Linear Mixed Models
Mixed Models
- Multiple regressions only have fixed-effects [continuous] or fixed-factors [groups]: variables of interest (often your manipulation)
- The only random factor assumed is your subject’s response
- What if you have other effects or factors that might add random variation?
- Random-effects/factors: Levels randomly sampled from a much larger population: Something you want to generalize across: Subjects, Words, Pictures, etc
Type of Mixed Models
- We will explore crossed designs
Nested designs
- Problem: Clustering means each student’s scores within each
classroom might be correlated because they all have the same teacher
(for example)
- Multilevel/Hierarchical designs: Students nested in classrooms [Clustered data]
Crossed designs
- Problem: Each person’s response is going to inter-correlated with
their other responses
- Repeated measures: everyone does all the conditions
- Longitudinal data: People are tracked over time
- Growth Curve Models: Fitting functions (like polynomials) to behavior over time
Crossed & Nested designs
- Now each person’s response is going to inter-correlated with their
other responses, but that correlation might differ by which group they
belong too
- Longitudinal Multilevel Designs: Students nested in classrooms measured over many months
- Partially Nested design: Different groups are measures over time
Inter-Correlations
- All these correlations inflate your type I error if you don’t treat the data correctly
Practice data to make sense of random effects
- Hypothetical Experiment, n = 6
- DV: % of how happy they are
- IV1: Time of measurement: 5 time windows
- IV2: Social Setting: Alone vs With a group
As 2x5 RM ANOVA
- Treats Time-Steps as a factor
- Are there any differences between any time-steps?
- Not slopes (predictable changes in time)
- Treats Social as a factor
- Is there a difference between Alone and With Group
- Questions: Is there an effect of time and Social?
library(lme4) #mixed model package by Douglas Bates
library(afex) #easy ANOVA package
library(ggplot2) #GGplot package for visualizing data
source("HelperFunctions.R") # some custom functions
###Read in Data file
HappyData <- read.csv("Mixed/HappyStudy.csv", header=T)
### Label variables
HappyData$Social <- factor(HappyData$SocialDummy,
levels = c(0,1),
labels = c("Alone", "Group"))
HappyData$Subject<-as.factor(HappyData$Subject)- Let’s plot each person’s data (spaghetti plot)
theme_set(theme_bw(base_size = 12, base_family = ""))
pab <-ggplot(data = HappyData, aes(x = TimeStep, y=HappyPercent, group=Subject))+
facet_grid( ~ Social, labeller=label_both)+
# coord_cartesian(ylim = c(.03,.074))+
geom_line(aes(color=Subject))+
xlab("Time Step")+ylab("Happiness")
pab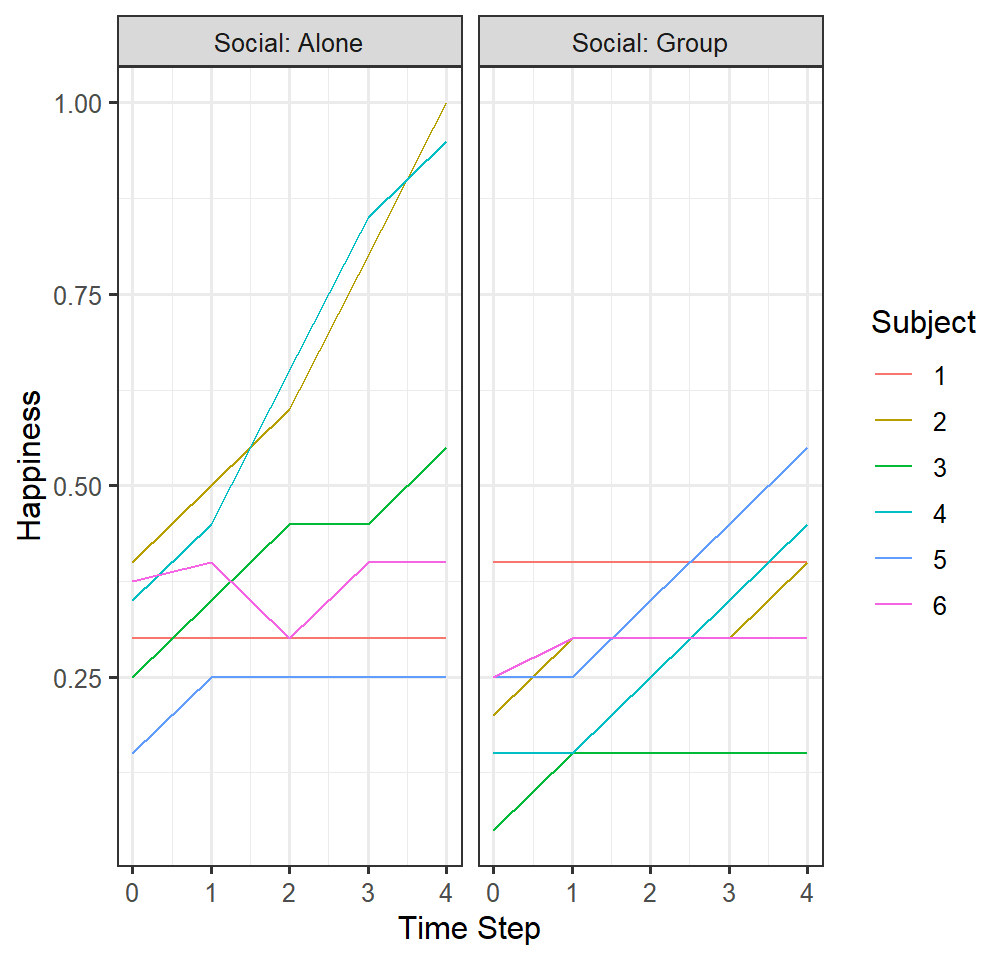
- Let’s plot each person’s data with the means plotted
##custom function to generate means and SE form any long format dataset.
HappyDataPlot2<-summarySEwithin(HappyData,measurevar="HappyPercent",
withinvars=c("Social","TimeStep"),
idvar="Subject", na.rm=FALSE, conf.interval=.95)
pab2 <-ggplot()+
geom_line(data = HappyData, aes(x = as.factor(TimeStep), y =HappyPercent, group=Subject, color=Subject))+
facet_grid(. ~ Social, labeller=label_both)+
# coord_cartesian(ylim = c(.03,.074))+
geom_point(data = HappyDataPlot2, aes(x = as.factor(TimeStep), y =HappyPercent, group=Social))+
geom_errorbar(data = HappyDataPlot2,aes(x = as.factor(TimeStep), y =HappyPercent, group=Social, ymin=HappyPercent-se, ymax=HappyPercent+se),colour="#6E6E6E",size=.25, width=.25)+
xlab("Time Step")+ylab("Happiness")
pab2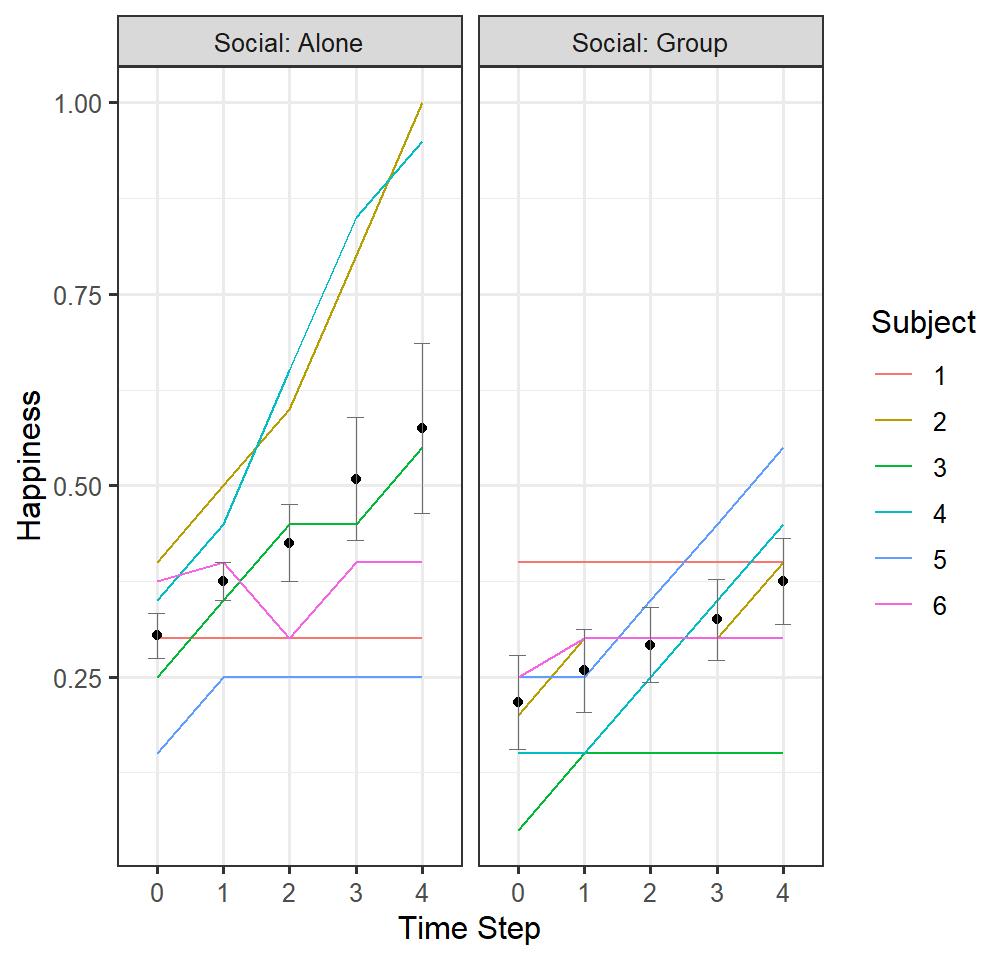
- Let’s examine an RM ANOVA results of this data
- Remember time is treated like a factor (not a slope)
- [Note: I ran the ANOVA like a GLM just so we can extract an overall \(R^2\) and get a fitted result for each subject]
#######Anova (using type 3 sum of squares same as default in SPSS/SAS)
Anova.Model1 <-aov_car(HappyPercent ~ Social*TimeStep + Error(Subject/(Social*TimeStep)),
data = HappyData, anova_table = list(correction = "none", MSE = FALSE))
Anova.Model1
###### General Linear Model (same as ANOVA, but uses type 1 sum of squares)
GLM.model<-glm(HappyPercent ~ Social*TimeStep, data=HappyData)
#fit data
HappyData$GLMfitted<-fitted(GLM.model)
#manually extract R2 to compare to mixed models
summary(lm(HappyPercent ~ GLMfitted, data=HappyData))$r.squared## Anova Table (Type 3 tests)
##
## Response: HappyPercent
## Effect df F ges p.value
## 1 Social 1, 5 2.36 .183 .185
## 2 TimeStep 4, 20 6.91 ** .195 .001
## 3 Social:TimeStep 4, 20 1.11 .018 .381
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '+' 0.1 ' ' 1
## [1] 0.325839- We can fit the GLM/ANOVA estimate for every single subject
- How is our ANOVA doing in predicting each subject?
- ANOVA is not predicting subject level; it is testing/predicting at the average level of the data
- However, if we have longitudinal-like data (like in this study) why not make predictions at the subject-level?
FittedGlmPlot1 <-ggplot()+
facet_grid(Subject ~ Social, labeller=label_both)+
geom_line(data = HappyData, aes(x = TimeStep, y =GLMfitted))+
geom_point(data = HappyData, aes(x = TimeStep, y =HappyPercent, group=Subject,colour = Subject),size=3)+
xlab("Time Step")+ylab("Happiness")
FittedGlmPlot1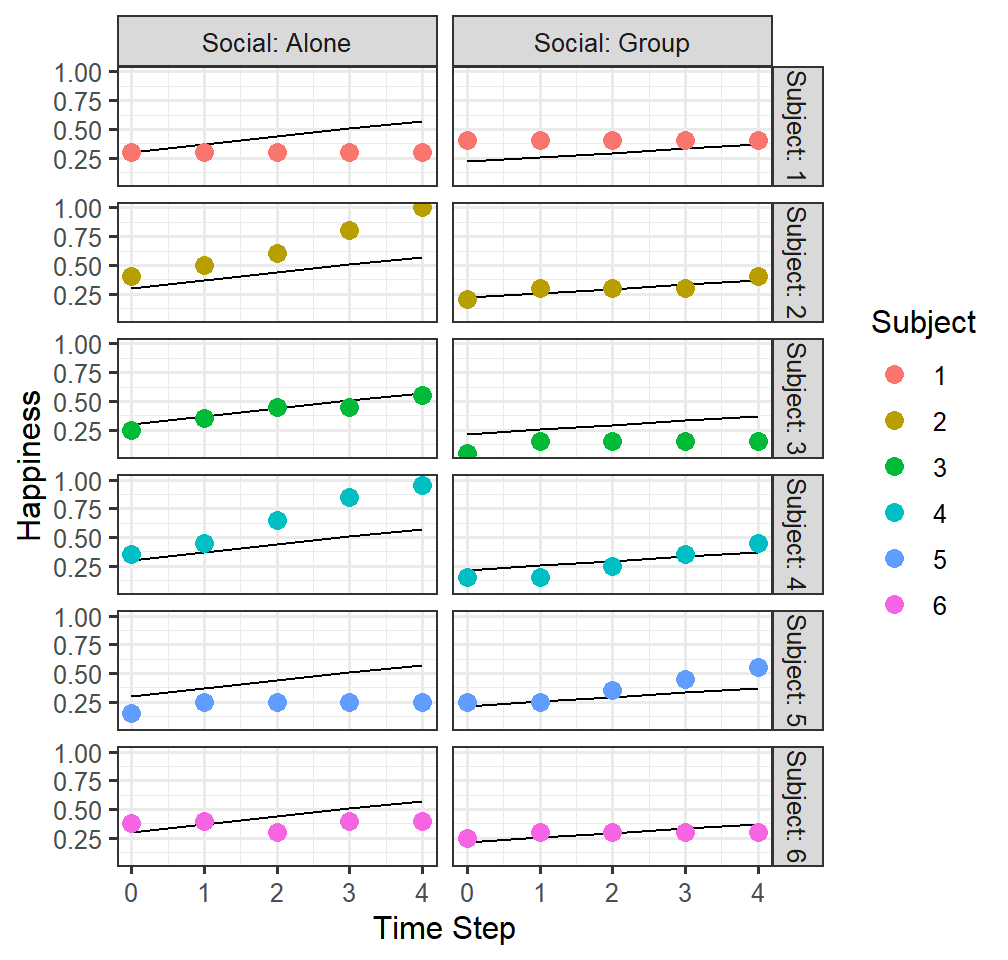
Random Effect Modeling: Fitting at different levels
- Linear regression assumes one measurement per subject, but what is you have multiple measurements per subject?
- If we have longitudinal data per subject we could estimate a slope per subject!
- We could then extract the slopes estimates per subject [and do statistics on the slopes per subject]
- But we lose the variances around those slopes! Such as below.
FittedlmPlot <-ggplot(data = HappyData, aes(x = TimeStep, y =HappyPercent, group=Subject))+
facet_grid(Subject ~ Social, labeller=label_both)+
geom_point(aes(colour = Subject), size=3)+
geom_smooth(method = "lm",se=FALSE, color ="black", size=.5) +
xlab("Time Step")+ylab("Happiness")
FittedlmPlot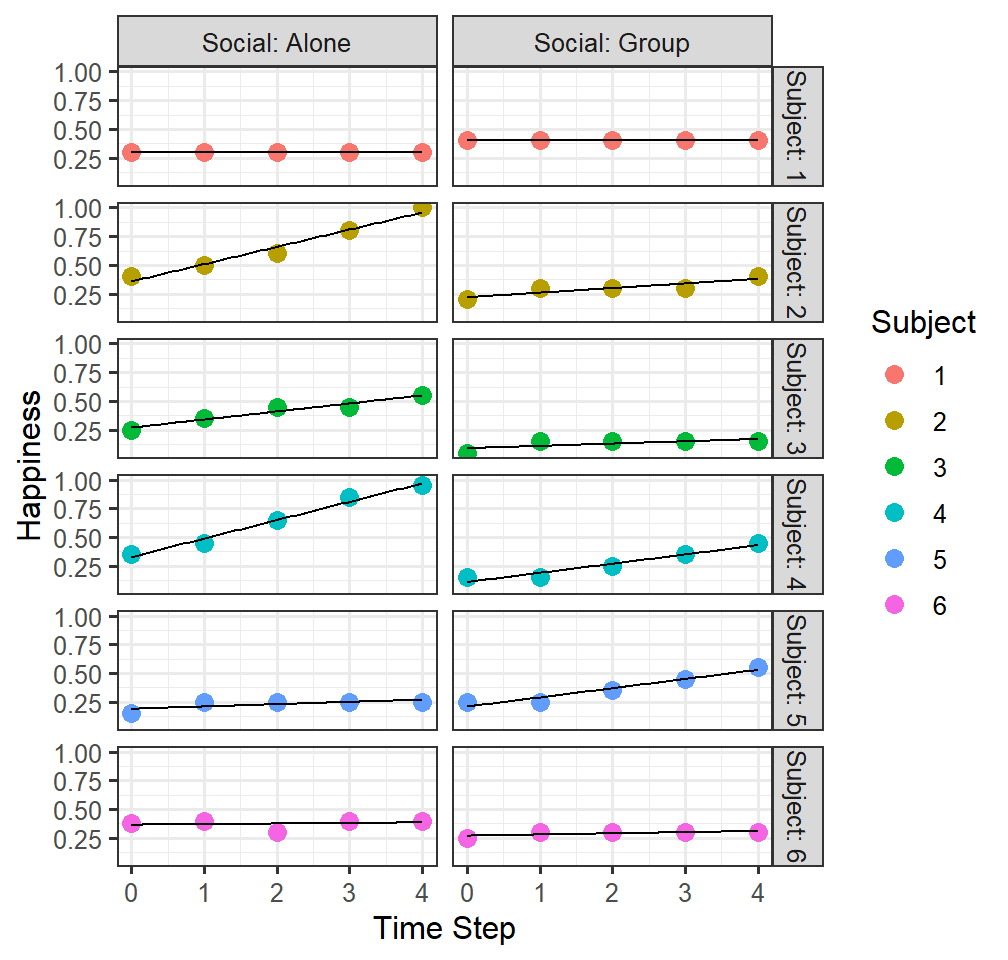
Random intercepts
- So we need to get a regression model to try to fit at the subject
level
(1|Subject)means each subject can have their own interceptREML=FALSEmeans fit the with maximum likelihood [like we did with GLM]
- You can see the random, fixed terms, and correlations between the fixed terms
Model.1<-lmer(HappyPercent ~Social*TimeStep
+(1|Subject),
data=HappyData, REML=FALSE)
summary(Model.1, correlations=FALSE)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: HappyPercent ~ Social * TimeStep + (1 | Subject)
## Data: HappyData
##
## AIC BIC logLik deviance df.resid
## -48.5 -36.0 30.3 -60.5 54
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.01279 -0.74343 0.06896 0.56894 2.52851
