wb3J0aW9uIG9mIFRpbWUgRW5nYWdlZCBpbiBBY3RpdmUgTGVhcm5pbmcgXG5DZW50ZXJlZCIpKw0KICB5bGFiKCJNYXRoIFNjb3JlIikrIA0KICB0aGVtZShsZWdlbmQucG9zaXRpb24gPSAidG9wIiwgDQogICAgICAgIGxlZ2VuZC50aXRsZT1lbGVtZW50X2JsYW5rKCkpDQpGaW5hbC5GaXhlZC5QbG90LjMNCmBgYA0KDQojIFJlY29tbWVuYXRpb25zIA0KLSBSYW5kb20gc2xvcGVzIGFuZCBpbnRlcmNlcHRzIGNhbiBwcm90ZWN0IGFnYWluc3QgZGVmbGF0aW9uIG9mIFNFIGFuZCBwcm90ZWN0IGFnYWluc3QgdHlwZSBJIGVycm9yDQotIFdoZW4gdG8gdHJlYXQgc2xvcGVzIGFuZCBpbnRlcmNlcHRzIFtwbHVzIHRoZWlyIGNvcnJlbGF0aW9uc10gYXMgcmFuZG9tPw0KICAgIC0gVWx0cmEgQ29uc2VydmF0aXZlOiBUcmVhdCBldmVyeXRoaW5nIGFzIHJhbmRvbSByZWxhdGl2ZSB0aGUgY2x1c3RlciANCiAgICAgICAgLSBPZnRlbiByZXN1bHRzIGluIGZhaWx1cmUgZm9yIHRoZSBtb2RlbCB0byBmaXQgKHlvdSB3aWxsIHNlZSBsb3RzIG9mIGNvbnZlcmdlbmNlIGVycm9ycykgDQogICAgLSBUaGVvcnktRHJpdmVuOiBGb2xsb3cgeW91ciBkZXNpZ24gYW5kIHRoZW9yeSBhcyB0byB3aGF0IHNob3VsZCBiZSByYW5kb20NCiAgICAgICAgLSBTb21ldGltZXMgdGhlb3JpZXMgYXJlIHdyb25nIGFuZCB0aHVzIHlvdXIgbW9kZWwgd2lsbCBub3QgZml0IHRoZSBkYXRhIGNvcnJlY3RseQ0KICAgIC0gRGF0YSBEcml2ZW46IFVzZSB0aGUgYmVzdCByYW5kb20gc3RydWN0dXJlIGZvciB5b3VyIGRhdGEgDQogICAgICAgIC0gRHJpdmluZyB0byB0aGUgYmVzdCBmaXQgZG9lcyBub3QgYWx3YXlzIGhhdmUgbWVhbmluZyBvciBtYWtlIHNlbnNlIA0KICAgIC0gUmVjb21tZW5kYXRpb246IEJhbGFuY2UgVGhlb3J5IGFuZCBEYXRhLWRyaXZlbiBhcHByb2FjaGVzDQogICAgICAgIC0gR3JhcGggdGhlIGRhdGEsIHNlZSBpdCBmb2xsb3dzIHlvdXIgdGhlb3JpZXMgYW5kIGlmIHRoZSByYW5kb20gc3RydWN0dXJlIG1ha2VzIHNlbnNlDQogICAgICAgIC0gTmV4dCwgd29yayB0b3dhcmRzIGEgcmFuZG9tIHN0cnVjdHVyZSB0aGF0IGlzIGxvZ2ljYWwgYW5kIGZpdHMgdGhlIGRhdGENCi0gQmFsYW5jaW5nIGZpeGVkIGFuZCByYW5kb20gZWZmZWN0cw0KICAgIC0gU29tZXRpbWVzIHlvdXIgZGF0YSBjYW5ub3QgaGFuZGxlIGJlaW5nIHRyZWF0ZWQgYXMgcmFuZG9tIGFuZCBmaXhlZA0KICAgICAgICAtIFlvdSBjYW5ub