##
## Random effects:
## Groups Name Variance Std.Dev.
## Subject (Intercept) 0.004231 0.06505
## Residual 0.018986 0.13779
## Number of obs: 60, groups: Subject, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 0.30250 0.05103 30.77293 5.928 1.55e-06 ***
## SocialGroup -0.08583 0.06162 54.00000 -1.393 0.169358
## TimeStep 0.06750 0.01779 54.00000 3.795 0.000376 ***
## SocialGroup:TimeStep -0.02917 0.02516 54.00000 -1.159 0.251401
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) SclGrp TimStp
## SocialGroup -0.604
## TimeStep -0.697 0.577
## SclGrp:TmSt 0.493 -0.816 -0.707- Next, we examine the intercepts for each person
- The var and sd of these values are what was seen in the table above
ranef(Model.1)## $Subject
## (Intercept)
## 1 -0.01064173
## 2 0.07909391
## 3 -0.06586366
## 4 0.06528843
## 5 -0.04515543
## 6 -0.02272152
##
## with conditional variances for "Subject"- We can examine an \(R^2\) for the models, but we have a problem
- Is the \(R^2\) coming from the fixed or random effect? We can parse that:
- The marginal is the \(R^2\) for the fixed effects
- The conditional \(R^2\) includes random + fixed effects
- There is no standard as to which to report \(R^2\) and most people never report these at all as if the random effects are complex (nested, or crossed) the meaning of them changes
library(performance)
r2_nakagawa(Model.1)## # R2 for Mixed Models
##
## Conditional R2: 0.452
## Marginal R2: 0.330- Let’s plot the model fit
HappyData$Model.1.fitted<-predict(Model.1)
FittedlmPlot1 <-ggplot()+
facet_grid(Subject ~ Social, labeller=label_both)+
geom_line(data = HappyData, aes(x = TimeStep, y =Model.1.fitted))+
geom_point(data = HappyData, aes(x = TimeStep, y =HappyPercent, group=Subject,colour = Subject), size=3)+
xlab("Time Step")+ylab("Happiness")
FittedlmPlot1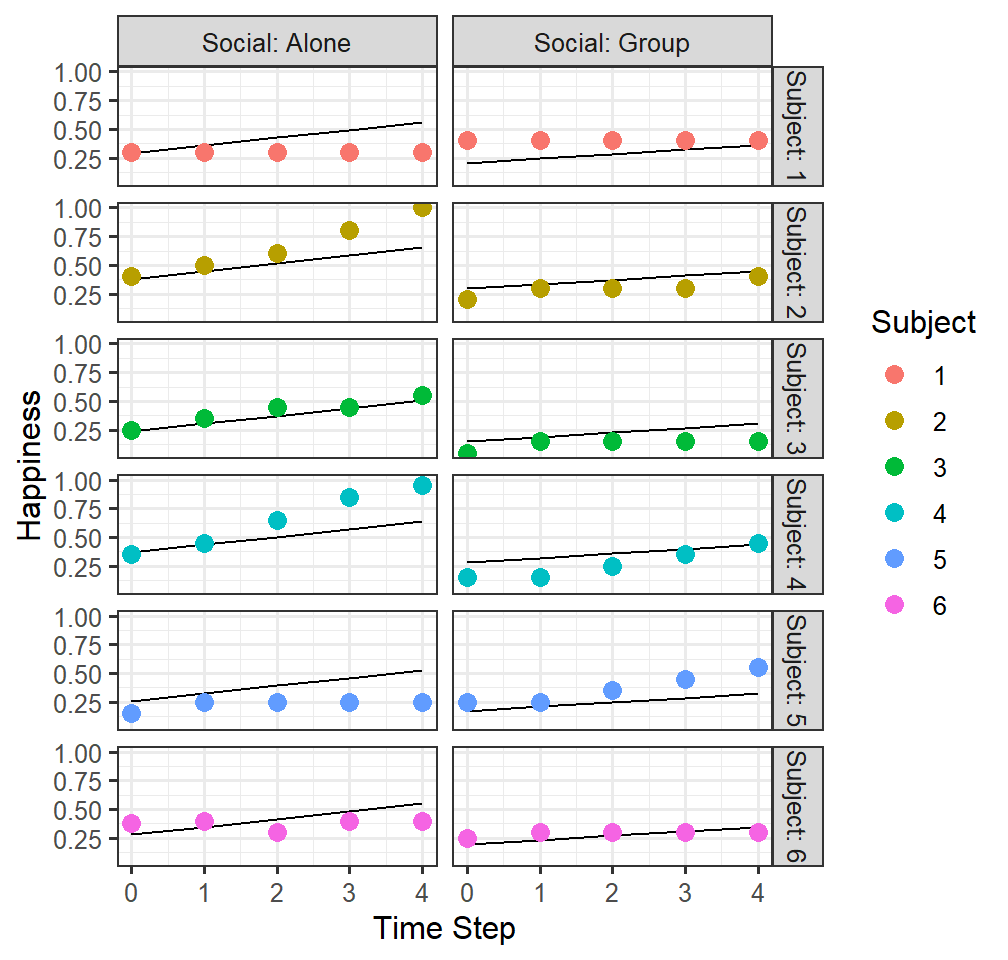
Random intercept and slopes for the social condition
- Model 2 treats that Social condition as free to vary between
Subjects, but accounts for the correlation within Subjects between the
Social condition)
(1+Social|Subject)means each subject can have their intercept and social condition can vary as a function of the subject
- The correlations of the random terms are the correlations of each subjects’ intercept and slope of social condition
Model.2<-lmer(HappyPercent ~Social*TimeStep
+(1+Social|Subject),
data=HappyData, REML=FALSE)
summary(Model.2, correlations=FALSE)
ranef(Model.2)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: HappyPercent ~ Social * TimeStep + (1 + Social | Subject)
## Data: HappyData
##
## AIC BIC logLik deviance df.resid
## -80.6 -63.9 48.3 -96.6 52
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.74976 -0.65978 -0.08771 0.53103 2.52126
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Subject (Intercept) 0.025365 0.15926
## SocialGroup 0.041054 0.20262 -0.94
## Residual 0.007582 0.08708
## Number of obs: 60, groups: Subject, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 0.30250 0.07061 7.41852 4.284 0.00318 **
## SocialGroup -0.08583 0.09143 7.74635 -0.939 0.37617
## TimeStep 0.06750 0.01124 48.00001 6.004 2.47e-07 ***
## SocialGroup:TimeStep -0.02917 0.01590 48.00001 -1.835 0.07277 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) SclGrp TimStp
## SocialGroup -0.899
## TimeStep -0.318 0.246
## SclGrp:TmSt 0.225 -0.348 -0.707
## $Subject
## (Intercept) SocialGroup
## 1 -0.13319227 0.22090410
## 2 0.20795560 -0.21223660
## 3 -0.01883687 -0.10541513
## 4 0.19986403 -0.22675775
## 5 -0.19743771 0.26507163
## 6 -0.05835279 0.05843375
##
## with conditional variances for "Subject"- The \(R^2\) for fixed and random
r2_nakagawa(Model.2)## # R2 for Mixed Models
##
## Conditional R2: 0.781
## Marginal R2: 0.330- Plot the model results
HappyData$Model.2.fitted<-predict(Model.2)
FittedlmPlot2 <-ggplot()+
facet_grid(Subject ~ Social, labeller=label_both)+
geom_line(data = HappyData, aes(x = TimeStep, y=Model.2.fitted))+
geom_point(data = HappyData, aes(x = TimeStep, y =HappyPercent, group=Subject,colour = Subject), size=3)+
# coord_cartesian(ylim = c(.03,.074))+
xlab("Time Step")+ylab("Happiness")
FittedlmPlot2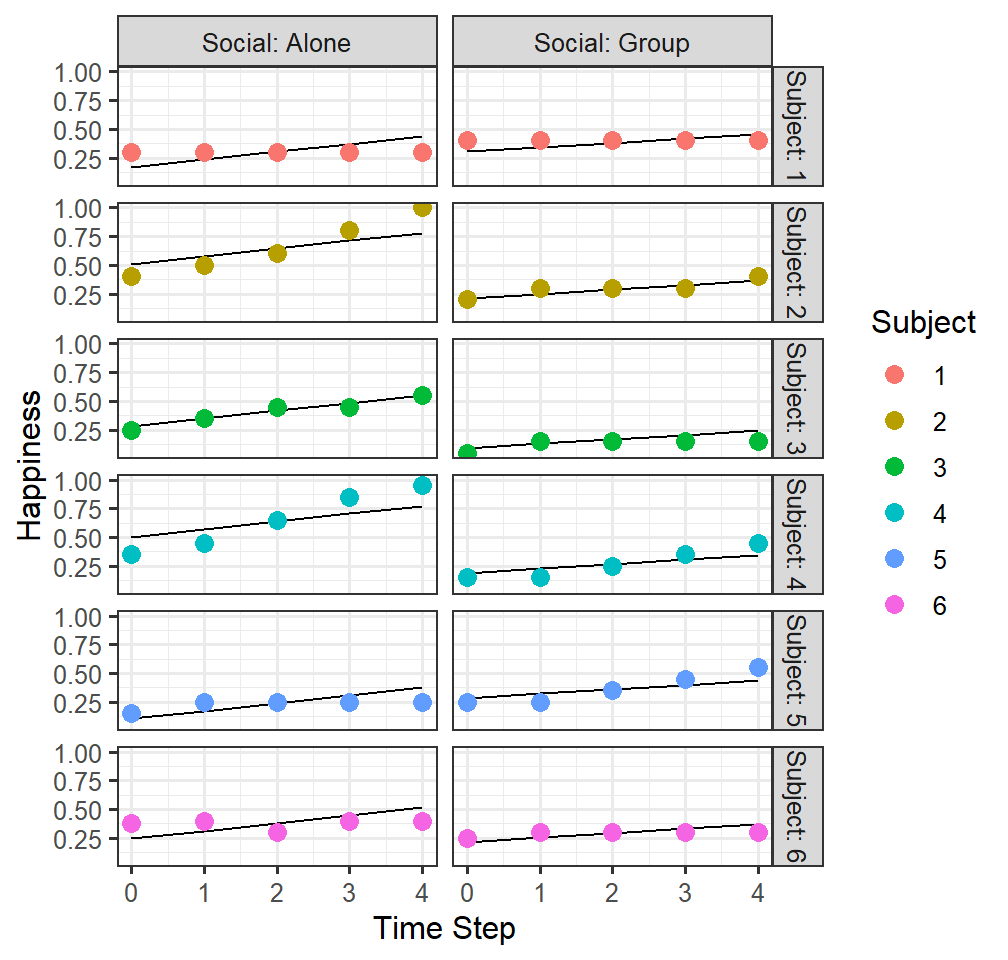
Random intercepts and slopes for time
- Model 3 treats that timesteps as free to vary between Subjects, but
accounts for the correlation within Subjects across time
(1+TimeStep|Subject)means each subject can have their intercept and time slope can vary as a function of the subject
- The correlations of the random terms are the correlations of each subjects’ intercept and slope of time
Model.3<-lmer(HappyPercent ~Social*TimeStep
+(1+TimeStep|Subject),
data=HappyData, REML=FALSE)
summary(Model.3, correlations=FALSE)
ranef(Model.3)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: HappyPercent ~ Social * TimeStep + (1 + TimeStep | Subject)
## Data: HappyData
##
## AIC BIC logLik deviance df.resid
## -50.7 -34.0 33.4 -66.7 52
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.94803 -0.77296 0.08334 0.68945 2.02418
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Subject (Intercept) 0.000000 0.00000
## TimeStep 0.001151 0.03393 NaN
## Residual 0.016312 0.12772
## Number of obs: 60, groups: Subject, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 0.30250 0.04039 54.00000 7.490 6.6e-10 ***
## SocialGroup -0.08583 0.05712 54.00000 -1.503 0.13873
## TimeStep 0.06750 0.02153 20.23059 3.135 0.00517 **
## SocialGroup:TimeStep -0.02917 0.02332 54.00000 -1.251 0.21639
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) SclGrp TimStp
## SocialGroup -0.707
## TimeStep -0.625 0.442
## SclGrp:TmSt 0.577 -0.816 -0.541
## optimizer (nloptwrap) convergence code: 0 (OK)
## boundary (singular) fit: see help('isSingular')
##
## $Subject
## (Intercept) TimeStep
## 1 0 -0.01842559
## 2 0 0.04224404
## 3 0 -0.02786309
## 4 0 0.04359225
## 5 0 -0.01842559
## 6 0 -0.02112202
##
## with conditional variances for "Subject"- The \(R^2\) for fixed and random
r2_nakagawa(Model.3)## Random effect variances not available. Returned R2 does not account for random effects.
## # R2 for Mixed Models
##
## Conditional R2: NA
## Marginal R2: 0.412- Plot the model results
HappyData$Model.3.fitted<-predict(Model.3)
FittedlmPlot3 <-ggplot()+
facet_grid(Subject ~ Social, labeller=label_both)+
geom_line(data = HappyData, aes(x = TimeStep, y =Model.3.fitted))+
geom_point(data = HappyData, aes(x = TimeStep, y =HappyPercent, group=Subject,colour = Subject), size=3)+
# coord_cartesian(ylim = c(.03,.074))+
xlab("Time Step")+ylab("Happiness")
FittedlmPlot3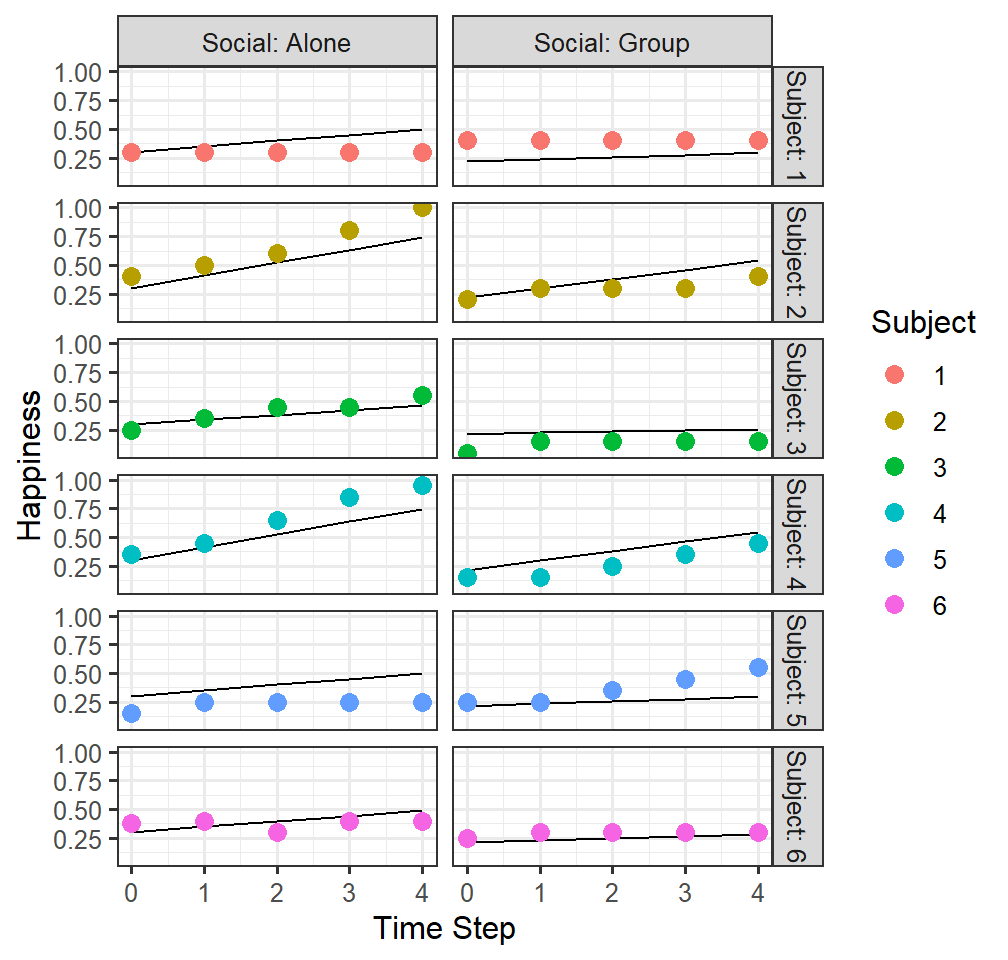
Random intercepts and slopes for time and social (but independent)
- Model 4 treats that timesteps and Social as free to vary between
Subjects but accounts for the correlation within Subjects across times
and social
(1+Social|Subject)+(0+TimeStep|Subject)means each subject can have their intercept and can have their slope of social condition
- Also, time slope can vary as a function of the subject, but it treats the variance between social and time as independent
Model.4<-lmer(HappyPercent ~Social*TimeStep
+(1+Social|Subject)+(0+TimeStep|Subject),
data=HappyData, REML=FALSE)
summary(Model.4, correlations=FALSE)
ranef(Model.4)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: HappyPercent ~ Social * TimeStep + (1 + Social | Subject) + (0 +
## TimeStep | Subject)
## Data: HappyData
##
## AIC BIC logLik deviance df.resid
## -104.5 -85.7 61.3 -122.5 51
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.87709 -0.58050 0.03998 0.52475 2.22036
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Subject (Intercept) 0.010881 0.10431
## SocialGroup 0.042748 0.20676 -0.88
## Subject.1 TimeStep 0.001580 0.03975
## Residual 0.003363 0.05799
## Number of obs: 60, groups: Subject, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 0.30250 0.04637 6.68620 6.524 0.000396 ***
## SocialGroup -0.08583 0.08830 6.74963 -0.972 0.364565
## TimeStep 0.06750 0.01787 7.30670 3.777 0.006390 **
## SocialGroup:TimeStep -0.02917 0.01059 41.24318 -2.755 0.008699 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) SclGrp TimStp
## SocialGroup -0.854
## TimeStep -0.135 0.071
## SclGrp:TmSt 0.228 -0.240 -0.296
## $Subject
## (Intercept) SocialGroup TimeStep
## 1 -0.057375747 0.23815690 -0.041860305
## 2 0.128676074 -0.20816844 0.042516614
## 3 0.005939829 -0.13327397 -0.013725144
## 4 0.091619257 -0.22893624 0.059397968
## 5 -0.176138708 0.27387216 -0.009377556
## 6 0.007279295 0.05834959 -0.036951577
##
## with conditional variances for "Subject"- The \(R^2\) for fixed and random
r2_nakagawa(Model.4)## # R2 for Mixed Models
##
## Conditional R2: 0.880
## Marginal R2: 0.407- Plot the model results
HappyData$Model.4.fitted<-predict(Model.4)
FittedlmPlot4 <-ggplot()+
facet_grid(Subject ~ Social, labeller=label_both)+
geom_line(data = HappyData, aes(x = TimeStep, y =Model.4.fitted))+
geom_point(data = HappyData, aes(x = TimeStep, y =HappyPercent, group=Subject,colour = Subject), size=3)+
# coord_cartesian(ylim = c(.03,.074))+
xlab("Time Step")+ylab("Happiness")
FittedlmPlot4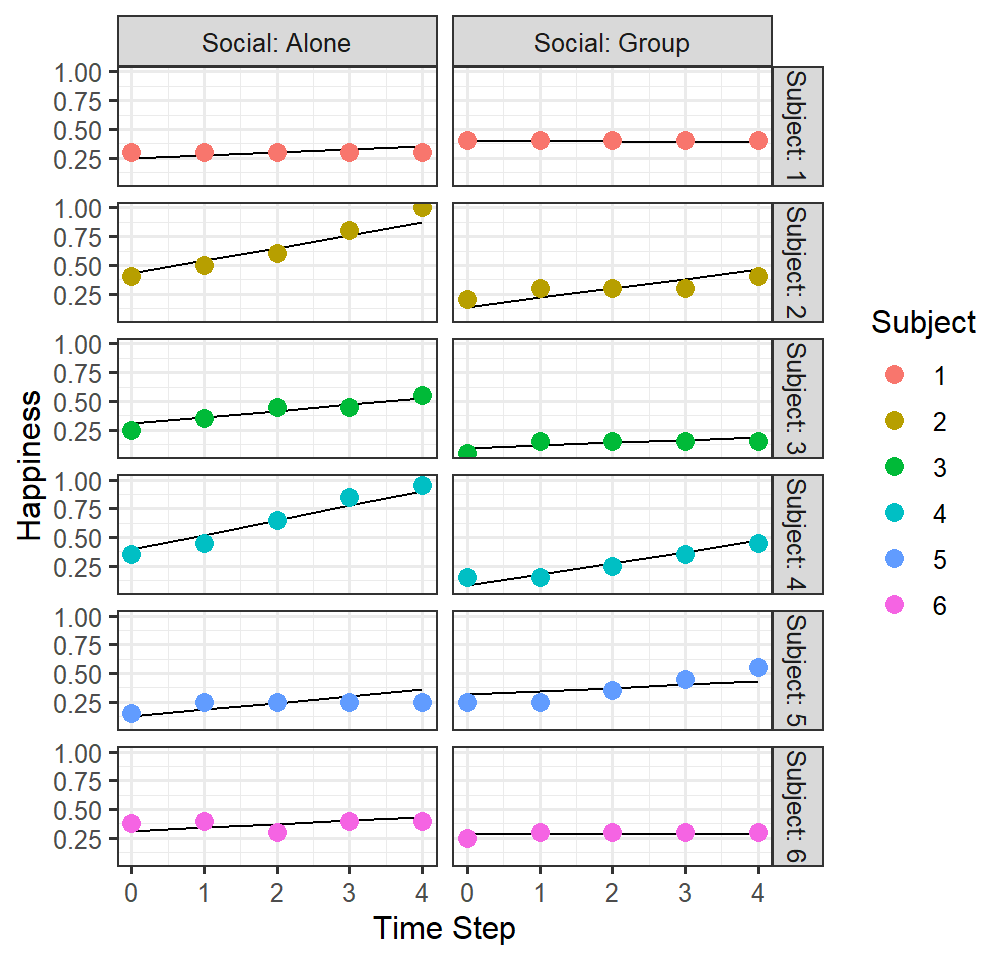
Random intercepts and slopes for time and social (but not independent)
- Model 5 treats that timesteps and Social as free to vary between
Subjects but accounts for the correlation within Subjects across time
and Social
(1+Social+ TimeStep|Subject)means each subject can have their intercept and can have their slope of social condition
- Also, time slope can vary as a function of the subject, but it treats the variance between social and time as correlated
Model.5<-lmer(HappyPercent ~Social*TimeStep
+(1+Social+TimeStep|Subject),
data=HappyData, REML=FALSE)
summary(Model.5, correlations=FALSE)
ranef(Model.5)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: HappyPercent ~ Social * TimeStep + (1 + Social + TimeStep | Subject)
## Data: HappyData
##
## AIC BIC logLik deviance df.resid
## -106.1 -83.1 64.1 -128.1 49
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.75667 -0.64187 0.01123 0.46691 2.32345
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Subject (Intercept) 0.009981 0.09991
## SocialGroup 0.042755 0.20677 -0.86
## TimeStep 0.001701 0.04124 0.57 -0.79
## Residual 0.003330 0.05771
## Number of obs: 60, groups: Subject, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 0.30250 0.04468 6.72430 6.770 0.000311 ***
## SocialGroup -0.08583 0.08827 6.74363 -0.972 0.364436
## TimeStep 0.06750 0.01841 7.10947 3.666 0.007791 **
## SocialGroup:TimeStep -0.02917 0.01054 41.99980 -2.768 0.008346 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) SclGrp TimStp
## SocialGroup -0.832
## TimeStep 0.343 -0.620
## SclGrp:TmSt 0.236 -0.239 -0.286
## $Subject
## (Intercept) SocialGroup TimeStep
## 1 -0.048404623 0.23920407 -0.046420455
## 2 0.127197739 -0.21291500 0.043738980
## 3 -0.007510835 -0.12257436 -0.008039099
## 4 0.088893308 -0.23639018 0.061465980
## 5 -0.166304142 0.26705599 -0.013706674
## 6 0.006128553 0.06561948 -0.037038731
##
## with conditional variances for "Subject"- The \(R^2\) for fixed and random
r2_nakagawa(Model.5)## # R2 for Mixed Models
##
## Conditional R2: 0.904
## Marginal R2: 0.330- Plot the model results
HappyData$Model.5.fitted<-predict(Model.5)
FittedlmPlot5 <-ggplot()+
facet_grid(Subject ~ Social, labeller=label_both)+
geom_line(data = HappyData, aes(x = TimeStep, y =Model.5.fitted))+
geom_point(data = HappyData, aes(x = TimeStep, y =HappyPercent, group=Subject,colour = Subject), size=3)+
# coord_cartesian(ylim = c(.03,.074))+
xlab("Time Step")+ylab("Happiness")
FittedlmPlot5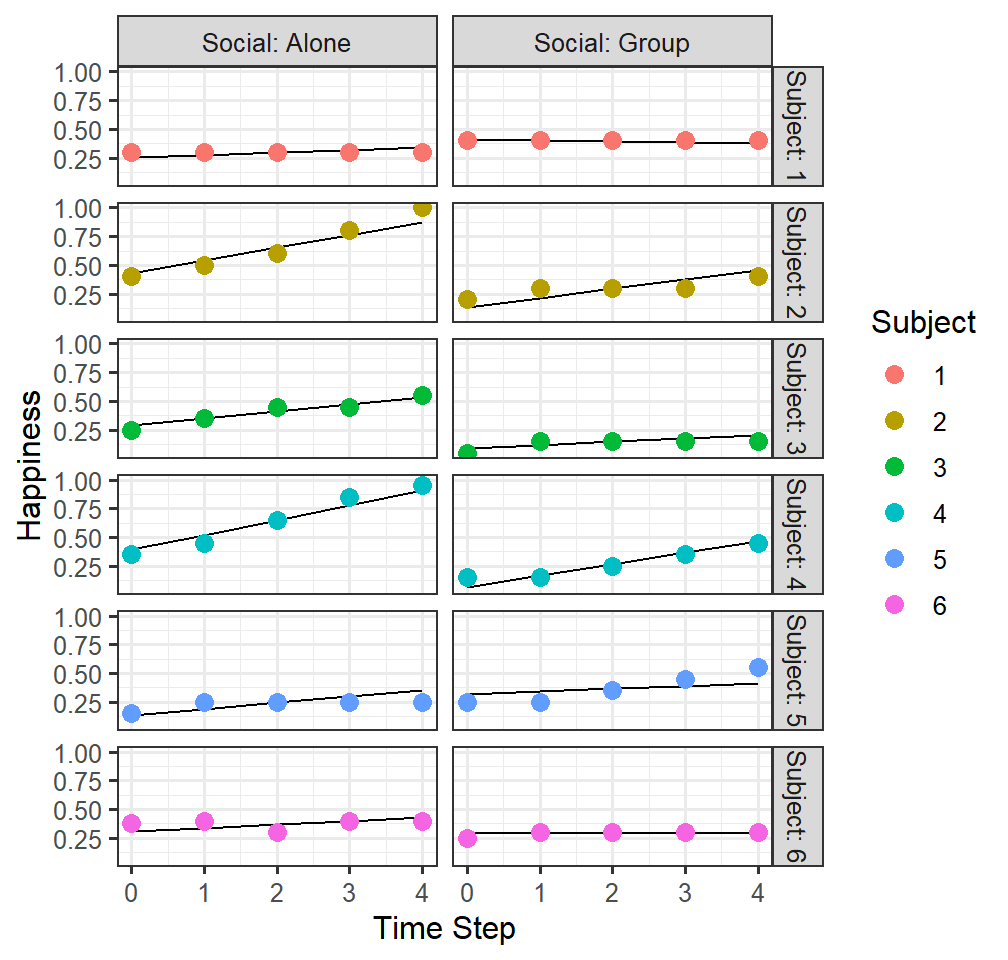
Random intercepts and slopes for time x social
- Model 6 treats that timesteps, Social and timesteps:Social
(interaction) as free to vary between Subjects but accounts for the
correlation within Subjects across time and Social
(1+Social*TimeStep|Subject)means(1+Social+TimeStep+Social:TimeStep|Subject)each subject can have their intercept, their slope of social condition, their time slope, and their interaction between social and time
- Also, all random slopes and intercepts can be correlated
- This is called the maximum model Barr et al., 2013 (these do not always fit best see Bates et al., 2015)
Model.6<-lmer(HappyPercent ~Social*TimeStep
+(1+Social*TimeStep|Subject),
data=HappyData, REML=FALSE)
summary(Model.6, correlations=FALSE)
ranef(Model.6)## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: HappyPercent ~ Social * TimeStep + (1 + Social * TimeStep | Subject)
## Data: HappyData
##
## AIC BIC logLik deviance df.resid
## -142.2 -110.8 86.1 -172.2 45
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.92979 -0.57518 0.06785 0.52187 1.63727
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Subject (Intercept) 0.003024 0.05499
## SocialGroup 0.011462 0.10706 -0.38
## TimeStep 0.004246 0.06516 0.46 -0.84
## SocialGroup:TimeStep 0.003061 0.05533 -0.79 0.84 -0.89
## Residual 0.001137 0.03372
## Number of obs: 60, groups: Subject, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 0.30250 0.02485 6.10702 12.172 1.64e-05 ***
## SocialGroup -0.08583 0.04624 6.05010 -1.856 0.1124
## TimeStep 0.06750 0.02696 6.00466 2.504 0.0462 *
## SocialGroup:TimeStep -0.02917 0.02341 6.02192 -1.246 0.2591
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) SclGrp TimStp
## SocialGroup -0.424
## TimeStep 0.357 -0.753
## SclGrp:TmSt -0.620 0.697 -0.875
## $Subject
## (Intercept) SocialGroup TimeStep SocialGroup:TimeStep
## 1 0.01347014 0.14914062 -0.07346568 0.04327375
## 2 0.06811478 -0.07643351 0.07762432 -0.07145605
## 3 -0.01596821 -0.11402999 -0.00324552 -0.01100070
## 4 0.01793845 -0.11310785 0.09555100 -0.05939808
## 5 -0.10556486 0.10825514 -0.04924558 0.08583846
## 6 0.02200970 0.04617559 -0.04721854 0.01274262
##
## with conditional variances for "Subject"- The \(R^2\) for fixed and random
r2_nakagawa(Model.6)## # R2 for Mixed Models
##
## Conditional R2: 0.967
## Marginal R2: 0.330- Plot the model results
HappyData$Model.6.fitted<-predict(Model.6)
FittedlmPlot6 <-ggplot()+
facet_grid(Subject ~ Social, labeller=label_both)+
geom_line(data = HappyData, aes(x = TimeStep, y =Model.6.fitted))+
geom_point(data = HappyData, aes(x = TimeStep, y =HappyPercent, group=Subject,colour = Subject), size=3)+
# coord_cartesian(ylim = c(.03,.074))+
xlab("Time Step")+ylab("Happiness")
FittedlmPlot6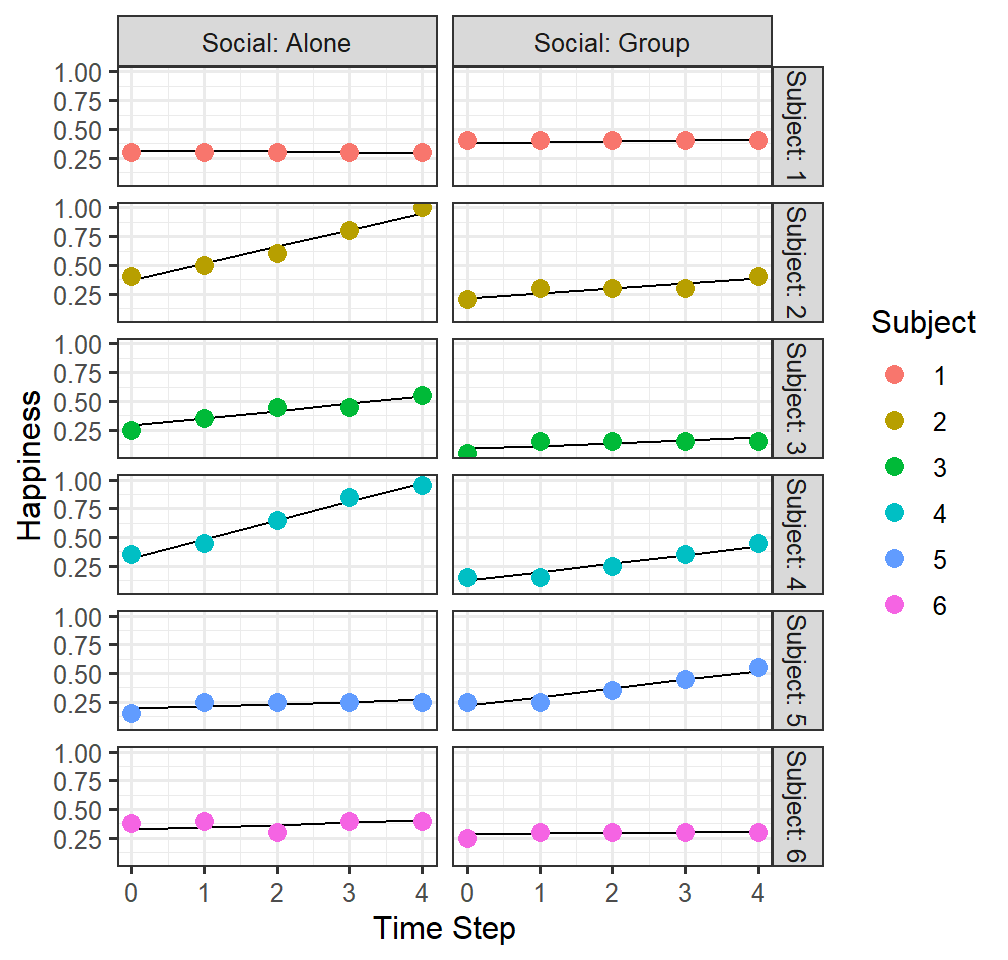
How to select a random structure
- First, these models often fail to converge
- Convergence mean that the optimizer (numerical
method to find the parameters) has failed to reach an optimal or stable
solution
- There are many optimizers to select from in R if you need to change it (https://rstudio-pubs-static.s3.amazonaws.com/33653_57fc7b8e5d484c909b615d8633c01d51.html)
- Failures might not just be a numerical optimization problem, but a problem with your specification of the random effects
- You could over-specify your random effects in a way that is not
parsimonious with the true random effects in the population
- You could set them up in such a way that do not reflect the experiment
Practical Solution to random structure
- This is a battlefield in LMM
- The current best practice is to try to match your design as best as
you can
- If that fails, try different optimizer
- If that fails, reduce the complexity of the random effect (remove random correlations one at a time)
- If that fails, follow the set of procedures here: http://www.alexanderdemos.org/Mixed8.html
- If you under-specify, you inflate your type I error, so it a balancing act
Fixed effects
- Just like your linear regression you can run these models hierarchically, once the random effects are in place
- you just test between model fits using a deviance test (like we did
with GLM)
anova(model.1, model.2)
Plot the final model correctly
- The method I used was to predict the data, but that works well if you have no covariates or a balanced design
- If you have covariates, its best to use the effects package just
like we did with linear regression
- Also you have to decide to plot both fixed + random or just the fixed effects
- Most people only plot the fixed effect, as they want to control for the random effects
- However, if someone asks you to plot the data and the model fits together, you will need to tell them it complicated as we saw last week.
- Below is how to plot fixed only
library(effects)
Final.Fixed<-effect(c("Social*TimeStep"), Model.6,
xlevels=list(TimeStep=seq(0,4,1)))
# You have to convert the output to a dataframe
Final.Fixed<-as.data.frame(Final.Fixed)
Final.Fixed.Plot <-ggplot(data = Final.Fixed, aes(x = TimeStep, y =fit, group=Social))+
coord_cartesian(xlim=c(0,4),ylim = c(0,.7))+
geom_line(aes(color=Social), size=2)+
geom_ribbon(aes(ymin=fit-se, ymax=fit+se,fill=Social),alpha=.2)+
xlab("Time")+
ylab("Happiness\nscore")+
scale_color_manual(values=c("blue", "red"))+
scale_fill_manual(values=c("blue", "red"))+
theme_bw()+
theme(text=element_text(face="bold", size=12),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.border = element_rect(fill = NA, colour = "NA"),
axis.line = element_line(size = 1, colour = "grey80"),
legend.title=element_blank(),
legend.position = c(.2, .92))
Final.Fixed.Plot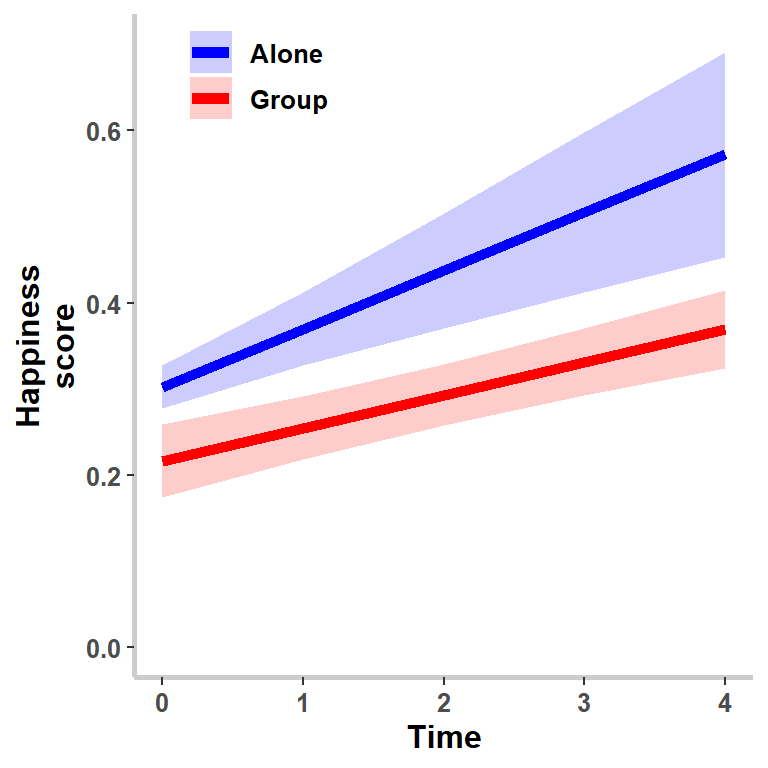
Problem with P-values
- What gives mixed-effects models their ability to handle complex designs (e.g., nested, crossed, nested & crossed, partially nested and crossed) is in part what does not allow them to calculate p-values
- Remember, \(t = \frac{M-\mu}{SE}\), where, \(SE = \sqrt\frac{\sigma^2}{n}\), \(df = n-1\)
- GLM uses standard error to determine significance: Required degrees
of freedom to correct z-distribution for “sampling error” to produce
\(t\) and \(F\) tables.
- But mixed models do not actually produce \(t\) or \(t^2=F\) values as they are not calculating the \(SE\) using the equation above, which uses observed - expected [mean square = \(\sigma^2 = \frac{SS}{N-1}\), where \(SS = (M-\mu)^2\)
- Instead, they estimate the \(SE\) using ML or REML function
- ML is a way of finding the value of one or more parameters in mixed
model for a given statistic which makes the known likelihood
distribution a maximum
- likelihood is “a hypothetical probability that an event that has already occurred would yield a specific outcome” (http://mathworld.wolfram.com/Likelihood.html)
- maximum is the largest value the function can produce
- We will iterate through parameters until we maximize our likelihood
- There are different ML (or just L) functions that can be used and they can apply to most distributions
- Problem 1: SE is not the one used in \(t\) and \(F\) (it does not use N)
- Problem 2: The estimate we get is not via OLS either, it’s via ML or REML (so what is the proper distribution to test against?)
- Problem 3: What is our \(DF\) even if we want to assume \(t\) and \(F\)?