3QganVzdCB0cmVhdCBldmVyeXRoaW5nIGFzIHJhbmRvbSBhcyB3ZSBzYXcgYmVjYXVzZSBpbiB0aGlzIGNyYXp5IGNhc2UgaXQgd2FzIG5vdCByZWFsbHkgcmFuZG9tIChpdCB3YXMgYWxsIHN5c21hdGljIGVycm9yIGR1ZSkuIFRoaXMgd2FzIGFuIGV4dHJlbWUgZXhhbXBsZSBpbiBzb21lIHNlbnNlLCBidXQgSSBoYXZlIHNlZW4gbWFueSB0aW1lcyB3aGVuIHRoZSByYW5kb20gc3RydWN0dXJlIGZhbGxzIGFwYXJ0LiAgVGhpcyBpcyB2ZXJ5IGNvbW1vbiBpcyBzbWFsbCBOIG9yIHNtYWxsIGNsdXN0ZXJzLiANCiAgICAtIE90aGVyIHRpbWVzIHlvdSB3aWxsIGFkZCBhIHJhbmRvbSBlZmZlY3QsIGFuZCB5b3VyIGVmZmVjdCBvZiBpbnRlcmVzdCB3aWxsIGRpc2FwcGVhcg0KICAgICAgICAtIERvZXMgdGhhdCBtZWFuIHlvdXIgcmVzdWx0cyB3YXMgdHlwZSAxIGVycm9yPyANCiAgICAgICAgICAgIC0gTm90IGFsd2F5czogV2F0Y2ggeW91ciByYW5kb20gc3RydWN0dXJlIGNsb3NlbHksIHRoZSBjb3JyZWxhdGlvbnMsIGFuZCBncmFwaCB0aGUgbW9kZWwgZml0IA0KICAgICAgICAgICAgLSBDb21wYXJlIHlvdXIgZml0IHRvIHlvdXIgc3BhZ2hldHRpIHBsb3RzISANCiAgICAtIFdhdGNoIGNhcmVmdWxseSBob3cgdGhlIGZpeGVkIGVmZmVjdCBhbmQgcmFuZG9tIGVmZmVjdCBjaGFuZ2UgYXMgeW91IGFkZCBuZXcgZml4ZWQgdGVybS4gQXMgeW91IGFkZCBtYW55IGZpeGVkIHRlcm1zICAoeW91IGNvdWxkIGhhdmUgbXVsdGljb2xsaW5lYXJpdHkgb3Igc3VwcHJlc3Npb24gZWZmZWN0cykNCg0KICAgIA0KICAgICAgICANCiAgDQo8c2NyaXB0Pg0KICAoZnVuY3Rpb24oaSxzLG8sZyxyLGEsbSl7aVsnR29vZ2xlQW5hbHl0aWNzT2JqZWN0J109cjtpW3JdPWlbcl18fGZ1bmN0aW9uKCl7DQogIChpW3JdLnE9aVtyXS5xfHxbXSkucHVzaChhcmd1bWVudHMpfSxpW3JdLmw9MSpuZXcgRGF0ZSgpO2E9cy5jcmVhdGVFbGVtZW50KG8pLA0KICBtPXMuZ2V0RWxlbWVudHNCeVRhZ05hbWUobylbMF07YS5hc3luYz0xO2Euc3JjPWc7bS5wYXJlbnROb2RlLmluc2VydEJlZm9yZShhLG0pDQogIH0pKHdpbmRvdyxkb2N1bWVudCwnc2NyaXB0JywnaHR0cHM6Ly93d3cuZ29vZ2xlLWFuYWx5dGljcy5jb20vYW5hbHl0aWNzLmpzJywnZ2EnKTsNCg0KICBnYSgnY3JlYXRlJywgJ1VBLTkwNDE1MTYwLTEnLCAnYXV0bycpOw0KICBnYSgnc2VuZCcsICdwYWdldmlldycpOw0KDQo8L3NjcmlwdD4NCiAgICANCiAgICA=