Problem 3: DF Conceptual Issues
- Sample 500, 11the graders take the SAT from 3 schools partially nested in 2 economic districts
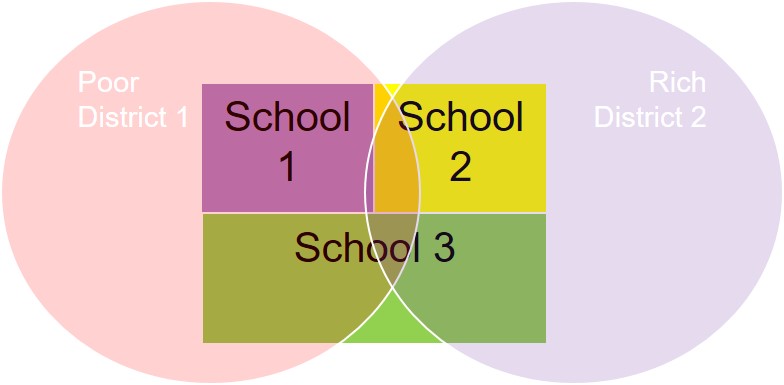
- Random sampling of 500 total from 3 schools [Note: school 3 is twice as large school 1 and 2]
- ANOVA Design: 1 factor: School OR district [they provide an unbalanced design so they can only be analyzed one at time]
- Assume homogeneity of variance of SAT score across schools and districts
- ANOVA can only ask 1 basic question: Are the means between the schools or districts different
ANOVA problem?
- Why is ANOVA bad here?
- School 1 is predominately poor vs School 2, which is rich, so school 1 has less funding, larger classrooms sizes, more social issues at home and in school, fewer teachers, etc.
- This could impact both mean test scores and variance of test scores
- Students from the poor district might have more diverse scores [high variance]
- Student from rich district might have more similar scores, but higher average scores [low variance]
- Poor students in the Rich school might also have changes in variance or mean test scores, which look very different from the poor or mixed school.
Mixed vs. ANOVA Solution
ANOVA Logic
- If we assume ANOVA that would mean we calculate mean/variance relative to their classification based on school and district [at the level we are examining only]
- In the case when all the variables are categorical, the DF “seems”
logical, in that the proper MSerror terms could be calculated. However,
in the mixed models, the random factors have been nested (kids in
schools in districts).
- So we cannot know how many of the people went into parsing the
variance for each level of the random error term.
- We could make assumptions, but some statisticians say over their dead bodies.
- ANOVA is assumed to be robust against many violations, but that’s mostly only true in well-controlled balanced designs.
- When ANOVA is stretched into the mixed model territory, it can result in unreasonable levels of type 1 error.
- So we cannot know how many of the people went into parsing the
variance for each level of the random error term.
Mixed Logic
- Fixed factors: School and District [student belongs to]
- SAT score MEANS could be different depending on the school a kid
goes to and what district they are from.
- Random Factors: District, School, [Student]
- SAT score VARIANCES could be different depending on the school a kid
goes to and what district they are from.
- So are the kids the DF, or the School or the district? What do with kids who are mismatched (poor but in richer schools or vice versa?)
- Random Slopes: The impact of SES could be different depending on the school a kid goes to and what district they are from,
- In the rich school, the SES of the student might not matter as much
as the poor or mixed school
- When we add random slopes, how many measurements of the effect of SES are we making - is it based on the number of students, schools or districts?
- Which level do we count the degrees of freedom for each fixed and random factor? Students, schools, or districts? How do we count DF for random factors?
Getting P-values
Path A: Don’t push your assumptions on me!
- Modeling Fitting testing
- Likelihood ratio test [chi-square distribution]
- D = 2 - ln (Likelihood of null model / Likelihood of alternative model]
- Add/Remove fixed factors and test to see if the model “fits the data better”
- Suggested by Bates and Bolker
- FAST and well-accepted [a bit anti-conservative some argue]
- To do this, you simply have to
anova(model.1, model.2)
- To do this, you simply have to
- Bootstrapping
- Non-parametric: Re-sampling method where you resample with
replacement from your own data
- Common method in modern stats: A much better method then assuming normality and t-distributions
- Example: You build your final model and you then take the subjects,
resample them with replacement, and refit your model
- You do this over and over again to build a distribution for each
parameter in your model
- You than calculate the 95th percentile and see if contains zero, if not you have a significant effect
- You do this over and over again to build a distribution for each
parameter in your model
- Semi-parametric: Adds noise to the Non-parametric (assumes your
measurements are randomly sampled from all possible measurements)
- So you sample from your data, add parametric noise, rinse and repeat like above
- Parametric: You assume your data follows a specific distribution, you use your model to estimate the parameters, and then you simulate the study based on those parameters to estimate the CI. You than calculate the 95th percentile and see if it contains zero.
- So far we can only do Semi-parametric & Parametric because of
the random effects
- However, Semi-parametric is not fully implemented yet
- VERY, VERY SLOW.
- This procedure can fail because your model is unstable (probably means your model is bad anyway)
- You can also bootstrap Model fit testing (95th percentile method)
# parametric
Model.Final.CI.boot <- confint(Model.6, method="boot",nsim=100,boot.type = c("perc"))
Model.Final.CI.boot## 2.5 % 97.5 %
## .sig01 0.01043755 0.08564062
## .sig02 -1.00000000 0.49578085
## .sig03 -0.56243568 0.95713822
## .sig04 -0.99609592 0.12063845
## .sig05 0.02587011 0.16581080
## .sig06 -0.99497337 -0.01520546
## .sig07 0.27728402 0.99418700
## .sig08 0.02181994 0.09209837
## .sig09 -0.99712452 -0.42267082
## .sig10 0.01789321 0.08145823
## .sigma 0.02395331 0.03927647
## (Intercept) 0.25820491 0.35155433
## SocialGroup -0.18889284 -0.01249034
## TimeStep 0.01166325 0.11785430
## SocialGroup:TimeStep -0.07574074 0.01093074Path B: Let’s hold hands, put our fingers in our ears, and assume!
- Assume z distributions to get p-values
- Very, very common approach
- If you number of observations is high, just assume DF -> inf [so
\(t > |2|\), is significant]
- This is possible because you assume your random effects have controlled for the random variations in the populations and your values good estimates of the population
- Simulation studies by Barr et al. show this to be a reasonable
assumption IF and ONLY OF random structure is MAXIMAL
- This is HOTLY debated by Bates
- Estimate degrees of freedom
- SAS/SPSS uses Satterthwaite approximations
- However, there are also Kenward-Roger approximations [see Westfall, Kenny, & Judd, 2014]
- Either is acceptable, but KR is recommended (but does not always work)
- Makes a number of assumptions, will mirror results of traditional
ANOVA fairly closely [as you would expect when you make similar
assumptions about DF]
- This method can also fail to work because your model is unstable/convergence problems
[Note: You have to refit the model with the lmerTest package]
library(lmerTest) #mixed model add-on package to
Model.Final<-lmer(HappyPercent ~Social*TimeStep
+(1+Social*TimeStep|Subject),
data=HappyData, REML=FALSE)
summary(Model.Final, ddf="Satterthwaite") ## SPSS/SAS method
Model.Final.REML<-lmer(HappyPercent ~Social*TimeStep
+(1+Social*TimeStep|Subject),
data=HappyData, REML=TRUE)
summary(Model.Final.REML,ddf = "Kenward-Roger") # Kenney et al suggested method## Linear mixed model fit by maximum likelihood . t-tests use Satterthwaite's
## method [lmerModLmerTest]
## Formula: HappyPercent ~ Social * TimeStep + (1 + Social * TimeStep | Subject)
## Data: HappyData
##
## AIC BIC logLik deviance df.resid
## -142.2 -110.8 86.1 -172.2 45
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.92979 -0.57518 0.06785 0.52187 1.63727
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Subject (Intercept) 0.003024 0.05499
## SocialGroup 0.011462 0.10706 -0.38
## TimeStep 0.004246 0.06516 0.46 -0.84
## SocialGroup:TimeStep 0.003061 0.05533 -0.79 0.84 -0.89
## Residual 0.001137 0.03372
## Number of obs: 60, groups: Subject, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 0.30250 0.02485 6.10702 12.172 1.64e-05 ***
## SocialGroup -0.08583 0.04624 6.05010 -1.856 0.1124
## TimeStep 0.06750 0.02696 6.00466 2.504 0.0462 *
## SocialGroup:TimeStep -0.02917 0.02341 6.02192 -1.246 0.2591
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) SclGrp TimStp
## SocialGroup -0.424
## TimeStep 0.357 -0.753
## SclGrp:TmSt -0.620 0.697 -0.875
## Linear mixed model fit by REML. t-tests use Kenward-Roger's method [
## lmerModLmerTest]
## Formula: HappyPercent ~ Social * TimeStep + (1 + Social * TimeStep | Subject)
## Data: HappyData
##
## REML criterion at convergence: -148.4
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.91088 -0.57147 0.06476 0.51788 1.60624
##
## Random effects:
## Groups Name Variance Std.Dev. Corr
## Subject (Intercept) 0.003666 0.06054
## SocialGroup 0.013791 0.11743 -0.38
## TimeStep 0.005104 0.07144 0.46 -0.84
## SocialGroup:TimeStep 0.003682 0.06068 -0.78 0.84 -0.89
## Residual 0.001165 0.03413
## Number of obs: 60, groups: Subject, 6
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 0.30250 0.02697 5.00000 11.216 9.84e-05 ***
## SocialGroup -0.08583 0.05031 5.00000 -1.706 0.1487
## TimeStep 0.06750 0.02950 5.00000 2.288 0.0708 .
## SocialGroup:TimeStep -0.02917 0.02554 5.00000 -1.142 0.3052
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr) SclGrp TimStp
## SocialGroup -0.415
## TimeStep 0.367 -0.764
## SclGrp:TmSt -0.641 0.715 -0.876
## optimizer (nloptwrap) convergence code: 0 (OK)
## boundary (singular) fit: see help('isSingular')Path C: Go Bayesian
- There use to be a way to get pvalues based on Markov-chain
Monte-Carlo methods (MCMC)
- Currently does not work for lme4 package we are using
- You have to refit the model as Bayesian using
rstanarmand get CIs (see Gelman & Hill textbook)
Practical solution
- Practically, when you add factors in stepwise and model fit shows a significant improvement (Path 1A) you will see the new factors has a \(t > |2|\). (Path 2A)
- That does not always agree with bootstrapping (Path 1B) or
ANOVA-like degrees of freedom (Path 2B)
- This is because LME4 package we are using does not allow us to
control for the heterogeneous variance problem. The older package LME
will allow you to control for it.
- Note LME uses Satterthwaite approximations and will always give you DF and pvalues
- Also, there could be other problems with your assumptions that bootstrapping is picking up on the other paths will not pick up
- This is because LME4 package we are using does not allow us to
control for the heterogeneous variance problem. The older package LME
will allow you to control for it.
- Recommendation: Based on current trends:
- Always do Path 1A to say the model is better
- To test the parameters, add Path 1B, Path 2A or 2B.
- I usually pick 1B or 2A
- But some fields might demand DF, so you have to do 2B
Mixed to ANOVA
- If you wanted to report the main effects and interactions, instead of slopes, you might convert your mixed model into an ANOVA
- But remember, your slopes of time revert to being factors and not continuous variables
anova(Model.Final.REML,ddf = "Kenward-Roger") ## Type III Analysis of Variance Table with Kenward-Roger's method
## Sum Sq Mean Sq NumDF DenDF F value Pr(>F)
## Social 0.0033897 0.0033897 1 5 2.9104 0.14873
## TimeStep 0.0087322 0.0087322 1 5 7.4975 0.04088 *
## Social:TimeStep 0.0015187 0.0015187 1 5 1.3039 0.30522
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1LS0tDQp0aXRsZTogJ0xpbmVhciBNaXhlZCBNb2RlbHMnDQpvdXRwdXQ6DQogIGh0bWxfZG9jdW1lbnQ6DQogICAgY29kZV9kb3dubG9hZDogeWVzDQogICAgZm9udHNpemU6IDhwdA0KICAgIGhpZ2hsaWdodDogdGV4dG1hdGUNCiAgICBudW1iZXJfc2VjdGlvbnM6IG5vDQogICAgdGhlbWU6IGZsYXRseQ0KICAgIHRvYzogeWVzDQogICAgdG9jX2Zsb2F0Og0KICAgICAgY29sbGFwc2VkOiBubw0KLS0tDQoNCmBgYHtyIHNldHVwLCBpbmNsdWRlPUZBTFNFfQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGVjaG8gPSBUUlVFKQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KG1lc3NhZ2UgPSBGQUxTRSkNCmtuaXRyOjpvcHRzX2NodW5rJHNldCh3YXJuaW5nID0gIEZBTFNFKQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGZpZy53aWR0aD01LjI1KQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGZpZy5oZWlnaHQ9NS4wKQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGZpZy5hbGlnbj0nY2VudGVyJykgI1NldCBkZWZhdWx0IGZpZ3VyZQ0Ka25pdHI6Om9wdHNfY2h1bmskc2V0KGZpZy5zaG93ID0gImhvbGQiKSAjU2V0IGRlZmF1bHQgZmlndXJlDQprbml0cjo6b3B0c19jaHVuayRzZXQocmVzdWx0cyA9ICJob2xkIikgDQpgYGANCg0KYGBge3IsIGVjaG89RkFMU0UsIHdhcm5pbmc9RkFMU0V9DQpzZXR3ZCgiQzovVXNlcnMvYXBkMjEvRHJvcGJveC9BbGV4RmlsZXMvV2Vic2l0ZSBEZWMvTWl4ZWQiKQ0KYGBgDQoNCiMgTWl4ZWQgTW9kZWxzDQotIE11bHRpcGxlIHJlZ3Jlc3Npb25zIG9ubHkgaGF2ZSBmaXhlZC1lZmZlY3RzIFtjb250aW51b3VzXSBvciBmaXhlZC1mYWN0b3JzIFtncm91cHNdOiB2YXJpYWJsZXMgb2YgaW50ZXJlc3QgKG9mdGVuIHlvdXIgbWFuaXB1bGF0aW9uKQ0KLSBUaGUgb25seSByYW5kb20gZmFjdG9yIGFzc3VtZWQgaXMgeW91ciBzdWJqZWN0J3MgcmVzcG9uc2UNCiAgICAtIFdoYXQgaWYgeW91IGhhdmUgb3RoZXIgZWZmZWN0cyBvciBmYWN0b3JzIHRoYXQgbWlnaHQgYWRkIHJhbmRvbSB2YXJpYXRpb24/IA0KLSBSYW5kb20tZWZmZWN0cy9mYWN0b3JzOiBMZXZlbHMgcmFuZG9tbHkgc2FtcGxlZCBmcm9tIGEgbXVjaCBsYXJnZXIgcG9wdWxhdGlvbjogU29tZXRoaW5nIHlvdSB3YW50IHRvIGdlbmVyYWxpemUgYWNyb3NzOiBTdWJqZWN0cywgV29yZHMsIFBpY3R1cmVzLCBldGMNCg0KIyMgVHlwZSBvZiBNaXhlZCBNb2RlbHMNCi0gV2Ugd2lsbCBleHBsb3JlIGNyb3NzZWQgZGVzaWducw0KDQojIyMgTmVzdGVkIGRlc2lnbnMNCi0gUHJvYmxlbTogQ2x1c3RlcmluZyBtZWFucyBlYWNoIHN0dWRlbnQncyBzY29yZXMgd2l0aGluIGVhY2ggY2xhc3Nyb29tIG1pZ2h0IGJlIGNvcnJlbGF0ZWQgYmVjYXVzZSB0aGV5IGFsbCBoYXZlIHRoZSBzYW1lIHRlYWNoZXIgKGZvciBleGFtcGxlKQ0KICAgIC0gTXVsdGlsZXZlbC9IaWVyYXJjaGljYWwgZGVzaWduczogU3R1ZGVudHMgbmVzdGVkIGluIGNsYXNzcm9vbXMgW0NsdXN0ZXJlZCBkYXRhXQ0KDQojIyMgQ3Jvc3NlZCBkZXNpZ25zDQotIFByb2JsZW06IEVhY2ggcGVyc29uJ3MgcmVzcG9uc2UgaXMgZ29pbmcgdG8gaW50ZXItY29ycmVsYXRlZCB3aXRoIHRoZWlyIG90aGVyIHJlc3BvbnNlcyANCiAgICAtIFJlcGVhdGVkIG1lYXN1cmVzOiBldmVyeW9uZSBkb2VzIGFsbCB0aGUgY29uZGl0aW9ucw0KICAgIC0gTG9uZ2l0dWRpbmFsIGRhdGE6IFBlb3BsZSBhcmUgdHJhY2tlZCBvdmVyIHRpbWUNCiAgICAgICAgLSBHcm93dGggQ3VydmUgTW9kZWxzOiBGaXR0aW5nIGZ1bmN0aW9ucyAobGlrZSBwb2x5bm9taWFscykgdG8gYmVoYXZpb3Igb3ZlciB0aW1lIA0KDQojIyMgQ3Jvc3NlZCAmIE5lc3RlZCBkZXNpZ25zDQotIE5vdyBlYWNoIHBlcnNvbidzIHJlc3BvbnNlIGlzIGdvaW5nIHRvIGludGVyLWNvcnJlbGF0ZWQgd2l0aCB0aGVpciBvdGhlciByZXNwb25zZXMsIGJ1dCB0aGF0IGNvcnJlbGF0aW9uIG1pZ2h0IGRpZmZlciBieSB3aGljaCBncm91cCB0aGV5IGJlbG9uZyB0b28gDQogICAgLSBMb25naXR1ZGluYWwgTXVsdGlsZXZlbCBEZXNpZ25zOiBTdHVkZW50cyBuZXN0ZWQgaW4gY2xhc3Nyb29tcyBtZWFzdXJlZCBvdmVyIG1hbnkgbW9udGhzDQogICAgLSBQYXJ0aWFsbHkgTmVzdGVkIGRlc2lnbjogRGlmZmVyZW50IGdyb3VwcyBhcmUgbWVhc3VyZXMgb3ZlciB0aW1lDQogDQojIyMjIEludGVyLUNvcnJlbGF0aW9ucyANCi0gQWxsIHRoZXNlIGNvcnJlbGF0aW9ucyBpbmZsYXRlIHlvdXIgdHlwZSBJIGVycm9yIGlmIHlvdSBkb27igJl0IHRyZWF0IHRoZSBkYXRhIGNvcnJlY3RseQ0KDQojIFByYWN0aWNlIGRhdGEgdG8gbWFrZSBzZW5zZSBvZiByYW5kb20gZWZmZWN0cyANCi0gSHlwb3RoZXRpY2FsIEV4cGVyaW1lbnQsICpuKiA9IDYNCi0gRFY6ICUgb2YgaG93IGhhcHB5IHRoZXkgYXJlIA0KLSBJVjE6IFRpbWUgb2YgbWVhc3VyZW1lbnQ6IDUgdGltZSB3aW5kb3dzDQotIElWMjogU29jaWFsIFNldHRpbmc6IEFsb25lIHZzIFdpdGggYSBncm91cA0KDQojIyBBcyAyeDUgUk0gQU5PVkENCi0gVHJlYXRzIFRpbWUtU3RlcHMgYXMgYSBmYWN0b3IgDQotIEFyZSB0aGVyZSBhbnkgZGlmZmVyZW5jZXMgYmV0d2VlbiBhbnkgdGltZS1zdGVwcz8NCi0gTm90IHNsb3BlcyAocHJlZGljdGFibGUgY2hhbmdlcyBpbiB0aW1lKQ0KLSBUcmVhdHMgU29jaWFsIGFzIGEgZmFjdG9yDQotIElzIHRoZXJlIGEgZGlmZmVyZW5jZSBiZXR3ZWVuIEFsb25lIGFuZCBXaXRoIEdyb3VwDQotIFF1ZXN0aW9uczogSXMgdGhlcmUgYW4gZWZmZWN0IG9mIHRpbWUgYW5kIFNvY2lhbD8gDQoNCmBgYHtyfQ0KbGlicmFyeShsbWU0KSAgICAgI21peGVkIG1vZGVsIHBhY2thZ2UgYnkgRG91Z2xhcyBCYXRlcw0KbGlicmFyeShhZmV4KSAgICAgI2Vhc3kgQU5PVkEgcGFja2FnZSANCmxpYnJhcnkoZ2dwbG90MikgICNHR3Bsb3QgcGFja2FnZSBmb3IgdmlzdWFsaXppbmcgZGF0YQ0Kc291cmNlKCJIZWxwZXJGdW5jdGlvbnMuUiIpICMgc29tZSBjdXN0b20gZnVuY3Rpb25zDQojIyNSZWFkIGluIERhdGEgZmlsZQ0KSGFwcHlEYXRhIDwtIHJlYWQuY3N2KCJNaXhlZC9IYXBweVN0dWR5LmNzdiIsIGhlYWRlcj1UKQ0KIyMjIExhYmVsIHZhcmlhYmxlcw0KSGFwcHlEYXRhJFNvY2lhbCA8LSBmYWN0b3IoSGFwcHlEYXRhJFNvY2lhbER1bW15LA0KICAgICAgICAgICAgICAgICAgICAgICAgbGV2ZWxzID0gYygwLDEpLA0KICAgICAgICAgICAgICAgICAgICAgICAgbGFiZWxzID0gYygiQWxvbmUiLCAiR3JvdXAiKSkNCkhhcHB5RGF0YSRTdWJqZWN0PC1hcy5mYWN0b3IoSGFwcHlEYXRhJFN1YmplY3QpDQpgYGANCg0KLSBMZXQncyBwbG90IGVhY2ggcGVyc29uJ3MgZGF0YSAoc3BhZ2hldHRpIHBsb3QpDQoNCmBgYHtyfQ0KdGhlbWVfc2V0KHRoZW1lX2J3KGJhc2Vfc2l6ZSA9IDEyLCBiYXNlX2ZhbWlseSA9ICIiKSkgDQoNCnBhYiA8LWdncGxvdChkYXRhID0gSGFwcHlEYXRhLCBhZXMoeCA9IFRpbWVTdGVwLCB5PUhhcHB5UGVyY2VudCwgZ3JvdXA9U3ViamVjdCkpKw0KICBmYWNldF9ncmlkKCB+IFNvY2lhbCwgbGFiZWxsZXI9bGFiZWxfYm90aCkrDQogICMgIGNvb3JkX2NhcnRlc2lhbih5bGltID0gYyguMDMsLjA3NCkpKyANCiAgZ2VvbV9saW5lKGFlcyhjb2xvcj1TdWJqZWN0KSkrDQogIHhsYWIoIlRpbWUgU3RlcCIpK3lsYWIoIkhhcHBpbmVzcyIpDQpwYWINCmBgYA0KDQotIExldCdzIHBsb3QgZWFjaCBwZXJzb24ncyBkYXRhIHdpdGggdGhlIG1lYW5zIHBsb3R0ZWQNCg0KYGBge3J9DQojI2N1c3RvbSBmdW5jdGlvbiB0byBnZW5lcmF0ZSBtZWFucyBhbmQgU0UgZm9ybSBhbnkgbG9uZyBmb3JtYXQgZGF0YXNldC4gDQpIYXBweURhdGFQbG90Mjwtc3VtbWFyeVNFd2l0aGluKEhhcHB5RGF0YSxtZWFzdXJldmFyPSJIYXBweVBlcmNlbnQiLCANCiAgICAgICAgICAgICAgICAgICAgICAgICAgICAgICB3aXRoaW52YXJzPWMoIlNvY2lhbCIsIlRpbWVTdGVwIiksDQogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgaWR2YXI9IlN1YmplY3QiLCBuYS5ybT1GQUxTRSwgY29uZi5pbnRlcnZhbD0uOTUpDQpwYWIyIDwtZ2dwbG90KCkrDQogIGdlb21fbGluZShkYXRhID0gSGFwcHlEYXRhLCBhZXMoeCA9IGFzLmZhY3RvcihUaW1lU3RlcCksIHkgPUhhcHB5UGVyY2VudCwgZ3JvdXA9U3ViamVjdCwgY29sb3I9U3ViamVjdCkpKw0KICBmYWNldF9ncmlkKC4gfiBTb2NpYWwsIGxhYmVsbGVyPWxhYmVsX2JvdGgpKw0KICAjICBjb29yZF9jYXJ0ZXNpYW4oeWxpbSA9IGMoLjAzLC4wNzQpKSsgDQogIGdlb21fcG9pbnQoZGF0YSA9IEhhcHB5RGF0YVBsb3QyLCBhZXMoeCA9IGFzLmZhY3RvcihUaW1lU3RlcCksIHkgPUhhcHB5UGVyY2VudCwgZ3JvdXA9U29jaWFsKSkrDQogIGdlb21fZXJyb3JiYXIoZGF0YSA9IEhhcHB5RGF0YVBsb3QyLGFlcyh4ID0gYXMuZmFjdG9yKFRpbWVTdGVwKSwgeSA9SGFwcHlQZXJjZW50LCBncm91cD1Tb2NpYWwsIHltaW49SGFwcHlQZXJjZW50LXNlLCB5bWF4PUhhcHB5UGVyY2VudCtzZSksY29sb3VyPSIjNkU2RTZFIixzaXplPS4yNSwgd2lkdGg9LjI1KSsNCiAgeGxhYigiVGltZSBTdGVwIikreWxhYigiSGFwcGluZXNzIikNCnBhYjINCmBgYA0KDQotIExldCdzIGV4YW1pbmUgYW4gUk0gQU5PVkEgcmVzdWx0cyBvZiB0aGlzIGRhdGENCi0gUmVtZW1iZXIgdGltZSBpcyB0cmVhdGVkIGxpa2UgYSBmYWN0b3IgKG5vdCBhIHNsb3BlKQ0KLSBbTm90ZTogSSByYW4gdGhlIEFOT1ZBIGxpa2UgYSBHTE0ganVzdCBzbyB3ZSBjYW4gZXh0cmFjdCBhbiBvdmVyYWxsICRSXjIkIGFuZCBnZXQgYSBmaXR0ZWQgcmVzdWx0IGZvciBlYWNoIHN1YmplY3RdDQoNCmBgYHtyfQ0KIyMjIyMjI0Fub3ZhICh1c2luZyB0eXBlIDMgc3VtIG9mIHNxdWFyZXMgc2FtZSBhcyBkZWZhdWx0IGluIFNQU1MvU0FTKQ0KQW5vdmEuTW9kZWwxIDwtYW92X2NhcihIYXBweVBlcmNlbnQgfiBTb2NpYWwqVGltZVN0ZXAgKyBFcnJvcihTdWJqZWN0LyhTb2NpYWwqVGltZVN0ZXApKSwgDQogICAgICAgICAgICAgICAgICAgICAgICAgICAgICAgZGF0YSA9IEhhcHB5RGF0YSwgYW5vdmFfdGFibGUgPSBsaXN0KGNvcnJlY3Rpb24gPSAibm9uZSIsIE1TRSA9IEZBTFNFKSkNCkFub3ZhLk1vZGVsMQ0KIyMjIyMjIEdlbmVyYWwgTGluZWFyIE1vZGVsIChzYW1lIGFzIEFOT1ZBLCBidXQgdXNlcyB0eXBlIDEgc3VtIG9mIHNxdWFyZXMpIA0KR0xNLm1vZGVsPC1nbG0oSGFwcHlQZXJjZW50IH4gU29jaWFsKlRpbWVTdGVwLCBkYXRhPUhhcHB5RGF0YSkNCiNmaXQgZGF0YQ0KSGFwcHlEYXRhJEdMTWZpdHRlZDwtZml0dGVkKEdMTS5tb2RlbCkNCiNtYW51YWxseSBleHRyYWN0IFIyIHRvIGNvbXBhcmUgdG8gbWl4ZWQgbW9kZWxzDQpzdW1tYXJ5KGxtKEhhcHB5UGVyY2VudCB+IEdMTWZpdHRlZCwgZGF0YT1IYXBweURhdGEpKSRyLnNxdWFyZWQNCmBgYA0KDQotIFdlIGNhbiBmaXQgdGhlIEdMTS9BTk9WQSBlc3RpbWF0ZSBmb3IgZXZlcnkgc2luZ2xlIHN1YmplY3QNCi0gSG93IGlzIG91ciBBTk9WQSBkb2luZyBpbiBwcmVkaWN0aW5nIGVhY2ggc3ViamVjdD8gDQotIEFOT1ZBIGlzIG5vdCBwcmVkaWN0aW5nIHN1YmplY3QgbGV2ZWw7IGl0IGlzIHRlc3RpbmcvcHJlZGljdGluZyBhdCB0aGUgYXZlcmFnZSBsZXZlbCBvZiB0aGUgZGF0YQ0KLSBIb3dldmVyLCBpZiB3ZSBoYXZlIGxvbmdpdHVkaW5hbC1saWtlIGRhdGEgKGxpa2UgaW4gdGhpcyBzdHVkeSkgd2h5IG5vdCBtYWtlIHByZWRpY3Rpb25zIGF0IHRoZSBzdWJqZWN0LWxldmVsPyANCg0KYGBge3J9DQpGaXR0ZWRHbG1QbG90MSA8LWdncGxvdCgpKw0KICBmYWNldF9ncmlkKFN1YmplY3QgfiBTb2NpYWwsIGxhYmVsbGVyPWxhYmVsX2JvdGgpKw0KICBnZW9tX2xpbmUoZGF0YSA9IEhhcHB5RGF0YSwgYWVzKHggPSBUaW1lU3RlcCwgeSA9R0xNZml0dGVkKSkrDQogIGdlb21fcG9pbnQoZGF0YSA9IEhhcHB5RGF0YSwgYWVzKHggPSBUaW1lU3RlcCwgeSA9SGFwcHlQZXJjZW50LCBncm91cD1TdWJqZWN0LGNvbG91ciA9IFN1YmplY3QpLHNpemU9MykrDQogIHhsYWIoIlRpbWUgU3RlcCIpK3lsYWIoIkhhcHBpbmVzcyIpDQpGaXR0ZWRHbG1QbG90MQ0KYGBgDQoNCiMgUmFuZG9tIEVmZmVjdCBNb2RlbGluZzogRml0dGluZyBhdCBkaWZmZXJlbnQgbGV2ZWxzDQotIExpbmVhciByZWdyZXNzaW9uIGFzc3VtZXMgb25lIG1lYXN1cmVtZW50IHBlciBzdWJqZWN0LCBidXQgd2hhdCBpcyB5b3UgaGF2ZSBtdWx0aXBsZSBtZWFzdXJlbWVudHMgcGVyIHN1YmplY3Q/IA0KLSBJZiB3ZSBoYXZlIGxvbmdpdHVkaW5hbCBkYXRhIHBlciBzdWJqZWN0IHdlIGNvdWxkIGVzdGltYXRlIGEgc2xvcGUgcGVyIHN1YmplY3QhDQotIFdlIGNvdWxkIHRoZW4gZXh0cmFjdCB0aGUgc2xvcGVzIGVzdGltYXRlcyBwZXIgc3ViamVjdCBbYW5kIGRvIHN0YXRpc3RpY3Mgb24gdGhlIHNsb3BlcyBwZXIgc3ViamVjdF0NCi0gQnV0IHdlIGxvc2UgdGhlIHZhcmlhbmNlcyBhcm91bmQgdGhvc2Ugc2xvcGVzISBTdWNoIGFzIGJlbG93Lg0KDQpgYGB7cn0NCkZpdHRlZGxtUGxvdCA8LWdncGxvdChkYXRhID0gSGFwcHlEYXRhLCBhZXMoeCA9IFRpbWVTdGVwLCB5ID1IYXBweVBlcmNlbnQsIGdyb3VwPVN1YmplY3QpKSsNCiAgZmFjZXRfZ3JpZChTdWJqZWN0IH4gU29jaWFsLCBsYWJlbGxlcj1sYWJlbF9ib3RoKSsNCiAgZ2VvbV9wb2ludChhZXMoY29sb3VyID0gU3ViamVjdCksIHNpemU9MykrDQogIGdlb21fc21vb3RoKG1ldGhvZCA9ICJsbSIsc2U9RkFMU0UsIGNvbG9yID0iYmxhY2siLCBzaXplPS41KSArDQogIHhsYWIoIlRpbWUgU3RlcCIpK3lsYWIoIkhhcHBpbmVzcyIpDQpGaXR0ZWRsbVBsb3QNCmBgYA0KDQojIyBSYW5kb20gaW50ZXJjZXB0cw0KLSBTbyB3ZSBuZWVkIHRvIGdldCBhIHJlZ3Jlc3Npb24gbW9kZWwgdG8gdHJ5IHRvIGZpdCBhdCB0aGUgc3ViamVjdCBsZXZlbA0KICAgIC0gYCgxfFN1YmplY3QpYCBtZWFucyBlYWNoIHN1YmplY3QgY2FuIGhhdmUgdGhlaXIgb3duIGludGVyY2VwdA0KICAgIC0gYFJFTUw9RkFMU0VgIG1lYW5zIGZpdCB0aGUgd2l0aCBtYXhpbXVtIGxpa2VsaWhvb2QgW2xpa2Ugd2UgZGlkIHdpdGggR0xNXQ0KLSBZb3UgY2FuIHNlZSB0aGUgcmFuZG9tLCBmaXhlZCB0ZXJtcywgYW5kIGNvcnJlbGF0aW9ucyBiZXR3ZWVuIHRoZSBmaXhlZCB0ZXJtcyANCg0KYGBge3J9DQpNb2RlbC4xPC1sbWVyKEhhcHB5UGVyY2VudCB+U29jaWFsKlRpbWVTdGVwDQogICAgICAgICAgICAgICAgICAgKygxfFN1YmplY3QpLCAgDQogICAgICAgICAgICAgICAgICAgZGF0YT1IYXBweURhdGEsIFJFTUw9RkFMU0UpDQpzdW1tYXJ5KE1vZGVsLjEsIGNvcnJlbGF0aW9ucz1GQUxTRSkNCmBgYA0KDQotIE5leHQsIHdlIGV4YW1pbmUgdGhlIGludGVyY2VwdHMgZm9yIGVhY2ggcGVyc29uDQotIFRoZSB2YXIgYW5kIHNkIG9mIHRoZXNlIHZhbHVlcyBhcmUgd2hhdCB3YXMgc2VlbiBpbiB0aGUgdGFibGUgYWJvdmUNCg0KYGBge3J9DQpyYW5lZihNb2RlbC4xKQ0KYGBgDQoNCi0gV2UgY2FuIGV4YW1pbmUgYW4gJFJeMiQgZm9yIHRoZSBtb2RlbHMsIGJ1dCB3ZSBoYXZlIGEgcHJvYmxlbQ0KLSBJcyB0aGUgJFJeMiQgY29taW5nIGZyb20gdGhlIGZpeGVkIG9yIHJhbmRvbSBlZmZlY3Q/IFdlIGNhbiBwYXJzZSB0aGF0Og0KLSBUaGUgbWFyZ2luYWwgaXMgdGhlICRSXjIkIGZvciB0aGUgZml4ZWQgZWZmZWN0cw0KLSBUaGUgY29uZGl0aW9uYWwgJFJeMiQgaW5jbHVkZXMgcmFuZG9tICsgZml4ZWQgZWZmZWN0cw0KLSBUaGVyZSBpcyBubyBzdGFuZGFyZCBhcyB0byB3aGljaCB0byByZXBvcnQgJFJeMiQgYW5kIG1vc3QgcGVvcGxlIG5ldmVyIHJlcG9ydCB0aGVzZSBhdCBhbGwgYXMgaWYgdGhlIHJhbmRvbSBlZmZlY3RzIGFyZSBjb21wbGV4IChuZXN0ZWQsIG9yIGNyb3NzZWQpIHRoZSBtZWFuaW5nIG9mIHRoZW0gY2hhbmdlcw0KDQpgYGB7cn0NCmxpYnJhcnkocGVyZm9ybWFuY2UpDQpyMl9uYWthZ2F3YShNb2RlbC4xKQ0KYGBgDQoNCi0gTGV0J3MgcGxvdCB0aGUgbW9kZWwgZml0DQoNCmBgYHtyfQ0KSGFwcHlEYXRhJE1vZGVsLjEuZml0dGVkPC1wcmVkaWN0KE1vZGVsLjEpDQpGaXR0ZWRsbVBsb3QxIDwtZ2dwbG90KCkrDQogIGZhY2V0X2dyaWQoU3ViamVjdCB+IFNvY2lhbCwgbGFiZWxsZXI9bGFiZWxfYm90aCkrDQogIGdlb21fbGluZShkYXRhID0gSGFwcHlEYXRhLCBhZXMoeCA9IFRpbWVTdGVwLCB5ID1Nb2RlbC4xLmZpdHRlZCkpKw0KICBnZW9tX3BvaW50KGRhdGEgPSBIYXBweURhdGEsIGFlcyh4ID0gVGltZVN0ZXAsIHkgPUhhcHB5UGVyY2VudCwgZ3JvdXA9U3ViamVjdCxjb2xvdXIgPSBTdWJqZWN0KSwgc2l6ZT0zKSsNCiAgeGxhYigiVGltZSBTdGVwIikreWxhYigiSGFwcGluZXNzIikNCkZpdHRlZGxtUGxvdDENCmBgYA0KDQojIyBSYW5kb20gaW50ZXJjZXB0IGFuZCBzbG9wZXMgZm9yIHRoZSBzb2NpYWwgY29uZGl0aW9uIA0KLSBNb2RlbCAyIHRyZWF0cyB0aGF0IFNvY2lhbCBjb25kaXRpb24gYXMgZnJlZSB0byB2YXJ5IGJldHdlZW4gU3ViamVjdHMsIGJ1dCBhY2NvdW50cyBmb3IgdGhlIGNvcnJlbGF0aW9uIHdpdGhpbiBTdWJqZWN0cyBiZXR3ZWVuIHRoZSBTb2NpYWwgY29uZGl0aW9uKQ0KICAgIC0gYCgxK1NvY2lhbHxTdWJqZWN0KWAgbWVhbnMgZWFjaCBzdWJqZWN0IGNhbiBoYXZlIHRoZWlyIGludGVyY2VwdCBhbmQgc29jaWFsIGNvbmRpdGlvbiBjYW4gdmFyeSBhcyBhIGZ1bmN0aW9uIG9mIHRoZSBzdWJqZWN0DQotIFRoZSBjb3JyZWxhdGlvbnMgb2YgdGhlIHJhbmRvbSB0ZXJtcyBhcmUgdGhlIGNvcnJlbGF0aW9ucyBvZiBlYWNoIHN1YmplY3Rz4oCZIGludGVyY2VwdCBhbmQgc2xvcGUgb2Ygc29jaWFsIGNvbmRpdGlvbg0KDQpgYGB7cn0NCk1vZGVsLjI8LWxtZXIoSGFwcHlQZXJjZW50IH5Tb2NpYWwqVGltZVN0ZXANCiAgICAgICAgICAgICAgICAgICAgICAgKygxK1NvY2lhbHxTdWJqZWN0KSwgIA0KICAgICAgICAgICAgICAgICAgICAgICBkYXRhPUhhcHB5RGF0YSwgUkVNTD1GQUxTRSkNCnN1bW1hcnkoTW9kZWwuMiwgY29ycmVsYXRpb25zPUZBTFNFKQ0KcmFuZWYoTW9kZWwuMikNCmBgYA0KDQotIFRoZSAkUl4yJCBmb3IgZml4ZWQgYW5kIHJhbmRvbQ0KDQpgYGB7cn0NCnIyX25ha2FnYXdhKE1vZGVsLjIpDQpgYGANCg0KLSBQbG90IHRoZSBtb2RlbCByZXN1bHRzDQoNCmBgYHtyfQ0KSGFwcHlEYXRhJE1vZGVsLjIuZml0dGVkPC1wcmVkaWN0KE1vZGVsLjIpDQpGaXR0ZWRsbVBsb3QyIDwtZ2dwbG90KCkrDQogIGZhY2V0X2dyaWQoU3ViamVjdCB+IFNvY2lhbCwgbGFiZWxsZXI9bGFiZWxfYm90aCkrDQogIGdlb21fbGluZShkYXRhID0gSGFwcHlEYXRhLCBhZXMoeCA9IFRpbWVTdGVwLCB5PU1vZGVsLjIuZml0dGVkKSkrDQogIGdlb21fcG9pbnQoZGF0YSA9IEhhcHB5RGF0YSwgYWVzKHggPSBUaW1lU3RlcCwgeSA9SGFwcHlQZXJjZW50LCBncm91cD1TdWJqZWN0LGNvbG91ciA9IFN1YmplY3QpLCBzaXplPTMpKw0KICAjICBjb29yZF9jYXJ0ZXNpYW4oeWxpbSA9IGMoLjAzLC4wNzQpKSsgDQogIHhsYWIoIlRpbWUgU3RlcCIpK3lsYWIoIkhhcHBpbmVzcyIpDQpGaXR0ZWRsbVBsb3QyDQpgYGANCg0KDQojIyBSYW5kb20gaW50ZXJjZXB0cyBhbmQgc2xvcGVzIGZvciB0aW1lICANCi0gTW9kZWwgMyB0cmVhdHMgdGhhdCB0aW1lc3RlcHMgYXMgZnJlZSB0byB2YXJ5IGJldHdlZW4gU3ViamVjdHMsIGJ1dCBhY2NvdW50cyBmb3IgdGhlIGNvcnJlbGF0aW9uIHdpdGhpbiBTdWJqZWN0cyBhY3Jvc3MgdGltZQ0KICAgIC0gYCgxK1RpbWVTdGVwfFN1YmplY3QpYCBtZWFucyBlYWNoIHN1YmplY3QgY2FuIGhhdmUgdGhlaXIgaW50ZXJjZXB0IGFuZCB0aW1lIHNsb3BlIGNhbiB2YXJ5IGFzIGEgZnVuY3Rpb24gb2YgdGhlIHN1YmplY3QNCi0gVGhlIGNvcnJlbGF0aW9ucyBvZiB0aGUgcmFuZG9tIHRlcm1zIGFyZSB0aGUgY29ycmVsYXRpb25zIG9mIGVhY2ggc3ViamVjdHPigJkgaW50ZXJjZXB0IGFuZCBzbG9wZSBvZiB0aW1lIA0KDQpgYGB7cn0NCk1vZGVsLjM8LWxtZXIoSGFwcHlQZXJjZW50IH5Tb2NpYWwqVGltZVN0ZXANCiAgICAgICAgICAgICAgICAgICAgICAgKygxK1RpbWVTdGVwfFN1YmplY3QpLCAgDQogICAgICAgICAgICAgICAgICAgICAgIGRhdGE9SGFwcHlEYXRhLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShNb2RlbC4zLCBjb3JyZWxhdGlvbnM9RkFMU0UpDQpyYW5lZihNb2RlbC4zKQ0KYGBgDQoNCi0gVGhlICRSXjIkIGZvciBmaXhlZCBhbmQgcmFuZG9tDQoNCmBgYHtyfQ0KcjJfbmFrYWdhd2EoTW9kZWwuMykNCmBgYA0KDQotIFBsb3QgdGhlIG1vZGVsIHJlc3VsdHMNCg0KYGBge3J9DQpIYXBweURhdGEkTW9kZWwuMy5maXR0ZWQ8LXByZWRpY3QoTW9kZWwuMykNCkZpdHRlZGxtUGxvdDMgPC1nZ3Bsb3QoKSsNCiAgZmFjZXRfZ3JpZChTdWJqZWN0IH4gU29jaWFsLCBsYWJlbGxlcj1sYWJlbF9ib3RoKSsNCiAgZ2VvbV9saW5lKGRhdGEgPSBIYXBweURhdGEsIGFlcyh4ID0gVGltZVN0ZXAsIHkgPU1vZGVsLjMuZml0dGVkKSkrDQogIGdlb21fcG9pbnQoZGF0YSA9IEhhcHB5RGF0YSwgYWVzKHggPSBUaW1lU3RlcCwgeSA9SGFwcHlQZXJjZW50LCBncm91cD1TdWJqZWN0LGNvbG91ciA9IFN1YmplY3QpLCBzaXplPTMpKw0KICAjICBjb29yZF9jYXJ0ZXNpYW4oeWxpbSA9IGMoLjAzLC4wNzQpKSsgDQogIHhsYWIoIlRpbWUgU3RlcCIpK3lsYWIoIkhhcHBpbmVzcyIpDQpGaXR0ZWRsbVBsb3QzDQpgYGANCg0KDQojIyBSYW5kb20gaW50ZXJjZXB0cyBhbmQgc2xvcGVzIGZvciB0aW1lIGFuZCBzb2NpYWwgKGJ1dCBpbmRlcGVuZGVudCkgIA0KLSBNb2RlbCA0IHRyZWF0cyB0aGF0IHRpbWVzdGVwcyBhbmQgU29jaWFsIGFzIGZyZWUgdG8gdmFyeSBiZXR3ZWVuIFN1YmplY3RzIGJ1dCBhY2NvdW50cyBmb3IgdGhlIGNvcnJlbGF0aW9uIHdpdGhpbiBTdWJqZWN0cyBhY3Jvc3MgdGltZXMgYW5kIHNvY2lhbA0KICAgIC0gYCgxK1NvY2lhbHxTdWJqZWN0KSsoMCtUaW1lU3RlcHxTdWJqZWN0KWAgbWVhbnMgZWFjaCBzdWJqZWN0IGNhbiBoYXZlIHRoZWlyIGludGVyY2VwdCBhbmQgY2FuIGhhdmUgdGhlaXIgc2xvcGUgb2Ygc29jaWFsIGNvbmRpdGlvbg0KLSBBbHNvLCB0aW1lIHNsb3BlIGNhbiB2YXJ5IGFzIGEgZnVuY3Rpb24gb2YgdGhlIHN1YmplY3QsIGJ1dCBpdCB0cmVhdHMgdGhlIHZhcmlhbmNlIGJldHdlZW4gc29jaWFsIGFuZCB0aW1lIGFzICoqaW5kZXBlbmRlbnQqKg0KDQpgYGB7cn0NCk1vZGVsLjQ8LWxtZXIoSGFwcHlQZXJjZW50IH5Tb2NpYWwqVGltZVN0ZXANCiAgICAgICAgICAgICAgICAgICArKDErU29jaWFsfFN1YmplY3QpKygwK1RpbWVTdGVwfFN1YmplY3QpLCAgDQogICAgICAgICAgICAgICAgICAgZGF0YT1IYXBweURhdGEsIFJFTUw9RkFMU0UpDQpzdW1tYXJ5KE1vZGVsLjQsIGNvcnJlbGF0aW9ucz1GQUxTRSkNCnJhbmVmKE1vZGVsLjQpDQpgYGANCg0KLSBUaGUgJFJeMiQgZm9yIGZpeGVkIGFuZCByYW5kb20NCg0KYGBge3J9DQpyMl9uYWthZ2F3YShNb2RlbC40KQ0KYGBgDQoNCi0gUGxvdCB0aGUgbW9kZWwgcmVzdWx0cw0KDQpgYGB7cn0NCkhhcHB5RGF0YSRNb2RlbC40LmZpdHRlZDwtcHJlZGljdChNb2RlbC40KQ0KRml0dGVkbG1QbG90NCA8LWdncGxvdCgpKw0KICBmYWNldF9ncmlkKFN1YmplY3QgfiBTb2NpYWwsIGxhYmVsbGVyPWxhYmVsX2JvdGgpKw0KICBnZW9tX2xpbmUoZGF0YSA9IEhhcHB5RGF0YSwgYWVzKHggPSBUaW1lU3RlcCwgeSA9TW9kZWwuNC5maXR0ZWQpKSsNCiAgZ2VvbV9wb2ludChkYXRhID0gSGFwcHlEYXRhLCBhZXMoeCA9IFRpbWVTdGVwLCB5ID1IYXBweVBlcmNlbnQsIGdyb3VwPVN1YmplY3QsY29sb3VyID0gU3ViamVjdCksIHNpemU9MykrDQogICMgIGNvb3JkX2NhcnRlc2lhbih5bGltID0gYyguMDMsLjA3NCkpKyANCiAgeGxhYigiVGltZSBTdGVwIikreWxhYigiSGFwcGluZXNzIikNCkZpdHRlZGxtUGxvdDQNCmBgYA0KDQojIyBSYW5kb20gaW50ZXJjZXB0cyBhbmQgc2xvcGVzIGZvciB0aW1lIGFuZCBzb2NpYWwgKGJ1dCBub3QgaW5kZXBlbmRlbnQpIA0KLSBNb2RlbCA1IHRyZWF0cyB0aGF0IHRpbWVzdGVwcyBhbmQgU29jaWFsIGFzIGZyZWUgdG8gdmFyeSBiZXR3ZWVuIFN1YmplY3RzIGJ1dCBhY2NvdW50cyBmb3IgdGhlIGNvcnJlbGF0aW9uIHdpdGhpbiBTdWJqZWN0cyBhY3Jvc3MgdGltZSBhbmQgU29jaWFsDQogICAgLSBgKDErU29jaWFsKyBUaW1lU3RlcHxTdWJqZWN0KWAgbWVhbnMgZWFjaCBzdWJqZWN0IGNhbiBoYXZlIHRoZWlyIGludGVyY2VwdCBhbmQgY2FuIGhhdmUgdGhlaXIgc2xvcGUgb2Ygc29jaWFsIGNvbmRpdGlvbg0KLSBBbHNvLCB0aW1lIHNsb3BlIGNhbiB2YXJ5IGFzIGEgZnVuY3Rpb24gb2YgdGhlIHN1YmplY3QsIGJ1dCBpdCB0cmVhdHMgdGhlIHZhcmlhbmNlIGJldHdlZW4gc29jaWFsIGFuZCB0aW1lIGFzICoqY29ycmVsYXRlZCoqDQoNCmBgYHtyfQ0KTW9kZWwuNTwtbG1lcihIYXBweVBlcmNlbnQgflNvY2lhbCpUaW1lU3RlcA0KICAgICAgICAgICAgICAgICAgICAgICArKDErU29jaWFsK1RpbWVTdGVwfFN1YmplY3QpLCAgDQogICAgICAgICAgICAgICAgICAgICAgIGRhdGE9SGFwcHlEYXRhLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShNb2RlbC41LCBjb3JyZWxhdGlvbnM9RkFMU0UpDQpyYW5lZihNb2RlbC41KQ0KYGBgDQoNCi0gVGhlICRSXjIkIGZvciBmaXhlZCBhbmQgcmFuZG9tDQoNCmBgYHtyfQ0KcjJfbmFrYWdhd2EoTW9kZWwuNSkNCmBgYA0KDQotIFBsb3QgdGhlIG1vZGVsIHJlc3VsdHMNCg0KYGBge3J9DQpIYXBweURhdGEkTW9kZWwuNS5maXR0ZWQ8LXByZWRpY3QoTW9kZWwuNSkNCkZpdHRlZGxtUGxvdDUgPC1nZ3Bsb3QoKSsNCiAgZmFjZXRfZ3JpZChTdWJqZWN0IH4gU29jaWFsLCBsYWJlbGxlcj1sYWJlbF9ib3RoKSsNCiAgZ2VvbV9saW5lKGRhdGEgPSBIYXBweURhdGEsIGFlcyh4ID0gVGltZVN0ZXAsIHkgPU1vZGVsLjUuZml0dGVkKSkrDQogIGdlb21fcG9pbnQoZGF0YSA9IEhhcHB5RGF0YSwgYWVzKHggPSBUaW1lU3RlcCwgeSA9SGFwcHlQZXJjZW50LCBncm91cD1TdWJqZWN0LGNvbG91ciA9IFN1YmplY3QpLCBzaXplPTMpKw0KICAjICBjb29yZF9jYXJ0ZXNpYW4oeWxpbSA9IGMoLjAzLC4wNzQpKSsgDQogIHhsYWIoIlRpbWUgU3RlcCIpK3lsYWIoIkhhcHBpbmVzcyIpDQpGaXR0ZWRsbVBsb3Q1DQpgYGANCg0KDQojIyBSYW5kb20gaW50ZXJjZXB0cyBhbmQgc2xvcGVzIGZvciB0aW1lIHggc29jaWFsDQotIE1vZGVsIDYgdHJlYXRzIHRoYXQgdGltZXN0ZXBzLCBTb2NpYWwgYW5kIHRpbWVzdGVwczpTb2NpYWwgKGludGVyYWN0aW9uKSBhcyBmcmVlIHRvIHZhcnkgYmV0d2VlbiBTdWJqZWN0cyBidXQgYWNjb3VudHMgZm9yIHRoZSBjb3JyZWxhdGlvbiB3aXRoaW4gU3ViamVjdHMgYWNyb3NzIHRpbWUgYW5kIFNvY2lhbA0KICAgIC0gYCgxK1NvY2lhbCpUaW1lU3RlcHxTdWJqZWN0KWAgbWVhbnMgYCgxK1NvY2lhbCtUaW1lU3RlcCtTb2NpYWw6VGltZVN0ZXB8U3ViamVjdClgIGVhY2ggc3ViamVjdCBjYW4gaGF2ZSB0aGVpciBpbnRlcmNlcHQsIHRoZWlyIHNsb3BlIG9mIHNvY2lhbCBjb25kaXRpb24sIHRoZWlyIHRpbWUgc2xvcGUsIGFuZCB0aGVpciBpbnRlcmFjdGlvbiBiZXR3ZWVuIHNvY2lhbCBhbmQgdGltZQ0KLSBBbHNvLCBhbGwgcmFuZG9tIHNsb3BlcyBhbmQgaW50ZXJjZXB0cyBjYW4gYmUgKipjb3JyZWxhdGVkKioNCi0gVGhpcyBpcyBjYWxsZWQgdGhlICptYXhpbXVtIG1vZGVsKiBCYXJyIGV0IGFsLiwgMjAxMyAodGhlc2UgZG8gbm90IGFsd2F5cyBmaXQgYmVzdCBzZWUgQmF0ZXMgZXQgYWwuLCAyMDE1KQ0KDQpgYGB7cn0NCk1vZGVsLjY8LWxtZXIoSGFwcHlQZXJjZW50IH5Tb2NpYWwqVGltZVN0ZXANCiAgICAgICAgICAgICAgICAgICArKDErU29jaWFsKlRpbWVTdGVwfFN1YmplY3QpLCAgDQogICAgICAgICAgICAgICAgICAgZGF0YT1IYXBweURhdGEsIFJFTUw9RkFMU0UpDQpzdW1tYXJ5KE1vZGVsLjYsIGNvcnJlbGF0aW9ucz1GQUxTRSkNCnJhbmVmKE1vZGVsLjYpDQpgYGANCg0KLSBUaGUgJFJeMiQgZm9yIGZpeGVkIGFuZCByYW5kb20NCmBgYHtyfQ0KcjJfbmFrYWdhd2EoTW9kZWwuNikNCmBgYA0KDQotIFBsb3QgdGhlIG1vZGVsIHJlc3VsdHMNCg0KYGBge3J9DQpIYXBweURhdGEkTW9kZWwuNi5maXR0ZWQ8LXByZWRpY3QoTW9kZWwuNikNCkZpdHRlZGxtUGxvdDYgPC1nZ3Bsb3QoKSsNCiAgZmFjZXRfZ3JpZChTdWJqZWN0IH4gU29jaWFsLCBsYWJlbGxlcj1sYWJlbF9ib3RoKSsNCiAgZ2VvbV9saW5lKGRhdGEgPSBIYXBweURhdGEsIGFlcyh4ID0gVGltZVN0ZXAsIHkgPU1vZGVsLjYuZml0dGVkKSkrDQogIGdlb21fcG9pbnQoZGF0YSA9IEhhcHB5RGF0YSwgYWVzKHggPSBUaW1lU3RlcCwgeSA9SGFwcHlQZXJjZW50LCBncm91cD1TdWJqZWN0LGNvbG91ciA9IFN1YmplY3QpLCBzaXplPTMpKw0KICAjICBjb29yZF9jYXJ0ZXNpYW4oeWxpbSA9IGMoLjAzLC4wNzQpKSsgDQogIHhsYWIoIlRpbWUgU3RlcCIpK3lsYWIoIkhhcHBpbmVzcyIpDQpGaXR0ZWRsbVBsb3Q2DQpgYGANCg0KIyMgSG93IHRvIHNlbGVjdCBhIHJhbmRvbSBzdHJ1Y3R1cmUNCi0gRmlyc3QsIHRoZXNlIG1vZGVscyBvZnRlbiBmYWlsIHRvIGNvbnZlcmdlDQotIENvbnZlcmdlbmNlIG1lYW4gdGhhdCB0aGUgKipvcHRpbWl6ZXIqKiAobnVtZXJpY2FsIG1ldGhvZCB0byBmaW5kIHRoZSBwYXJhbWV0ZXJzKSBoYXMgZmFpbGVkIHRvIHJlYWNoIGFuIG9wdGltYWwgb3Igc3RhYmxlIHNvbHV0aW9uDQogICAgLSBUaGVyZSBhcmUgbWFueSBvcHRpbWl6ZXJzIHRvIHNlbGVjdCBmcm9tIGluIFIgaWYgeW91IG5lZWQgdG8gY2hhbmdlIGl0IChodHRwczovL3JzdHVkaW8tcHVicy1zdGF0aWMuczMuYW1hem9uYXdzLmNvbS8zMzY1M181N2ZjN2I4ZTVkNDg0YzkwOWI2MTVkODYzM2MwMWQ1MS5odG1sKQ0KLSBGYWlsdXJlcyBtaWdodCBub3QganVzdCBiZSBhIG51bWVyaWNhbCBvcHRpbWl6YXRpb24gcHJvYmxlbSwgYnV0IGEgcHJvYmxlbSB3aXRoIHlvdXIgc3BlY2lmaWNhdGlvbiBvZiB0aGUgcmFuZG9tIGVmZmVjdHMgDQotIFlvdSBjb3VsZCBvdmVyLXNwZWNpZnkgeW91ciByYW5kb20gZWZmZWN0cyBpbiBhIHdheSB0aGF0IGlzIG5vdCAqcGFyc2ltb25pb3VzKiB3aXRoIHRoZSB0cnVlIHJhbmRvbSBlZmZlY3RzIGluIHRoZSBwb3B1bGF0aW9uDQogICAgLSBZb3UgY291bGQgc2V0IHRoZW0gdXAgaW4gc3VjaCBhIHdheSB0aGF0IGRvIG5vdCByZWZsZWN0IHRoZSBleHBlcmltZW50IA0KDQojIyMgUHJhY3RpY2FsIFNvbHV0aW9uIHRvIHJhbmRvbSBzdHJ1Y3R1cmUNCi0gVGhpcyBpcyBhIGJhdHRsZWZpZWxkIGluIExNTQ0KLSBUaGUgY3VycmVudCBiZXN0IHByYWN0aWNlIGlzIHRvIHRyeSB0byBtYXRjaCB5b3VyIGRlc2lnbiBhcyBiZXN0IGFzIHlvdSBjYW4NCiAgICAtIElmIHRoYXQgZmFpbHMsIHRyeSBkaWZmZXJlbnQgb3B0aW1pemVyDQogICAgLSBJZiB0aGF0IGZhaWxzLCByZWR1Y2UgdGhlIGNvbXBsZXhpdHkgb2YgdGhlIHJhbmRvbSBlZmZlY3QgKHJlbW92ZSByYW5kb20gY29ycmVsYXRpb25zIG9uZSBhdCBhIHRpbWUpDQogICAgLSBJZiB0aGF0IGZhaWxzLCBmb2xsb3cgdGhlIHNldCBvZiBwcm9jZWR1cmVzIGhlcmU6IGh0dHA6Ly93d3cuYWxleGFuZGVyZGVtb3Mub3JnL01peGVkOC5odG1sDQotIElmIHlvdSB1bmRlci1zcGVjaWZ5LCB5b3UgaW5mbGF0ZSB5b3VyIHR5cGUgSSBlcnJvciwgc28gaXQgYSBiYWxhbmNpbmcgYWN0DQoNCg0KIyBGaXhlZCBlZmZlY3RzDQotIEp1c3QgbGlrZSB5b3VyIGxpbmVhciByZWdyZXNzaW9uIHlvdSBjYW4gcnVuIHRoZXNlIG1vZGVscyBoaWVyYXJjaGljYWxseSwgb25jZSB0aGUgcmFuZG9tIGVmZmVjdHMgYXJlIGluIHBsYWNlDQotIHlvdSBqdXN0IHRlc3QgYmV0d2VlbiBtb2RlbCBmaXRzIHVzaW5nIGEgZGV2aWFuY2UgdGVzdCAobGlrZSB3ZSBkaWQgd2l0aCBHTE0pIGBhbm92YShtb2RlbC4xLCBtb2RlbC4yKWANCg0KIyMgUGxvdCB0aGUgZmluYWwgbW9kZWwgY29ycmVjdGx5DQotIFRoZSBtZXRob2QgSSB1c2VkIHdhcyB0byBwcmVkaWN0IHRoZSBkYXRhLCBidXQgdGhhdCB3b3JrcyB3ZWxsIGlmIHlvdSBoYXZlIG5vIGNvdmFyaWF0ZXMgb3IgYSBiYWxhbmNlZCBkZXNpZ24NCi0gSWYgeW91IGhhdmUgY292YXJpYXRlcywgaXRzIGJlc3QgdG8gdXNlIHRoZSBlZmZlY3RzIHBhY2thZ2UganVzdCBsaWtlIHdlIGRpZCB3aXRoIGxpbmVhciByZWdyZXNzaW9uDQogICAgLSBBbHNvIHlvdSBoYXZlIHRvIGRlY2lkZSB0byBwbG90IGJvdGggZml4ZWQgKyByYW5kb20gb3IganVzdCB0aGUgZml4ZWQgZWZmZWN0cw0KLSBNb3N0IHBlb3BsZSBvbmx5IHBsb3QgdGhlIGZpeGVkIGVmZmVjdCwgYXMgdGhleSB3YW50IHRvIGNvbnRyb2wgZm9yIHRoZSByYW5kb20gZWZmZWN0cyANCi0gSG93ZXZlciwgaWYgc29tZW9uZSBhc2tzIHlvdSB0byBwbG90IHRoZSBkYXRhIGFuZCB0aGUgbW9kZWwgZml0cyB0b2dldGhlciwgeW91IHdpbGwgbmVlZCB0byB0ZWxsIHRoZW0gaXQgY29tcGxpY2F0ZWQgYXMgd2Ugc2F3IGxhc3Qgd2Vlay4gDQotIEJlbG93IGlzIGhvdyB0byBwbG90IGZpeGVkIG9ubHkgDQoNCmBgYHtyLGZpZy5oZWlnaHQ9NCxmaWcud2lkdGg9NH0NCmxpYnJhcnkoZWZmZWN0cykNCkZpbmFsLkZpeGVkPC1lZmZlY3QoYygiU29jaWFsKlRpbWVTdGVwIiksIE1vZGVsLjYsDQogICAgICAgICAgICAgICAgICAgICAgICAgICB4bGV2ZWxzPWxpc3QoVGltZVN0ZXA9c2VxKDAsNCwxKSkpDQoNCiMgWW91IGhhdmUgdG8gY29udmVydCB0aGUgb3V0cHV0IHRvIGEgZGF0YWZyYW1lDQpGaW5hbC5GaXhlZDwtYXMuZGF0YS5mcmFtZShGaW5hbC5GaXhlZCkNCg0KRmluYWwuRml4ZWQuUGxvdCA8LWdncGxvdChkYXRhID0gRmluYWwuRml4ZWQsIGFlcyh4ID0gVGltZVN0ZXAsIHkgPWZpdCwgZ3JvdXA9U29jaWFsKSkrDQogIGNvb3JkX2NhcnRlc2lhbih4bGltPWMoMCw0KSx5bGltID0gYygwLC43KSkrIA0KICBnZW9tX2xpbmUoYWVzKGNvbG9yPVNvY2lhbCksIHNpemU9MikrDQogIGdlb21fcmliYm9uKGFlcyh5bWluPWZpdC1zZSwgeW1heD1maXQrc2UsZmlsbD1Tb2NpYWwpLGFscGhhPS4yKSsNCiAgeGxhYigiVGltZSIpKw0KICB5bGFiKCJIYXBwaW5lc3NcbnNjb3JlIikrDQogIHNjYWxlX2NvbG9yX21hbnVhbCh2YWx1ZXM9YygiYmx1ZSIsICJyZWQiKSkrDQogIHNjYWxlX2ZpbGxfbWFudWFsKHZhbHVlcz1jKCJibHVlIiwgInJlZCIpKSsNCiAgdGhlbWVfYncoKSsNCiAgdGhlbWUodGV4dD1lbGVtZW50X3RleHQoZmFjZT0iYm9sZCIsIHNpemU9MTIpLA0KICAgICAgICBwYW5lbC5ncmlkLm1ham9yID0gZWxlbWVudF9ibGFuaygpLCANCiAgICAgICAgcGFuZWwuZ3JpZC5taW5vciA9IGVsZW1lbnRfYmxhbmsoKSwgDQogICAgICAgIHBhbmVsLmJvcmRlciA9IGVsZW1lbnRfcmVjdChmaWxsID0gTkEsIGNvbG91ciA9ICJOQSIpLA0KICAgICAgICBheGlzLmxpbmUgPSBlbGVtZW50X2xpbmUoc2l6ZSA9IDEsIGNvbG91ciA9ICJncmV5ODAiKSwNCiAgICAgICAgbGVnZW5kLnRpdGxlPWVsZW1lbnRfYmxhbmsoKSwNCiAgICAgICAgbGVnZW5kLnBvc2l0aW9uID0gYyguMiwgLjkyKSkNCkZpbmFsLkZpeGVkLlBsb3QNCmBgYA0KDQojIFByb2JsZW0gd2l0aCBQLXZhbHVlcw0KLSBXaGF0IGdpdmVzIG1peGVkLWVmZmVjdHMgbW9kZWxzIHRoZWlyIGFiaWxpdHkgdG8gaGFuZGxlIGNvbXBsZXggZGVzaWducyAoZS5nLiwgbmVzdGVkLCBjcm9zc2VkLCBuZXN0ZWQgJiBjcm9zc2VkLCBwYXJ0aWFsbHkgbmVzdGVkIGFuZCBjcm9zc2VkKSBpcyBpbiBwYXJ0IHdoYXQgZG9lcyBub3QgYWxsb3cgdGhlbSB0byBjYWxjdWxhdGUgcC12YWx1ZXMNCi0gUmVtZW1iZXIsICR0ID0gXGZyYWN7TS1cbXV9e1NFfSQsIHdoZXJlLCAkU0UgPSBcc3FydFxmcmFje1xzaWdtYV4yfXtufSQsICRkZiA9IG4tMSQNCi0gR0xNIHVzZXMgc3RhbmRhcmQgZXJyb3IgdG8gZGV0ZXJtaW5lIHNpZ25pZmljYW5jZTogUmVxdWlyZWQgZGVncmVlcyBvZiBmcmVlZG9tIHRvIGNvcnJlY3Qgei1kaXN0cmlidXRpb24gZm9yICJzYW1wbGluZyBlcnJvciIgdG8gcHJvZHVjZSAkdCQgYW5kICRGJCB0YWJsZXMuICANCi0gQnV0IG1peGVkIG1vZGVscyBkbyBub3QgYWN0dWFsbHkgcHJvZHVjZSAkdCQgb3IgJHReMj1GJCB2YWx1ZXMgYXMgdGhleSBhcmUgbm90IGNhbGN1bGF0aW5nIHRoZSAkU0UkIHVzaW5nIHRoZSBlcXVhdGlvbiBhYm92ZSwgd2hpY2ggdXNlcyBvYnNlcnZlZCAtIGV4cGVjdGVkIFttZWFuIHNxdWFyZSA9ICRcc2lnbWFeMiA9IFxmcmFje1NTfXtOLTF9JCwgd2hlcmUgJFNTID0gKE0tXG11KV4yJA0KLSBJbnN0ZWFkLCB0aGV5IGVzdGltYXRlIHRoZSAkU0UkIHVzaW5nIE1MIG9yIFJFTUwgZnVuY3Rpb24NCi0gTUwgaXMgYSB3YXkgb2YgZmluZGluZyB0aGUgdmFsdWUgb2Ygb25lIG9yIG1vcmUgcGFyYW1ldGVycyBpbiBtaXhlZCBtb2RlbCBmb3IgYSBnaXZlbiBzdGF0aXN0aWMgd2hpY2ggbWFrZXMgdGhlIGtub3duICpsaWtlbGlob29kKiBkaXN0cmlidXRpb24gYSAqbWF4aW11bSoNCiAgICAtICpsaWtlbGlob29kKiBpcyAiYSBoeXBvdGhldGljYWwgcHJvYmFiaWxpdHkgdGhhdCBhbiBldmVudCB0aGF0IGhhcyAqKmFscmVhZHkqKiBvY2N1cnJlZCB3b3VsZCB5aWVsZCBhIHNwZWNpZmljIG91dGNvbWUiIChodHRwOi8vbWF0aHdvcmxkLndvbGZyYW0uY29tL0xpa2VsaWhvb2QuaHRtbCkNCiAgICAtICptYXhpbXVtKiBpcyB0aGUgbGFyZ2VzdCB2YWx1ZSB0aGUgZnVuY3Rpb24gY2FuIHByb2R1Y2UNCiAgICAtIFdlIHdpbGwgaXRlcmF0ZSB0aHJvdWdoIHBhcmFtZXRlcnMgdW50aWwgd2UgbWF4aW1pemUgb3VyIGxpa2VsaWhvb2QNCiAgICAtIFRoZXJlIGFyZSBkaWZmZXJlbnQgTUwgKG9yIGp1c3QgTCkgZnVuY3Rpb25zIHRoYXQgY2FuIGJlIHVzZWQgYW5kIHRoZXkgY2FuIGFwcGx5IHRvIG1vc3QgZGlzdHJpYnV0aW9ucw0KLSAqKlByb2JsZW0gMToqKiBTRSBpcyBub3QgdGhlIG9uZSB1c2VkIGluICR0JCBhbmQgJEYkIChpdCBkb2VzIG5vdCB1c2UgTikNCi0gKipQcm9ibGVtIDI6KiogVGhlIGVzdGltYXRlIHdlIGdldCBpcyBub3QgdmlhIE9MUyBlaXRoZXIsIGl0J3MgdmlhIE1MIG9yIFJFTUwgKHNvIHdoYXQgaXMgdGhlIHByb3BlciBkaXN0cmlidXRpb24gdG8gdGVzdCBhZ2FpbnN0PykNCi0gKipQcm9ibGVtIDM6KiogV2hhdCBpcyBvdXIgJERGJCBldmVuIGlmIHdlIHdhbnQgdG8gYXNzdW1lICR0JCBhbmQgJEYkPw0KDQojIyBQcm9ibGVtIDM6IERGIENvbmNlcHR1YWwgSXNzdWVzDQotIFNhbXBsZSA1MDAsIDExdGhlIGdyYWRlcnMgdGFrZSB0aGUgU0FUIGZyb20gMyBzY2hvb2xzIHBhcnRpYWxseSBuZXN0ZWQgaW4gMiBlY29ub21pYyBkaXN0cmljdHMgIA0KDQpgYGB7ciwgZWNobyA9IEZBTFNFLCBvdXQud2lkdGggPSAiMzAwcHgifQ0Ka25pdHI6OmluY2x1ZGVfZ3JhcGhpY3MoIk1peGVkL1Zlbm5TY2hvb2xzLmpwZyIpDQpgYGANCg0KDQotIFJhbmRvbSBzYW1wbGluZyBvZiA1MDAgdG90YWwgZnJvbSAzIHNjaG9vbHMgW05vdGU6IHNjaG9vbCAzIGlzIHR3aWNlIGFzIGxhcmdlIHNjaG9vbCAxIGFuZCAyXSANCi0gQU5PVkEgRGVzaWduOiAxIGZhY3RvcjogU2Nob29sIE9SIGRpc3RyaWN0IFt0aGV5IHByb3ZpZGUgYW4gdW5iYWxhbmNlZCBkZXNpZ24gc28gdGhleSBjYW4gb25seSBiZSBhbmFseXplZCBvbmUgYXQgdGltZV0NCi0gQXNzdW1lIGhvbW9nZW5laXR5IG9mIHZhcmlhbmNlIG9mIFNBVCBzY29yZSBhY3Jvc3Mgc2Nob29scyBhbmQgZGlzdHJpY3RzDQotIEFOT1ZBIGNhbiBvbmx5IGFzayAxIGJhc2ljIHF1ZXN0aW9uOiBBcmUgdGhlIG1lYW5zIGJldHdlZW4gdGhlIHNjaG9vbHMgb3IgZGlzdHJpY3RzIGRpZmZlcmVudA0KDQojIyMgQU5PVkEgcHJvYmxlbT8NCi0gV2h5IGlzIEFOT1ZBIGJhZCBoZXJlPyANCiAgICAtIFNjaG9vbCAxIGlzIHByZWRvbWluYXRlbHkgcG9vciB2cyBTY2hvb2wgMiwgd2hpY2ggaXMgcmljaCwgc28gc2Nob29sIDEgaGFzIGxlc3MgZnVuZGluZywgbGFyZ2VyIGNsYXNzcm9vbXMgc2l6ZXMsIG1vcmUgc29jaWFsIGlzc3VlcyBhdCBob21lIGFuZCBpbiBzY2hvb2wsIGZld2VyIHRlYWNoZXJzLCBldGMuIA0KLSBUaGlzIGNvdWxkIGltcGFjdCBib3RoIG1lYW4gdGVzdCBzY29yZXMgYW5kIHZhcmlhbmNlIG9mIHRlc3Qgc2NvcmVzICANCiAgICAtIFN0dWRlbnRzIGZyb20gdGhlIHBvb3IgZGlzdHJpY3QgbWlnaHQgaGF2ZSBtb3JlIGRpdmVyc2Ugc2NvcmVzIFtoaWdoIHZhcmlhbmNlXQ0KICAgIC0gU3R1ZGVudCBmcm9tIHJpY2ggZGlzdHJpY3QgbWlnaHQgaGF2ZSBtb3JlIHNpbWlsYXIgc2NvcmVzLCBidXQgaGlnaGVyIGF2ZXJhZ2Ugc2NvcmVzIFtsb3cgdmFyaWFuY2VdDQogICAgLSBQb29yIHN0dWRlbnRzIGluIHRoZSBSaWNoIHNjaG9vbCBtaWdodCBhbHNvIGhhdmUgY2hhbmdlcyBpbiB2YXJpYW5jZSBvciBtZWFuIHRlc3Qgc2NvcmVzLCB3aGljaCBsb29rIHZlcnkgZGlmZmVyZW50IGZyb20gdGhlIHBvb3Igb3IgbWl4ZWQgc2Nob29sLiAgDQoNCiMjIyBNaXhlZCB2cy4gQU5PVkEgU29sdXRpb24NCg0KIyMjIyBBTk9WQSBMb2dpYw0KDQotIElmIHdlIGFzc3VtZSBBTk9WQSB0aGF0IHdvdWxkIG1lYW4gd2UgY2FsY3VsYXRlIG1lYW4vdmFyaWFuY2UgcmVsYXRpdmUgdG8gdGhlaXIgY2xhc3NpZmljYXRpb24gYmFzZWQgb24gc2Nob29sIGFuZCBkaXN0cmljdCBbYXQgdGhlIGxldmVsIHdlIGFyZSBleGFtaW5pbmcgb25seV0gDQotIEluIHRoZSBjYXNlIHdoZW4gYWxsIHRoZSB2YXJpYWJsZXMgYXJlIGNhdGVnb3JpY2FsLCB0aGUgREYgInNlZW1zIiBsb2dpY2FsLCBpbiB0aGF0IHRoZSBwcm9wZXIgTVNlcnJvciB0ZXJtcyBjb3VsZCBiZSBjYWxjdWxhdGVkLiBIb3dldmVyLCBpbiB0aGUgbWl4ZWQgbW9kZWxzLCB0aGUgcmFuZG9tIGZhY3RvcnMgaGF2ZSBiZWVuIG5lc3RlZCAoa2lkcyBpbiBzY2hvb2xzIGluIGRpc3RyaWN0cykuIA0KICAgIC0gU28gd2UgY2Fubm90IGtub3cgaG93IG1hbnkgb2YgdGhlIHBlb3BsZSB3ZW50IGludG8gcGFyc2luZyB0aGUgdmFyaWFuY2UgZm9yIGVhY2ggbGV2ZWwgb2YgdGhlIHJhbmRvbSBlcnJvciB0ZXJtLiAgDQogICAgICAgIC0gV2UgY291bGQgbWFrZSBhc3N1bXB0aW9ucywgYnV0IHNvbWUgc3RhdGlzdGljaWFucyBzYXkgb3ZlciB0aGVpciBkZWFkIGJvZGllcy4gDQogICAgLSBBTk9WQSBpcyBhc3N1bWVkIHRvIGJlIHJvYnVzdCBhZ2FpbnN0IG1hbnkgdmlvbGF0aW9ucywgYnV0IHRoYXQncyBtb3N0bHkgb25seSB0cnVlIGluIHdlbGwtY29udHJvbGxlZCBiYWxhbmNlZCBkZXNpZ25zLg0KICAgIC0gV2hlbiBBTk9WQSBpcyBzdHJldGNoZWQgaW50byB0aGUgbWl4ZWQgbW9kZWwgdGVycml0b3J5LCBpdCBjYW4gcmVzdWx0IGluIHVucmVhc29uYWJsZSBsZXZlbHMgb2YgdHlwZSAxIGVycm9yLiAgDQogICAgDQojIyMjIE1peGVkIExvZ2ljDQoNCi0gMS4gRml4ZWQgZmFjdG9yczogIFNjaG9vbCBhbmQgRGlzdHJpY3QgW3N0dWRlbnQgYmVsb25ncyB0b10NCiAgICAtIFNBVCBzY29yZSBNRUFOUyBjb3VsZCBiZSBkaWZmZXJlbnQgZGVwZW5kaW5nIG9uIHRoZSBzY2hvb2wgYSBraWQgZ29lcyB0byBhbmQgd2hhdCBkaXN0cmljdCB0aGV5IGFyZSBmcm9tLiAgIA0KLSAyLiBSYW5kb20gRmFjdG9yczogIERpc3RyaWN0LCBTY2hvb2wsIFtTdHVkZW50XQ0KICAgIC0gU0FUIHNjb3JlIFZBUklBTkNFUyBjb3VsZCBiZSBkaWZmZXJlbnQgZGVwZW5kaW5nIG9uIHRoZSBzY2hvb2wgYSBraWQgZ29lcyB0byBhbmQgd2hhdCBkaXN0cmljdCB0aGV5IGFyZSBmcm9tLiAgIA0KICAgIC0gU28gYXJlIHRoZSBraWRzIHRoZSBERiwgb3IgdGhlIFNjaG9vbCBvciB0aGUgZGlzdHJpY3Q/IFdoYXQgZG8gd2l0aCBraWRzIHdobyBhcmUgbWlzbWF0Y2hlZCAocG9vciBidXQgaW4gcmljaGVyIHNjaG9vbHMgb3IgdmljZSB2ZXJzYT8pDQotIDMuIFJhbmRvbSBTbG9wZXM6IFRoZSBpbXBhY3Qgb2YgU0VTIGNvdWxkIGJlIGRpZmZlcmVudCBkZXBlbmRpbmcgb24gdGhlIHNjaG9vbCBhIGtpZCBnb2VzIHRvIGFuZCB3aGF0IGRpc3RyaWN0IHRoZXkgYXJlIGZyb20sDQogICAgLSBJbiB0aGUgcmljaCBzY2hvb2wsIHRoZSBTRVMgb2YgdGhlIHN0dWRlbnQgbWlnaHQgbm90IG1hdHRlciBhcyBtdWNoIGFzIHRoZSBwb29yIG9yIG1peGVkIHNjaG9vbCANCiAgICAgICAgLSBXaGVuIHdlIGFkZCByYW5kb20gc2xvcGVzLCBob3cgbWFueSBtZWFzdXJlbWVudHMgb2YgdGhlIGVmZmVjdCBvZiBTRVMgYXJlIHdlIG1ha2luZyAtIGlzIGl0IGJhc2VkIG9uIHRoZSBudW1iZXIgb2Ygc3R1ZGVudHMsIHNjaG9vbHMgb3IgZGlzdHJpY3RzPw0KLSBXaGljaCBsZXZlbCBkbyB3ZSBjb3VudCB0aGUgZGVncmVlcyBvZiBmcmVlZG9tIGZvciBlYWNoIGZpeGVkIGFuZCByYW5kb20gZmFjdG9yPyBTdHVkZW50cywgc2Nob29scywgb3IgZGlzdHJpY3RzPyBIb3cgZG8gd2UgY291bnQgREYgZm9yIHJhbmRvbSBmYWN0b3JzPyAgDQoNCiMgR2V0dGluZyBQLXZhbHVlcw0KIyMgUGF0aCBBOiBEb24ndCBwdXNoIHlvdXIgYXNzdW1wdGlvbnMgb24gbWUhDQoNCjEuICBNb2RlbGluZyBGaXR0aW5nIHRlc3RpbmcgDQotIExpa2VsaWhvb2QgcmF0aW8gdGVzdCBbY2hpLXNxdWFyZSBkaXN0cmlidXRpb25dDQotIEQgPSAyIC0gbG4gKExpa2VsaWhvb2Qgb2YgbnVsbCBtb2RlbCAvIExpa2VsaWhvb2Qgb2YgYWx0ZXJuYXRpdmUgbW9kZWxdIA0KLSBBZGQvUmVtb3ZlIGZpeGVkIGZhY3RvcnMgYW5kIHRlc3QgdG8gc2VlIGlmIHRoZSBtb2RlbCAiZml0cyB0aGUgZGF0YSBiZXR0ZXIiIA0KLSBTdWdnZXN0ZWQgYnkgQmF0ZXMgYW5kIEJvbGtlcg0KLSBGQVNUIGFuZCB3ZWxsLWFjY2VwdGVkIFthIGJpdCBhbnRpLWNvbnNlcnZhdGl2ZSBzb21lIGFyZ3VlXQ0KICAgIC0gVG8gZG8gdGhpcywgeW91IHNpbXBseSBoYXZlIHRvIGBhbm92YShtb2RlbC4xLCBtb2RlbC4yKWANCiAgICANCg0KMi4gQm9vdHN0cmFwcGluZyANCi0gTm9uLXBhcmFtZXRyaWM6IFJlLXNhbXBsaW5nIG1ldGhvZCB3aGVyZSB5b3UgcmVzYW1wbGUgd2l0aCByZXBsYWNlbWVudCBmcm9tIHlvdXIgb3duIGRhdGEgICAgIA0KICAgIC0gQ29tbW9uIG1ldGhvZCBpbiBtb2Rlcm4gc3RhdHM6IEEgbXVjaCBiZXR0ZXIgbWV0aG9kIHRoZW4gYXNzdW1pbmcgbm9ybWFsaXR5IGFuZCB0LWRpc3RyaWJ1dGlvbnMgDQogICAgLSBFeGFtcGxlOiBZb3UgYnVpbGQgeW91ciBmaW5hbCBtb2RlbCBhbmQgeW91IHRoZW4gdGFrZSB0aGUgc3ViamVjdHMsIHJlc2FtcGxlIHRoZW0gd2l0aCByZXBsYWNlbWVudCwgYW5kIHJlZml0IHlvdXIgbW9kZWwNCiAgICAgICAgLSBZb3UgZG8gdGhpcyBvdmVyIGFuZCBvdmVyIGFnYWluIHRvIGJ1aWxkIGEgZGlzdHJpYnV0aW9uIGZvciBlYWNoIHBhcmFtZXRlciBpbiB5b3VyIG1vZGVsDQogICAgICAgICAgICAtIFlvdSB0aGFuIGNhbGN1bGF0ZSB0aGUgOTV0aCBwZXJjZW50aWxlIGFuZCBzZWUgaWYgY29udGFpbnMgemVybywgaWYgbm90IHlvdSBoYXZlIGEgKnNpZ25pZmljYW50KiBlZmZlY3QgDQotIFNlbWktcGFyYW1ldHJpYzogQWRkcyBub2lzZSB0byB0aGUgTm9uLXBhcmFtZXRyaWMgKGFzc3VtZXMgeW91ciBtZWFzdXJlbWVudHMgYXJlIHJhbmRvbWx5IHNhbXBsZWQgZnJvbSBhbGwgcG9zc2libGUgbWVhc3VyZW1lbnRzKQ0KICAgIC0gU28geW91IHNhbXBsZSBmcm9tIHlvdXIgZGF0YSwgYWRkIHBhcmFtZXRyaWMgbm9pc2UsIHJpbnNlIGFuZCByZXBlYXQgbGlrZSBhYm92ZQ0KLSBQYXJhbWV0cmljOiBZb3UgYXNzdW1lIHlvdXIgZGF0YSBmb2xsb3dzIGEgc3BlY2lmaWMgZGlzdHJpYnV0aW9uLCB5b3UgdXNlIHlvdXIgbW9kZWwgdG8gZXN0aW1hdGUgdGhlIHBhcmFtZXRlcnMsIGFuZCB0aGVuIHlvdSBzaW11bGF0ZSB0aGUgc3R1ZHkgYmFzZWQgb24gdGhvc2UgcGFyYW1ldGVycyB0byBlc3RpbWF0ZSB0aGUgQ0kuIFlvdSB0aGFuIGNhbGN1bGF0ZSB0aGUgOTV0aCBwZXJjZW50aWxlIGFuZCBzZWUgaWYgaXQgY29udGFpbnMgemVyby4NCi0gU28gZmFyIHdlIGNhbiBvbmx5IGRvIFNlbWktcGFyYW1ldHJpYyAmIFBhcmFtZXRyaWMgYmVjYXVzZSBvZiB0aGUgcmFuZG9tIGVmZmVjdHMNCiAgICAtIEhvd2V2ZXIsICBTZW1pLXBhcmFtZXRyaWMgaXMgbm90IGZ1bGx5IGltcGxlbWVudGVkIHlldCANCi0gVkVSWSwgVkVSWSBTTE9XLg0KLSBUaGlzIHByb2NlZHVyZSBjYW4gZmFpbCBiZWNhdXNlIHlvdXIgbW9kZWwgaXMgdW5zdGFibGUgKHByb2JhYmx5IG1lYW5zIHlvdXIgbW9kZWwgaXMgYmFkIGFueXdheSkNCi0gWW91IGNhbiBhbHNvIGJvb3RzdHJhcCBNb2RlbCBmaXQgdGVzdGluZyAoOTV0aCBwZXJjZW50aWxlIG1ldGhvZCkNCg0KYGBge3J9DQojIHBhcmFtZXRyaWMNCk1vZGVsLkZpbmFsLkNJLmJvb3QgPC0gY29uZmludChNb2RlbC42LCBtZXRob2Q9ImJvb3QiLG5zaW09MTAwLGJvb3QudHlwZSA9IGMoInBlcmMiKSkgDQpNb2RlbC5GaW5hbC5DSS5ib290DQoNCmBgYA0KDQojIyBQYXRoIEI6ICBMZXQncyBob2xkIGhhbmRzLCBwdXQgb3VyIGZpbmdlcnMgaW4gb3VyIGVhcnMsIGFuZCBhc3N1bWUhIA0KDQozLiBBc3N1bWUgeiBkaXN0cmlidXRpb25zIHRvIGdldCBwLXZhbHVlcw0KLSBWZXJ5LCB2ZXJ5IGNvbW1vbiBhcHByb2FjaA0KLSBJZiB5b3UgbnVtYmVyIG9mIG9ic2VydmF0aW9ucyBpcyBoaWdoLCBqdXN0IGFzc3VtZSBERiAtPiBpbmYgW3NvICR0ID4gfDJ8JCwgaXMgc2lnbmlmaWNhbnRdDQogICAgLSBUaGlzIGlzIHBvc3NpYmxlIGJlY2F1c2UgeW91IGFzc3VtZSB5b3VyIHJhbmRvbSBlZmZlY3RzIGhhdmUgY29udHJvbGxlZCBmb3IgdGhlIHJhbmRvbSB2YXJpYXRpb25zIGluIHRoZSBwb3B1bGF0aW9ucyBhbmQgeW91ciB2YWx1ZXMgZ29vZCBlc3RpbWF0ZXMgb2YgdGhlIHBvcHVsYXRpb24NCi0gU2ltdWxhdGlvbiBzdHVkaWVzIGJ5IEJhcnIgZXQgYWwuIHNob3cgdGhpcyB0byBiZSBhIHJlYXNvbmFibGUgYXNzdW1wdGlvbiBJRiBhbmQgT05MWSBPRiByYW5kb20gc3RydWN0dXJlIGlzIE1BWElNQUwNCiAgICAtIFRoaXMgaXMgSE9UTFkgZGViYXRlZCBieSBCYXRlcw0KDQo0LiBFc3RpbWF0ZSBkZWdyZWVzIG9mIGZyZWVkb20NCi0gU0FTL1NQU1MgdXNlcyBTYXR0ZXJ0aHdhaXRlIGFwcHJveGltYXRpb25zIA0KICAgIC0gSG93ZXZlciwgdGhlcmUgYXJlIGFsc28gS2Vud2FyZC1Sb2dlciBhcHByb3hpbWF0aW9ucyBbc2VlIFdlc3RmYWxsLCBLZW5ueSwgJiBKdWRkLCAyMDE0XQ0KICAgIC0gRWl0aGVyIGlzIGFjY2VwdGFibGUsIGJ1dCBLUiBpcyByZWNvbW1lbmRlZCAoYnV0IGRvZXMgbm90IGFsd2F5cyB3b3JrKSANCi0gTWFrZXMgYSBudW1iZXIgb2YgYXNzdW1wdGlvbnMsIHdpbGwgbWlycm9yIHJlc3VsdHMgb2YgdHJhZGl0aW9uYWwgQU5PVkEgZmFpcmx5IGNsb3NlbHkgW2FzIHlvdSB3b3VsZCBleHBlY3Qgd2hlbiB5b3UgbWFrZSBzaW1pbGFyIGFzc3VtcHRpb25zIGFib3V0IERGXQ0KICAgIC0gVGhpcyBtZXRob2QgY2FuIGFsc28gZmFpbCB0byB3b3JrIGJlY2F1c2UgeW91ciBtb2RlbCBpcyB1bnN0YWJsZS9jb252ZXJnZW5jZSBwcm9ibGVtcw0KDQpbTm90ZTogWW91IGhhdmUgdG8gcmVmaXQgdGhlIG1vZGVsIHdpdGggdGhlIGxtZXJUZXN0IHBhY2thZ2VdDQoNCmBgYHtyfQ0KbGlicmFyeShsbWVyVGVzdCkgI21peGVkIG1vZGVsIGFkZC1vbiBwYWNrYWdlIHRvIA0KTW9kZWwuRmluYWw8LWxtZXIoSGFwcHlQZXJjZW50IH5Tb2NpYWwqVGltZVN0ZXANCiAgICAgICAgICAgICAgICAgICsoMStTb2NpYWwqVGltZVN0ZXB8U3ViamVjdCksICANCiAgICAgICAgICAgICAgICAgIGRhdGE9SGFwcHlEYXRhLCBSRU1MPUZBTFNFKQ0Kc3VtbWFyeShNb2RlbC5GaW5hbCwgZGRmPSJTYXR0ZXJ0aHdhaXRlIikgIyMgU1BTUy9TQVMgbWV0aG9kDQoNCk1vZGVsLkZpbmFsLlJFTUw8LWxtZXIoSGFwcHlQZXJjZW50IH5Tb2NpYWwqVGltZVN0ZXANCiAgICAgICAgICAgICAgICAgICsoMStTb2NpYWwqVGltZVN0ZXB8U3ViamVjdCksICANCiAgICAgICAgICAgICAgICAgIGRhdGE9SGFwcHlEYXRhLCBSRU1MPVRSVUUpDQpzdW1tYXJ5KE1vZGVsLkZpbmFsLlJFTUwsZGRmID0gIktlbndhcmQtUm9nZXIiKSAjIEtlbm5leSBldCBhbCBzdWdnZXN0ZWQgbWV0aG9kDQpgYGANCg0KIyMgUGF0aCBDOiBHbyBCYXllc2lhbg0KLSBUaGVyZSB1c2UgdG8gYmUgYSB3YXkgdG8gZ2V0IHB2YWx1ZXMgYmFzZWQgb24gTWFya292LWNoYWluIE1vbnRlLUNhcmxvIG1ldGhvZHMgKE1DTUMpDQogICAgLSBDdXJyZW50bHkgZG9lcyBub3Qgd29yayBmb3IgbG1lNCBwYWNrYWdlIHdlIGFyZSB1c2luZw0KLSBZb3UgaGF2ZSB0byByZWZpdCB0aGUgbW9kZWwgYXMgQmF5ZXNpYW4gdXNpbmcgYHJzdGFuYXJtYCBhbmQgZ2V0IENJcyAoc2VlIEdlbG1hbiAmIEhpbGwgdGV4dGJvb2spDQogICAgDQojIyMgUHJhY3RpY2FsIHNvbHV0aW9uDQotIFByYWN0aWNhbGx5LCB3aGVuIHlvdSBhZGQgZmFjdG9ycyBpbiBzdGVwd2lzZSBhbmQgbW9kZWwgZml0IHNob3dzIGEgc2lnbmlmaWNhbnQgaW1wcm92ZW1lbnQgKFBhdGggMUEpIHlvdSB3aWxsIHNlZSB0aGUgbmV3IGZhY3RvcnMgaGFzIGEgJHQgPiB8MnwkLiAoUGF0aCAyQSkNCi0gVGhhdCBkb2VzIG5vdCBhbHdheXMgYWdyZWUgd2l0aCBib290c3RyYXBwaW5nIChQYXRoIDFCKSBvciBBTk9WQS1saWtlIGRlZ3JlZXMgb2YgZnJlZWRvbSAoUGF0aCAyQikNCiAgICAtIFRoaXMgaXMgYmVjYXVzZSBMTUU0IHBhY2thZ2Ugd2UgYXJlIHVzaW5nIGRvZXMgbm90IGFsbG93IHVzIHRvIGNvbnRyb2wgZm9yIHRoZSBoZXRlcm9nZW5lb3VzIHZhcmlhbmNlIHByb2JsZW0uIFRoZSBvbGRlciBwYWNrYWdlIExNRSB3aWxsIGFsbG93IHlvdSB0byBjb250cm9sIGZvciBpdC4NCiAgICAgICAgLSBOb3RlIExNRSB1c2VzIFNhdHRlcnRod2FpdGUgYXBwcm94aW1hdGlvbnMgYW5kIHdpbGwgYWx3YXlzIGdpdmUgeW91IERGIGFuZCBwdmFsdWVzDQogICAgLSBBbHNvLCB0aGVyZSBjb3VsZCBiZSBvdGhlciBwcm9ibGVtcyB3aXRoIHlvdXIgYXNzdW1wdGlvbnMgdGhhdCBib290c3RyYXBwaW5nIGlzIHBpY2tpbmcgdXAgb24gdGhlIG90aGVyIHBhdGhzIHdpbGwgbm90IHBpY2sgdXANCi0gKlJlY29tbWVuZGF0aW9uOiogQmFzZWQgb24gY3VycmVudCB0cmVuZHM6DQogICAgMS4gQWx3YXlzIGRvIFBhdGggMUEgdG8gc2F5IHRoZSBtb2RlbCBpcyBiZXR0ZXIgDQogICAgMi4gVG8gdGVzdCB0aGUgcGFyYW1ldGVycywgYWRkIFBhdGggMUIsIFBhdGggMkEgb3IgMkIuDQogICAgICAgIC0gSSB1c3VhbGx5IHBpY2sgMUIgb3IgMkEgDQogICAgICAgIC0gQnV0IHNvbWUgZmllbGRzIG1pZ2h0IGRlbWFuZCBERiwgc28geW91IGhhdmUgdG8gZG8gMkINCg0KIyBNaXhlZCB0byBBTk9WQQ0KLSBJZiB5b3Ugd2FudGVkIHRvIHJlcG9ydCB0aGUgbWFpbiBlZmZlY3RzIGFuZCBpbnRlcmFjdGlvbnMsIGluc3RlYWQgb2Ygc2xvcGVzLCB5b3UgbWlnaHQgY29udmVydCB5b3VyIG1peGVkIG1vZGVsIGludG8gYW4gQU5PVkENCi0gQnV0IHJlbWVtYmVyLCB5b3VyIHNsb3BlcyBvZiB0aW1lIHJldmVydCB0byBiZWluZyBmYWN0b3JzIGFuZCBub3QgY29udGludW91cyB2YXJpYWJsZXMNCg0KYGBge3J9DQphbm92YShNb2RlbC5GaW5hbC5SRU1MLGRkZiA9ICJLZW53YXJkLVJvZ2VyIikgDQpgYGANCg0KPHNjcmlwdD4NCiAgKGZ1bmN0aW9uKGkscyxvLGcscixhLG0pe2lbJ0dvb2dsZUFuYWx5dGljc09iamVjdCddPXI7aVtyXT1pW3JdfHxmdW5jdGlvbigpew0KICAoaVtyXS5xPWlbcl0ucXx8W10pLnB1c2goYXJndW1lbnRzKX0saVtyXS5sPTEqbmV3IERhdGUoKTthPXMuY3JlYXRlRWxlbWVudChvKSwNCiAgbT1zLmdldEVsZW1lbnRzQnlUYWdOYW1lKG8pWzBdO2EuYXN5bmM9MTthLnNyYz1nO20ucGFyZW50Tm9kZS5pbnNlcnRCZWZvcmUoYSxtKQ0KICB9KSh3aW5kb3csZG9jdW1lbnQsJ3NjcmlwdCcsJ2h0dHBzOi8vd3d3Lmdvb2dsZS1hbmFseXRpY3MuY29tL2FuYWx5dGljcy5qcycsJ2dhJyk7DQoNCiAgZ2EoJ2NyZWF0ZScsICdVQS05MDQxNTE2MC0xJywgJ2F1dG8nKTsNCiAgZ2EoJ3NlbmQnLCAncGFnZXZpZXcnKTsNCg0KPC9zY3JpcHQ+DQo=